Welcome to RogerJTX’s Programming Notes
My Main Notes Websites
Host
https://rogerjtx.github.io/
Neural Network [CNN, RNN, GAN]
https://rogerjtx.github.io/neural_network/
Word2Vector [ELMo, Bert, ALBert]
https://rogerjtx.github.io/word2vector/
Topbase Knowledge Graph Paper Reproduction And Technical Documentation
https://rogerjtx.github.io/topbase_knowledge_graph/
Automatic Code Generation [based on GPT-2]
https://rogerjtx.github.io/auto_code_generation/
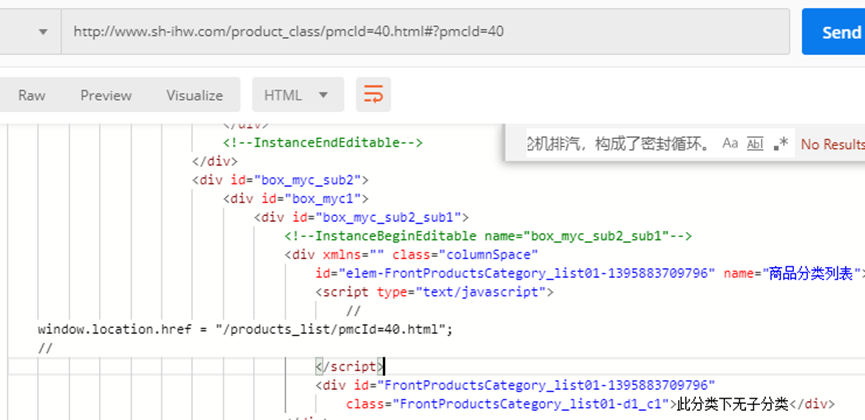
Comelot Table Image Recognition
url:
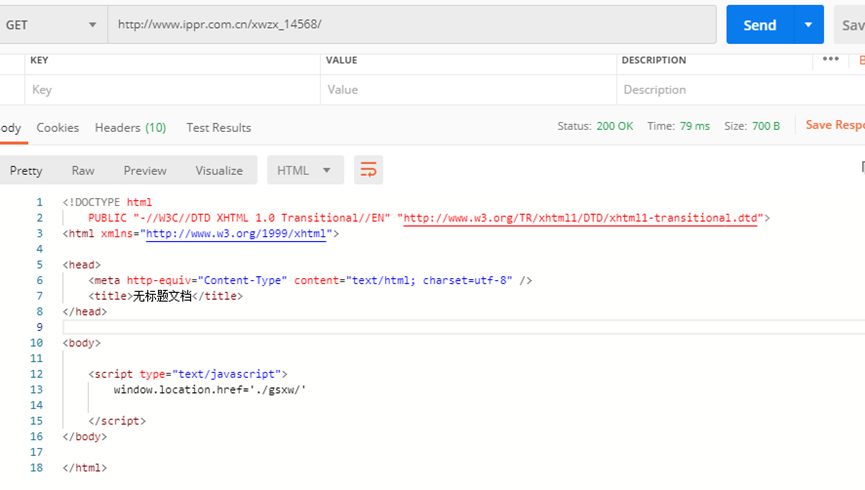
Aminer Knowledge Graph Comprehensive Technical Document
url:
Patent System Keyword Extractor
https://rogerjtx.github.io/patent_knowledge_graph/
Expert Knowledge Graph KbpPipeline
https://rogerjtx.github.io/kbp_pipeline/
Arbitrary Style Transfer via Multi-Adaptation Network
url:
Image Segmentation Based on Overlapping Cells
url:
Medical Image Recognition [COVID-19]
https://rogerjtx.github.io/medical_image_recognition
Content:
- Study Graph 学习架构
- MongoDB Operation 相关操作
- Git Github Gitlab
- Python MongoDB Operation 操作
- Linux Command
- Vim Command
- Cmd Command
- Data Structure and Algorithm
- Computer Basic 计算机基础知识
- Python Basic 基础操作
- Math Basic 数学基础
- Java Basic 基础操作
- C++ Basic
- Golang Basic
- JavaScript Basic
- Matlab Basic 基础操作
- MySQL 数据库
- ElasticSearch 数据库
- ArangoDB 数据库
- HBase 数据库
- Azkaban
- FireFox Plug-in 插件
- Notepad++ Plug-in 插件
- Flask Django 接口
- Python Practice 练习题
- main 函数写法
- Html 基础
- Python threading 多线程模块
- Python requests
- Python bs4 BeatifulSoup库
- Regular Expression 正则表达式
- Python def 函数
- python模糊匹配和 str.find()
- FuzzyWuzzy 模糊匹配工具
- Crawler 爬虫
- lxml 的使用
- continue & break 的理解
- 函数封装与调用 代码规范
- 规范代码def()中参数的设置 方便以后修改函数
- log config 配置
- ip proxy 代理的使用
- Pycharm Operation 软件基础操作
- VSCode Operation 软件基础操作
- Return 相关操作
- Selenium & Webdriver
- Webdriver 的使用
- encode 编码问题
- Recursive function 递归函数
- Anaconda
- RPC
- MongoDB Index Optimization 索引优化
- Bloom Filter 布隆过滤器 原理
- Python 安装官方whl包 和 tar.gz包的方法(推荐)
- PDF file 原理
- USBkey 原理
- DisplayLink USB转HDMI原理
- 前端渲染 和 后端渲染
- 重点理解这里for循环中return后crawler函数赋值给变量count
- datetime.timedelta 时间处理
- isodate类型
- self 理解
- html2text模块 [网页标签文本分类]
- Goose Extractor 抽取正文
- 手机抓包
- Error Collection 问题汇总
NLP—
- Embedding 的理解
- High Latitude Data 高纬度数据
- Text Similarity 文本相似度计算
- Decision Process 动态规划
- Message Queuing MQ 消息列队
- jieba 中文分词算法
- Text summary generation 文本摘要生成
- Keyword Extractor
- Title Extractor
- Text Extractor 正文抽取
- Accurate Split 精准分句
- Syntactic Analysis句法分析
- News list page recognition 新闻列表页识别
- Breadth First Search BFS算法
- Relation Extractor 关系抽取
- Data uniqueness 数据唯一性判断
- Monte carlo search tree MCTS 蒙特卡洛树搜索
- Pytorch
- Cluster 聚类
- KNN Algorithm 算法原理
- Viterbi Algorithm维特比算法
- word2vec 文本向量化 [词向量, 句向量]
- Gensim
- n-gram 原理
- BM25 Algorithm 算法
- 分块统计算法 分块算法
- Curvature filtering algorithm 曲率滤波算法
- Semantic search based on Knowledge Graph 基于知识图谱的语义搜索
- Question Answer QA问答系统
- Expert System 专家系统
- Chi-square test 卡方检测
- 我的数据挖掘代码问题
- Confusion Matrix 混乱矩阵
- Sklearn
- plt.scatter 各参数详解
- Pandas
- Weka
- Hanlp [Java]
- Allennlp
- urllib.parse 中 urllib.parse.urljoin()用法 自动拼接网址
- 磁力链接原理
- Search Engines 搜索引擎工作原理
OCR—
- OCR 图像文字识别
- FALSR 图像超分辨率算法
- Canny 边缘提取算法手动实现
- 百度ocr api接口
- 阿里云OCR 图像识别接口
- Yolov3
- Window 相关操作
- Project 教师数据的抓取和分类项目 总结
Programming Notes Start
Website: https://github.com/RogerJTX
Email: fengdejiezou@126.com
Notes: rogerjtx.github.io
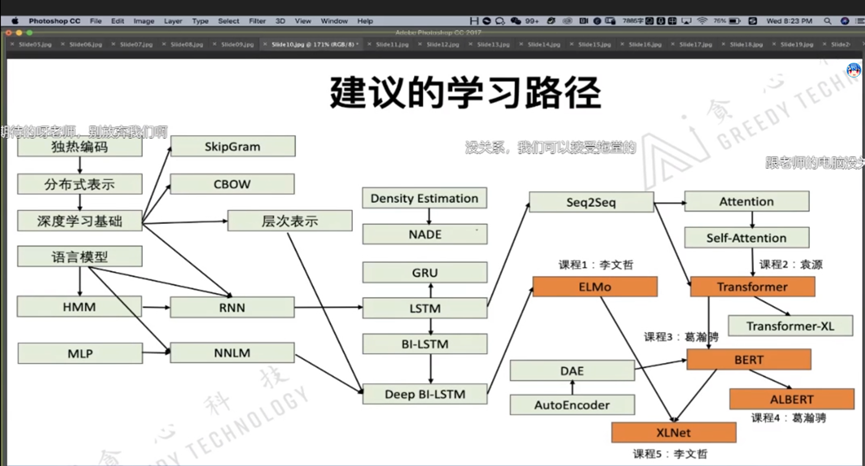
学习架构 Study Graph
1.math part 数学部分

2.word2vec part 词向量部分

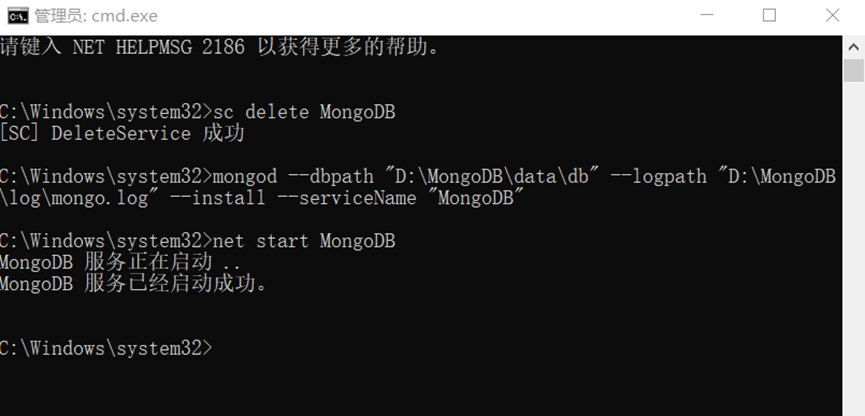
安装和配置MongoDB数据库。
在配置log路径和db路径配置的时候出现错误。
错误情况:启动MongoDB服务时(net start MongoDB 显示”服务没有响应控制功能”)。
最后在dos管理员中完全删除MongoDB后再从新配置后成功启动MongoDB服务。如下图。我在Win10系统Windows PowerShell管理员上操作没有用,需要在C:\Windows\System32中用管理员模式打开cmd.exe操作删除和启动MongoDB服务。参考链接:https://blog.csdn.net/sl_world/article/details/82181731
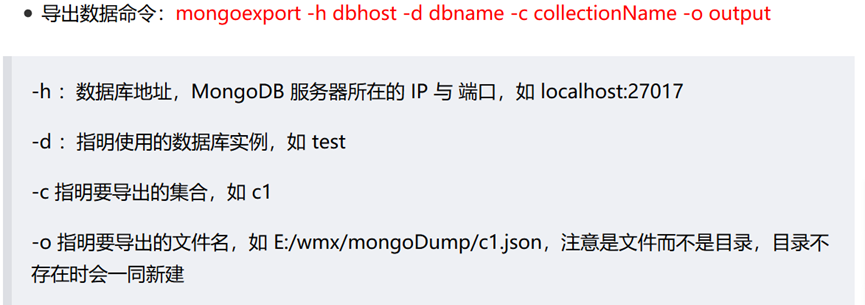
MongoDB 相关操作
1.mongodb的使用
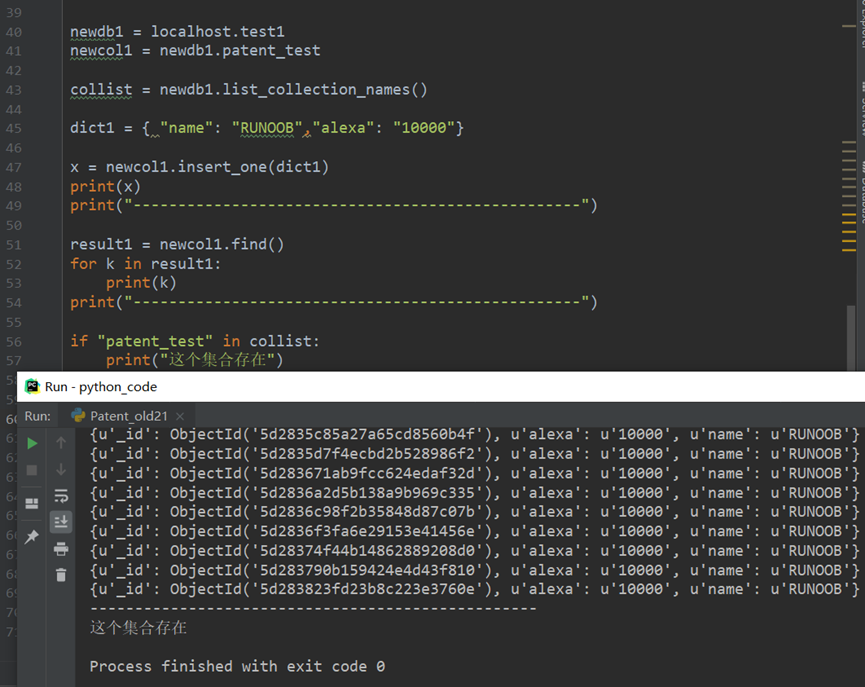
拷贝mongo中的collection到本地
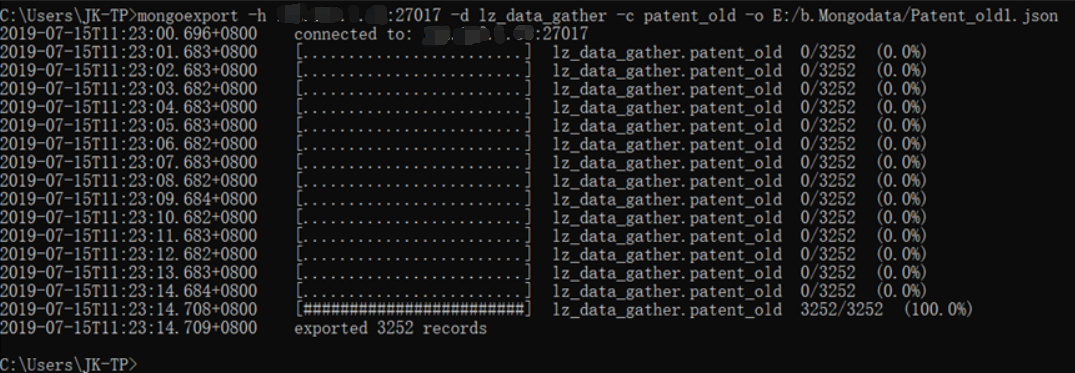
然后使用shell成功导出patent_old集合到本地文件夹Patent_old1.json
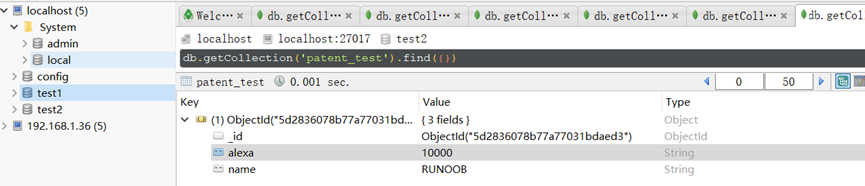
 导入到本地localhost:27017中的db:text2的collection:patent_test中
导入到本地localhost:27017中的db:text2的collection:patent_test中

导入成功:

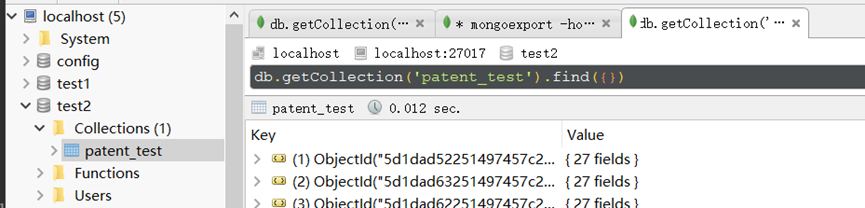
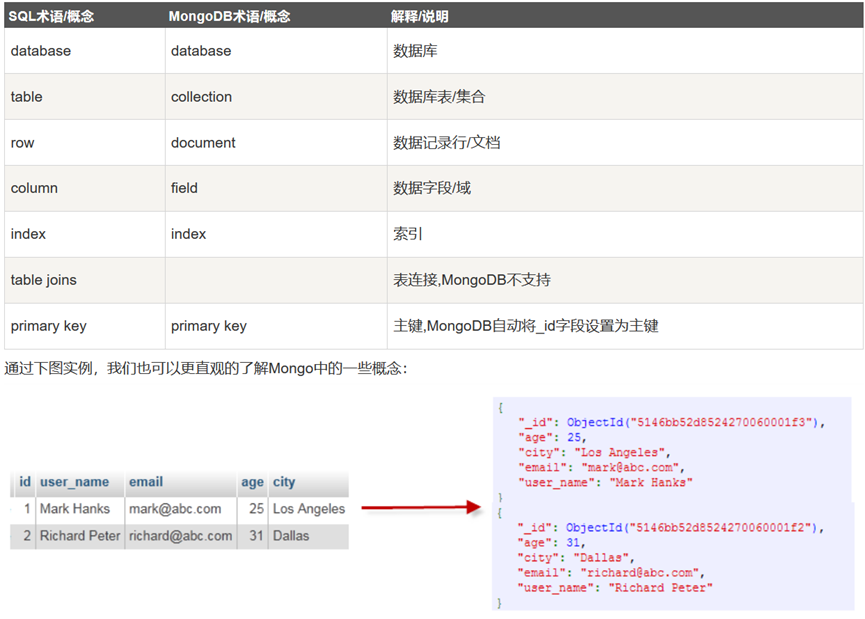
2.MongoDB概念
3.直接在mongodb中修改key的名字
db.getCollection(‘news_leiphone’).updateMany( {}, { $rename: { “time”: “publish_time” }})
修value的值 全部
db.getCollection(‘hangzhou_dianzikeji_uni’).update({},{$set:{“university”:’杭州电子科技大学’}},false,true)
4.直接在mongdb中删除重复数据
https://www.jianshu.com/p/7685e6692ed6
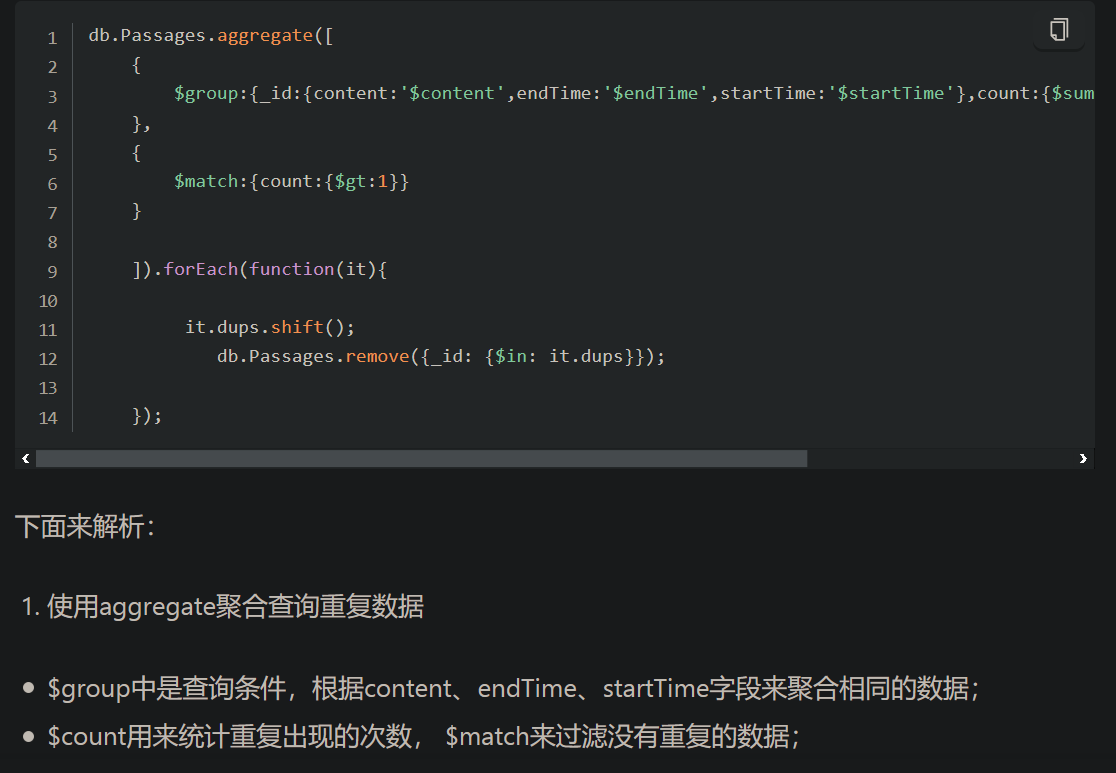
5.mongodb 模糊匹配() Fuzzy matching

统计数量
db.getCollection('expert_ckcest01').find({source:/中国工程科技专家库/}).count()
筛选
db.getCollection('expert_ckcest01').find({source:{$regex:/中国工程科技专家库/}})
数据库直接查询
db.student.find({name:{$regex:'jack', $options:'i'}})
db.student.find({name:{$regex:/jack.*/i}})
db.student.find({name:/jack/i})
6.增加、删除mongodb中某个字段
mongo命令:
db.users.update({},{$unset: {"name":""}},{multi:true})
db.getCollection('news_ofweek').update({}, {$unset: {"search_key":""}}, {multi:true})

7.mongodb 自定义主键
https://www.jianshu.com/p/8af88384cd7f
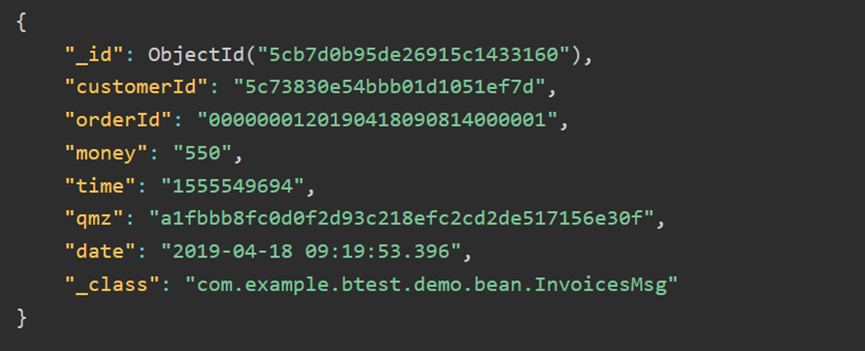
MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
_id 是主键,确保唯一数据
_id 可以是一个string,可以自定义
8.mongo条件查询 存在某个字段的数据
db.getCollection('tableName').find({"RouteInfo":{"$exists":true}})
db.getCollection('news').find({"publish_time":{"$exists":false}})
db.getCollection('res_kb_process_expert_ai').find({flag_baike:{$exists:false}})
代码:
pbar = tqdm(self.mongo_coll.find({"$or": [{"flag_baike": 0}, {"flag_baike":{"$exists":False}}]}))


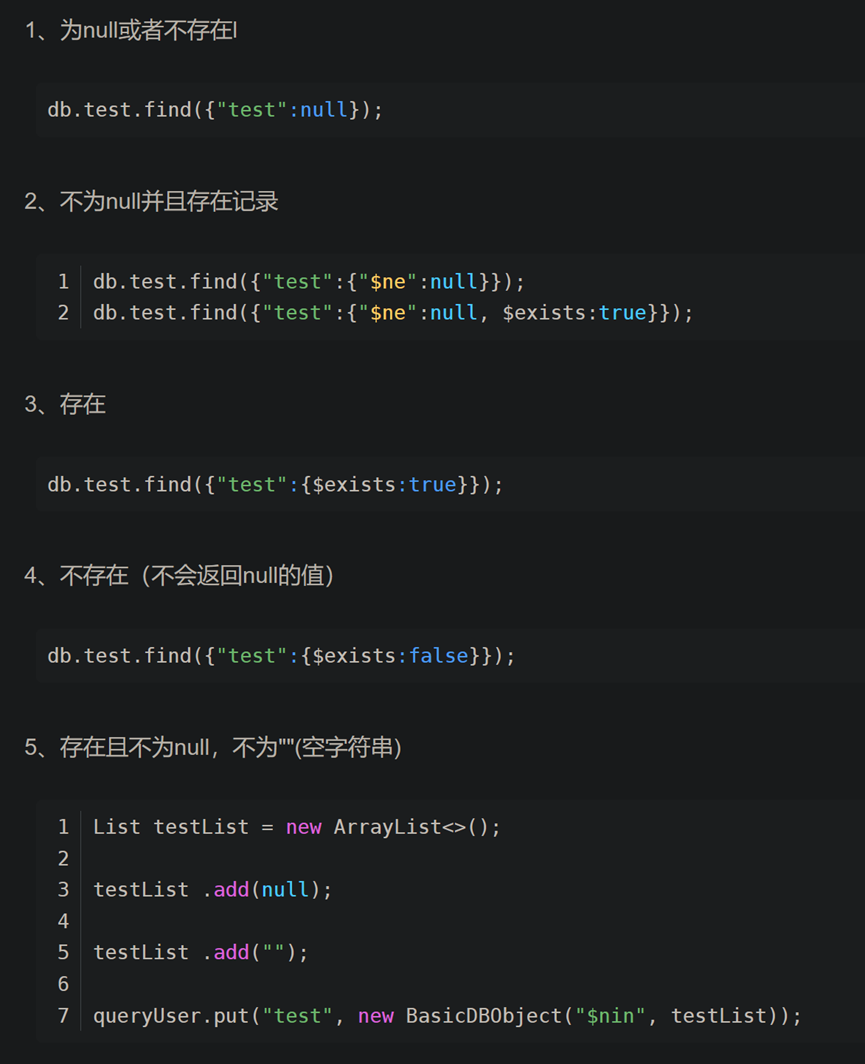
9.mongo条件查询 某个字段不为空 不为null
db.getCollection('expert_ckcest').find({"tel":{$ne:''}})
db.getCollection('company_auto_news_and_products_maintenance_table').find({'news_list_page_url.0': {$exists:1}}).count()

db.test.find({"test":{"$ne":null, $exists:true}});
10.mongo中 选几个属性进行查看
db.getCollection(‘company_basic_auto_news_2020_year’).find({},{title:1, title_auto:1})
11.mongo和python中定位某个数据 通过时间来定位 向后面遍历 增加速度 快速索引
要在mongo里面建立crawl_time索引
MongoDB:
db.getCollection('company_basic_auto_news_2020_year').find({'crawl_time':{'$gte':ISODate("2020-05-19 00:00:00Z")} })

Python:
crawl_time = i_host['crawl_time']
for i2 in col1.find({'crawler.date':{'$gte':crawl_time}}):
12.mongodb按时间顺序排序
db.getCollection(‘company_basic_auto_news_2020_year’).find().sort({‘publish_date’:-1})
13.mongodb中isodate时间格式 时间字段查询
db.xxxx.find({"ct":{"$gt":ISODate("2017-04-20T01:16:33.303Z")}}) // 大于某个时间
db.xxxx.find({"ct":{"$lt":ISODate("2017-04-20T01:16:33.303Z")}}) // 小于某个时间
db.xxxx.find({"$and":[{"ct":{"$gt":ISODate("2017-04-20T01:16:33.303Z")}},{"ct":{"$lt":ISODate("2018-12-05T01:16:33.303Z")}}]}) // 某个时间段
db.xxxx.find({"ct":{"$gte":ISODate("2017-04-20T01:16:33.303Z"),"$lte":ISODate("2018-12-05T01:16:33.303Z")}}) //某个时间段
14.mongodb skip() limit()方法 跳过数据
db.col.find({},{"title":1,_id:0}).limit(1).skip(1)
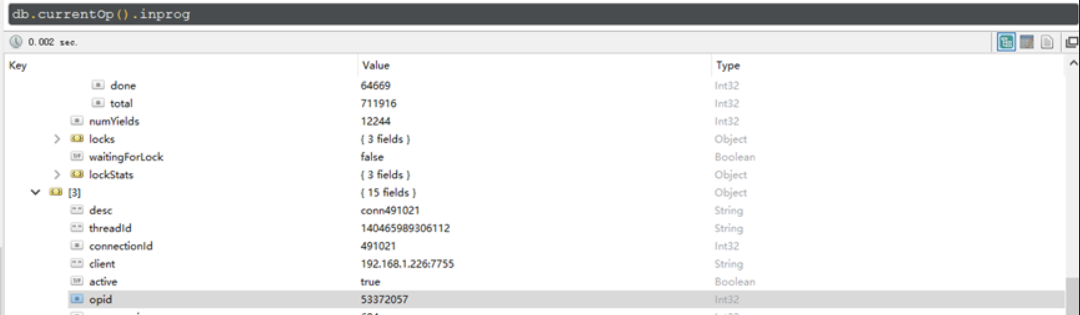
15.MongoDB 进程控制系列一:查看当前正在执行的进程–db.currentOp()
这个命令需要有管理员权限
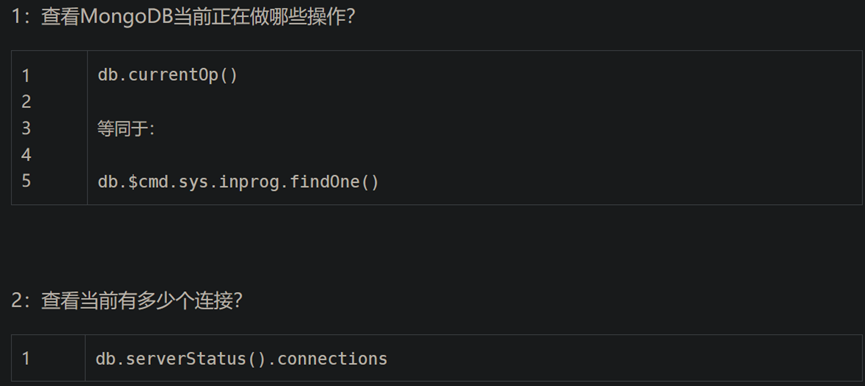
结果解释:
"opid" : 6222,#进程号
"active" : true,#是否活动状态
"secs_running" : 3,#操作运行了多少秒
"microsecs_running" : NumberLong(3662328),
"op" : "getmore",#操作类型,包括(insert/query/update/remove/getmore/command)
"ns" : "local.oplog.rs",#命名空间
"query" : {},#如果op是查询操作,这里将显示查询内容;也有说这里显示具体的操作语句的
"client" : "xxxx:0000",#连接的客户端信息
"desc" : "conn5",#数据库的连接信息
"threadId" : "0x7f1370cb4700",#线程ID
"connectionId" : 5,#数据库的连接ID
"waitingForLock" : false,#是否等待获取锁
"numYields" : 0,
"lockStats" : {
"timeLockedMicros" : {#持有的锁时间微秒
"r" : NumberLong(141),#整个MongoDB实例的全局读锁
"w" : NumberLong(0)},#整个MongoDB实例的全局写锁
"timeAcquiringMicros" : {#为了获得锁,等待的微秒时间
"r" : NumberLong(16),#整个MongoDB实例的全局读锁
"w" : NumberLong(0)}#整个MongoDB实例的全局写锁
16.mongodb中kill杀死一个进程

17.mongo中删除一条数据的某个字段
{“$unset”:{“organization”:””}}

18.mongo _id 可以直接比较大小
19.加速mongo读取
http://blog.yanjingang.com/?p=1342
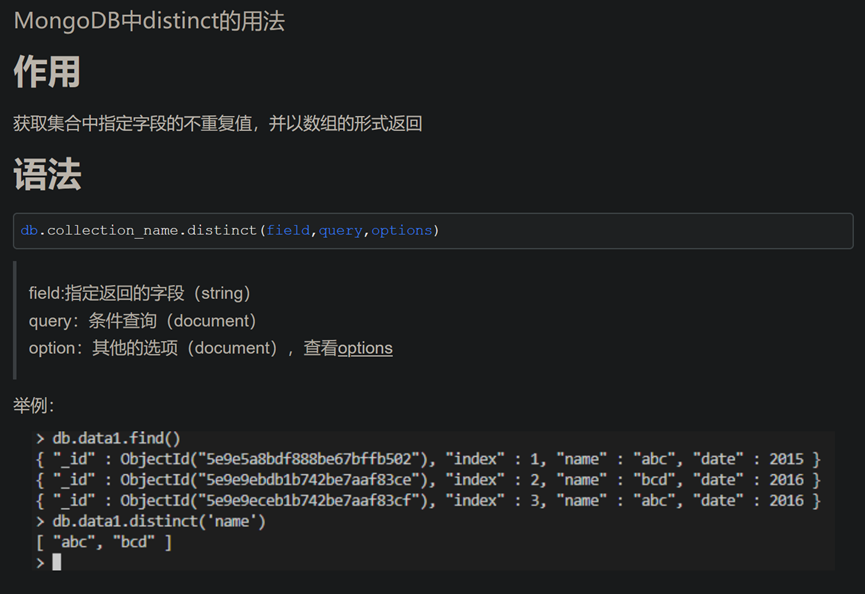
20.mongo中 distinct()用法 获取集合中指定字段的不重复值, 并以数组的形式返回 db.data1.distinct(“name”)
db.collection_name.distinct(field,query,options)
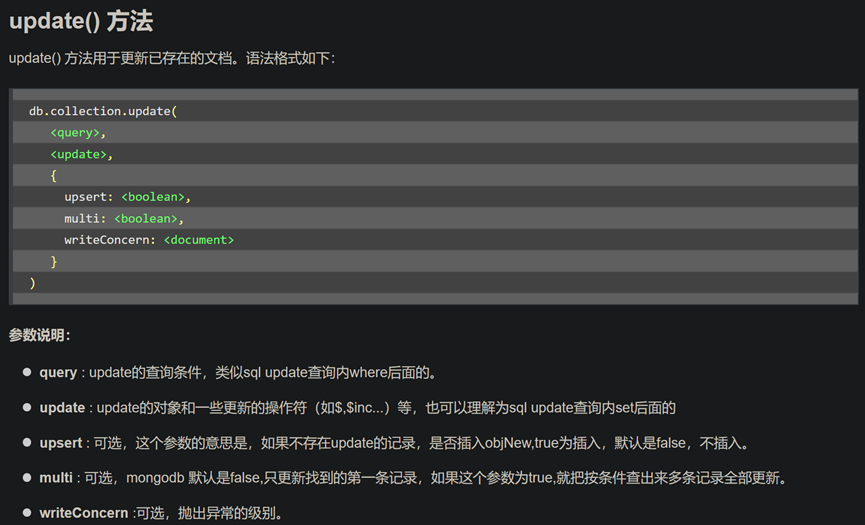
21.mongo中 修改大于 小于的数据 multi : 可选,如果这个参数为true,就把按条件查出的记录全部更新
db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
MongoDB中条件操作符有:
(>) 大于 - $gt
(<) 小于 - $lt
(>=) 大于等于 - $gte
(<= ) 小于等于 - $lte
db.getCollection('res_kb_technology_system').update({"_id":{"$lt":ObjectId("5fb7765a7cc1ca50fd411b17")}}, {"$set": {"source": "国家自然科学基金申请代码"}}, {"multi": 1})
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
• query : update的查询条件,类似sql update查询内where后面的。
• update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
• upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
• multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
• writeConcern :可选,抛出异常的级别。
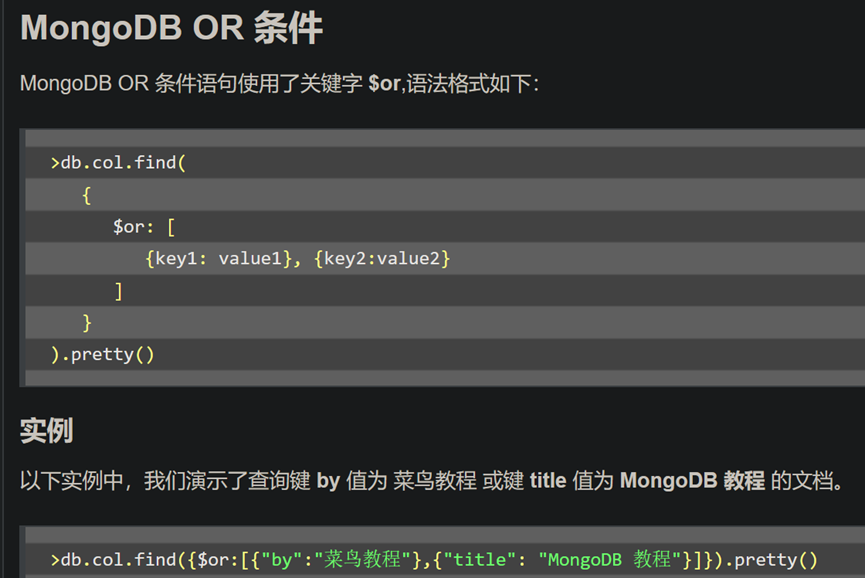
22.mongo OR 条件
db.getCollection('res_kb_process_expert_ai').find({$or: [{flag_baike: 0}, {flag_baike:1}]})
23.mongo upsert
https://blog.csdn.net/jeffrey11223/article/details/80366368
upsert操作会先在集合中进行数据查找,如果数据已经存在,则更新,否则才插入。数据的查找那就势必会使用索引,mongo索引用的是B树,时间复杂度为Olog(n),而没有索引的情况下则时间复杂度是O(n)
24.mongodb 生成id主键 原理
MongoDB的文档必须有一个_id键。
目的是为了确认在集合里的每个文档都能被唯一标识。
ObjectId 是 _id 的默认类型。
ObjectId 采用12字节的存储空间,每个字节两位16进制数字,是一个24位的字符串。
12位生成规则:
[0,1,2,3] [4,5,6] [7,8] [9,10,11]
| 时间戳 | 机器码 | PID | 计数器 |
前四字节是时间戳,可以提供秒级别的唯一性。
接下来三字节是所在主机的唯一标识符,通常是机器主机名的散列值。
接下来两字节是产生ObjectId的PID,确保同一台机器上并发产生的ObjectId是唯一的。
前九字节保证了同一秒钟不同机器的不同进程产生的ObjectId时唯一的。
最后三字节是自增计数器,确保相同进程同一秒钟产生的ObjectId是唯一的。
Git Github Gitlab
前言
修改hosts解决 github网页无法打开的问题 https://www.jianshu.com/p/203f172b06e2
好长一段时间无法使用github,上网查找了一些解决办法,大部分都不能用了。
所以,今天暂且记录一下,以免以后不能用了忘记。
打开C:\Windows\System32\drivers\etc\hosts文件,
在文件最后添加上以下两句:
140.82.113.3 github.com
199.232.69.194 github.global.ssl.fastly.net
至于前面的ip地址,你需要进入ip地址解析网站github.com.ipaddress.com/,查看github的当前映射地址,譬如,我的如下:
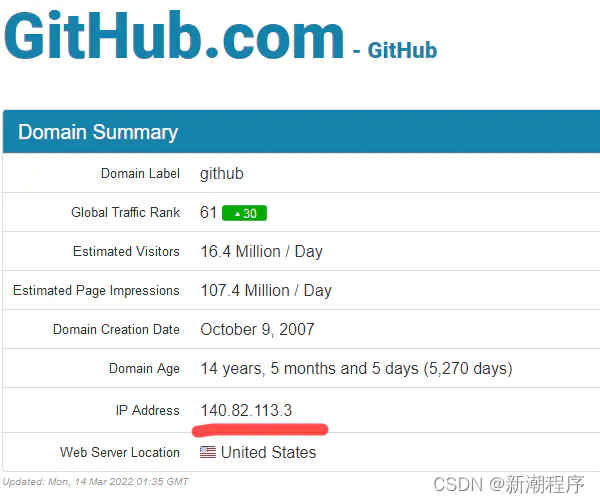
然后进入另一个ssl通道地址网页:github.global.ssl.Fastly.net,查看ssl通道映射的IP地址:
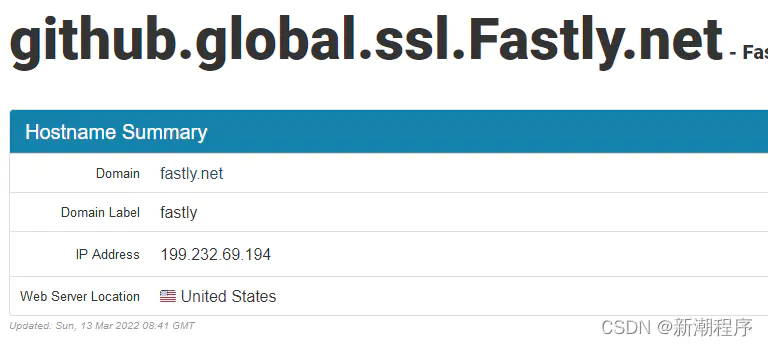
最后进入Windows的命令提示符,输入命令ipconfig /flushdns
刷新dns缓存,然后重启浏览器,就可以进入github网页了,不过,有时候,网页可能不大顺畅,多刷新几遍。
1.什么是git?
• 开源的最先进的分布式版本控制系统,没有之一
• 用以高效、高速的处理从很小到非常大的项目版本管理。
2.什么是版本控制系统?
• 版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统
3.什么是分布式版本控制系统?
• 分布式版本控制系统(Distributed Version Control System,简称 DVCS), 在这类系统中,像 Git、Mercurial、Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
git 原理图
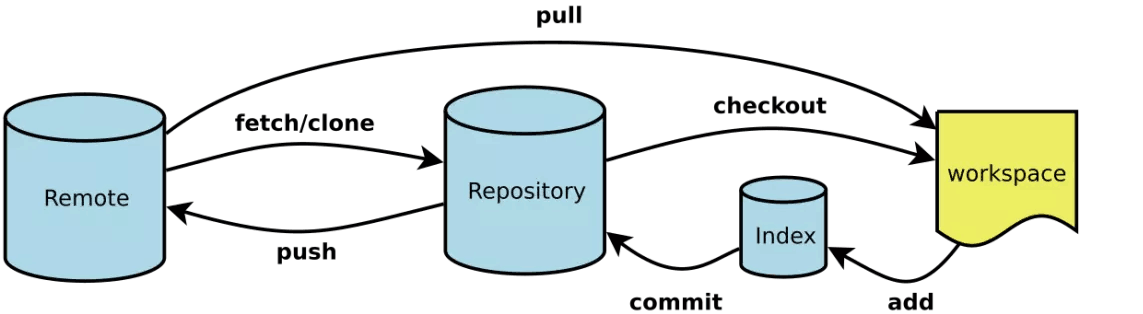
2.Git的功能特性
1. 从服务器上克隆数据库(包括代码和版本信息)到单机上
2. 在自己的机器上创建分支,修改代码
3. 在单机上自己创建的分支上提交代码
4. 在单机上合并分支
5. 新建一个分支,把服务器上最新版的代码fetch下来,然后跟自己的主分支合并
6. 生成补丁(patch),把自己的补丁发送给主开发者
7. 看主开发者的反馈,如果主开发者发现两个一般开发者之间有冲突(他们之间可以合作解决的冲突),就会要求他们先解决冲突,然后由其中一个人提交。如果主开发者可以自己解决,或者没有冲突,就通过
8. 一般开发者之间解决冲突的方法,开发者之间可以使用pull命令解决冲突,解决完冲突之后再向主开发者提交补丁
3.GitBash 安装
https://www.cnblogs.com/NiceCui/p/7735153.html
鼠标右键打开git bash here:
<1>输入git config --global user.name "你的用户名"
<2>输入git config --global user.email "你的邮箱"
<3>输入git init
<4>输入git remote add origin 你刚才建立的项目连接
<5>输入git add .
<6>输入git commit
<7>输入git config http.postBuffer 524288000 (特别提醒: 此行是在本地设置缓存, 有些项目文件较大, 使用http无法上传,可设置此命令)
<8>输入git push -u origin master 将代码推送到gitlab端
4.gitlab和github
先了解一下github和gitlab的区别,为什么推荐使用gitlab?github和gitlab都是知名的代码托管平台,而github不支持私有的免费代码托管,而gitlab不但支持开源的项目开发,同时个人私有项目对广大程序员也免费开放,因此也有大量朋友使用gitlab。
在网站制作,项目开发中,如何将本地项目上传到gitlab上?为了让大家理解的更清楚,我们分为以下几个步骤让大家了解:1.注册gitlab帐号,注意这里需要通过梯子来获取谷歌认证。2.注册了gitlab帐号之后,就可以在个人中心创建一个新的项目,名称必须与你要上传的项目名称保持一致,项目种类分为公用,私有等,用户可以自行选择。3.电脑进行安装git程序,不管是github还是gitlab都是需要git程序进行支持的。4.本地进行克隆gitlab上的空项目至本地,具体命令为打开cmd界面,cd至你的任意文件夹,然后输入命令:git clone 你的项目https地址5.将克隆下来的文件夹里的.git文件夹剪切出来,粘贴至你想要上传的项目根目录下。6.将包含了.git版本控制的本地项目文件夹进行上传即可,依次输入以下命令:1.git add . 2.git commit -m “项目描述” 3.git push7.通过以上6步,即可完成整个项目的上传,打开gitlab,你的项目已经上传至gitlab。一个gitlab的熟练掌握使用,不但利于同一项目多人修改操作的便利,同时通过版本控制系统,可以了解每一个项目的具体修改情况,及时跟进。同时在任意电脑上,可以随时完成项目的随时拉取,进行编写操作。
5.从gitlab下载项目
https://www.cnblogs.com/chenhuichao/p/9631754.html
https://blog.csdn.net/donkor_/article/details/77502800
用git bash 从gitlab上直接下载的代码:
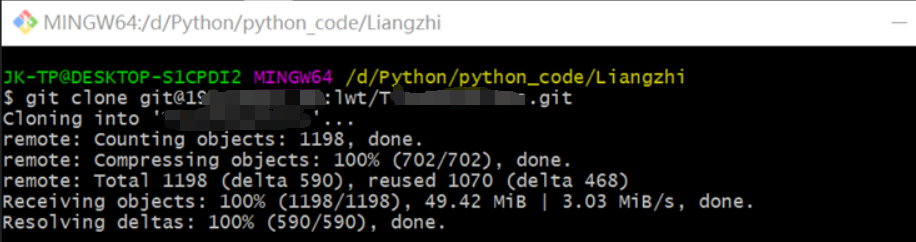
先定位到文件位置
/d/Python/python_code
git clone git@xxxx.xxx.xx.xx:xx/xxx.git
网址:http://xxxxxxx/xxx/xx
6.完整git bash上传 下载 更新代码到gitlab上
Git bash 中的操作方法
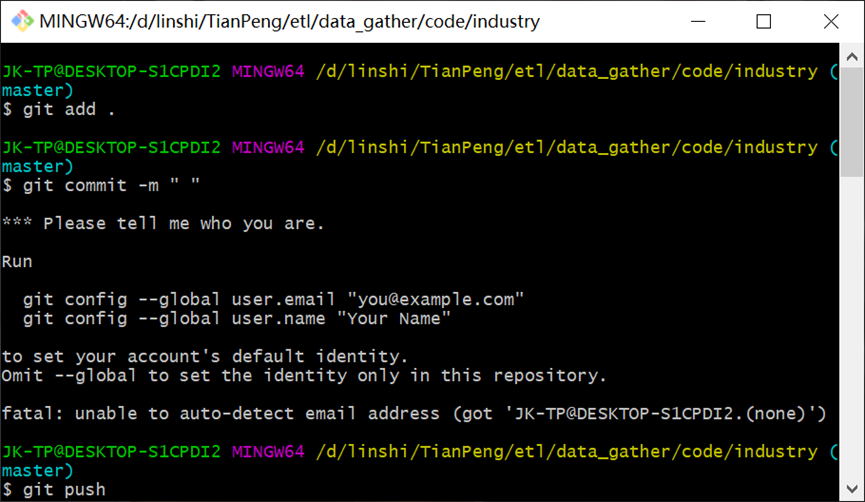
定位到文件目录 右键git bash here
git add .
git commit -m “备注”
git config --global user.email “you@example.com”
git config --global “your name”
git push
pit pull
pycharm中操作git bash
输入 git 查看是否能正常运行

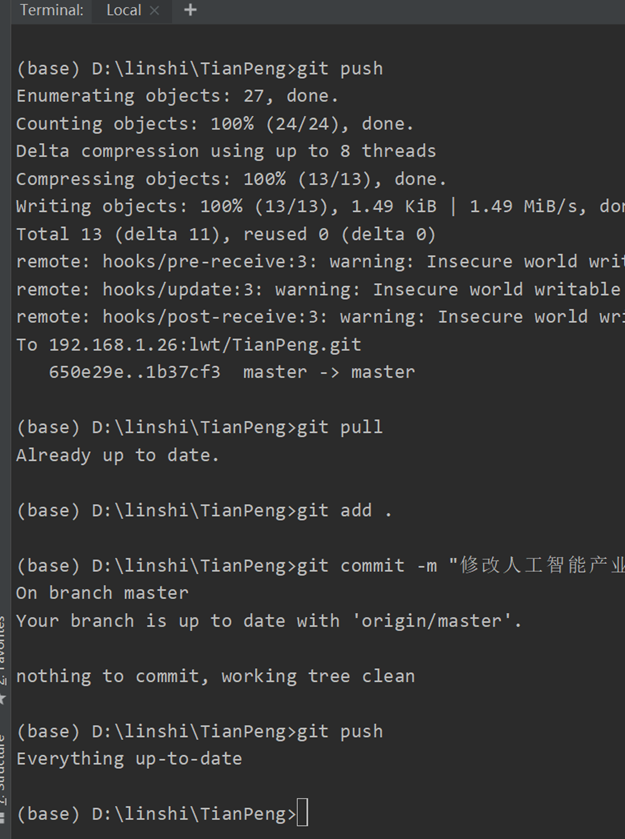
git pull 和 git push
用git bash here 来git clone一个项目目录
然后open as a project
然后git pull git add . git commit -m git push
7.git bash讲解和命令
MinGW,是Minimalist GNUfor Windows的缩写。它是一个可自由使用和自由发布的Windows特定头文件和使用GNU工具集导入库的集合,允许你在GNU/Linux和Windows平台生成本地的Windows程序而不需要第三方C运行时(C Runtime)库。
添加make命令 https://blog.csdn.net/z69183787/article/details/96290717
windows自带的cmd终端或者powershell没有一个好看的,所以在使用终端的场合我默认喜欢用git的bash窗口。
git的bash实际上也就是一个mingw,是可以支持部分linux指令的,但是只有少部分。在编译代码的时候经常会使用make命令反而在bash下默认是不支持的。
到 https://sourceforge.net/projects/ezwinports/files/ 去下载
make-4.1-2-without-guile-w32-bin.zip 这个文件。
把该文件进行解压
把解压出来的文件全部拷贝的git的安装目录下: . \Program Files\Git\mingw64\ ,把文件夹进行合并,如果跳出来需要替换的文件要选择不替换
这样在git bash窗口下就可以执行make了(编译的时候编译器还是需要另外安装的)
8.gihub 提交代码 .gitignore文件
https://blog.csdn.net/luhu124541/article/details/82048357
9.Markdown 语法
GitHub Flavored Markdown
https://guides.github.com/features/mastering-markdown/
https://blog.csdn.net/m0_48270368/article/details/122638531
标题
一级标题:#+空格+文字+回车,或者使用快捷键 CTRL+F1
二级标题:##+空格+文字+回车,或者使用快捷键 CTRL+F2
三级标题:###+空格+文字+回车,或者使用快捷键 CTRL+F3
四级标题:####+空格+文字+回车,或者使用快捷键 CTRL+F4
五级标题:#####+空格+文字+回车,或者使用快捷键 CTRL+F5
六级标题:######+空格+文字+回车,或者使用快捷键 CTRL+F6
字体
粗体:在文字的两边各加上两个*,再回车即可。
效果图:粗体
斜体:在文字的两边各加上一个*,再回车即可。
效果图:斜体
斜体加粗:在文字的两边各加上三个*,再回车即可。
效果图:斜体加粗
删除线:在文字的两边各加上两个波浪号~,再回车即可。
效果图:删除线
引用
语法:一个箭头>+空格
引用内容(在引用他人语句或者是博文的时候可以用到)
分割线
三个*+回车
三个-+回车
图片
语法:!+[图片名字]+(图片的地址,可以是本地的,也可以是在线的)
注意事项:是半角符号中的括号(即英文的)
超链接
语法:[自定义名字]+(超链接的地址)
注意事项:是半角符号中的括号(即英文的)
排序
有序排序:1.+空格即可,回车之后序号会自增,连续回车两次则不再往下自增
无序号排序:-+空格即可,回车则可自动生成点,退出排序也是连续两次回车即可
表格
| 常规做法:表头中的不同序列用 | 隔开,表格设计完成后进入源代码页面将中间空的行删掉,则可以生成表格。 |
快捷方式:右键插入一个表格即可
代码
语法: ```+编程语言名字(例如java)
9.1 Markdown 转跳到某个目录 页面内添加锚点
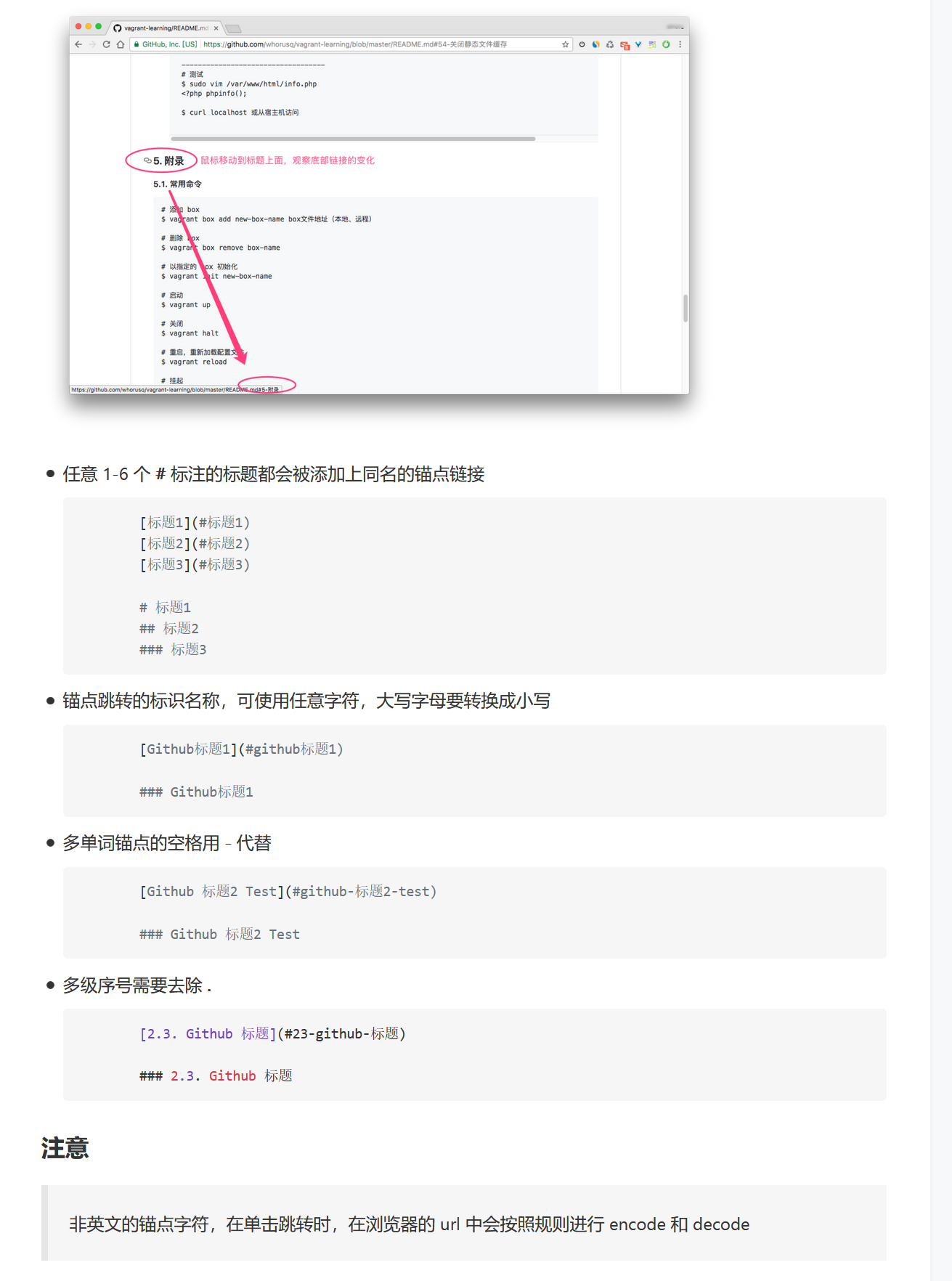
方法1:
----
## 目录
1. [目录1](#jump1)
2. [目录2](#jump2)
---
### <span id="jump1">1. 目录1</span>
### <span id="jump2">2. 目录2</span>
方法2:
[目录1](#jump1)
#jump1 是目录名字 名字中的空格用 '-' 代替
9.2.如何在GitHub上用Markdown写博客
https://www.jianshu.com/p/eb9af1279499
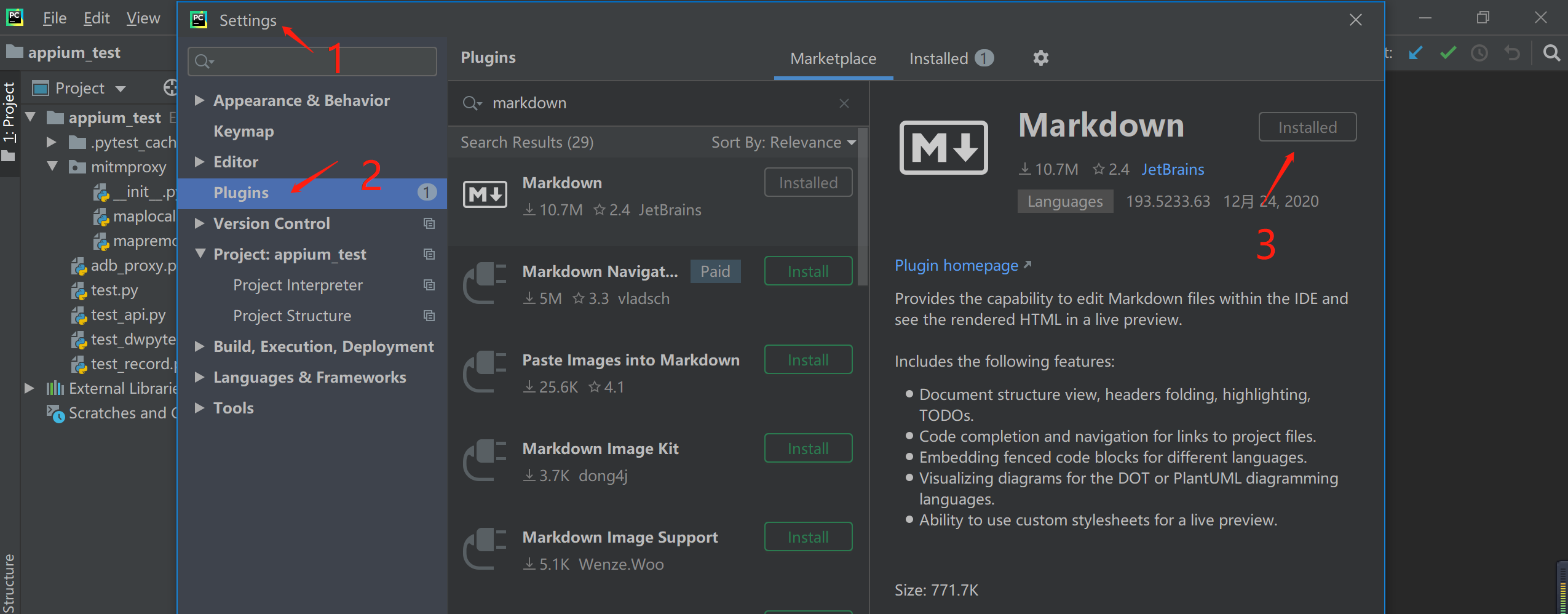
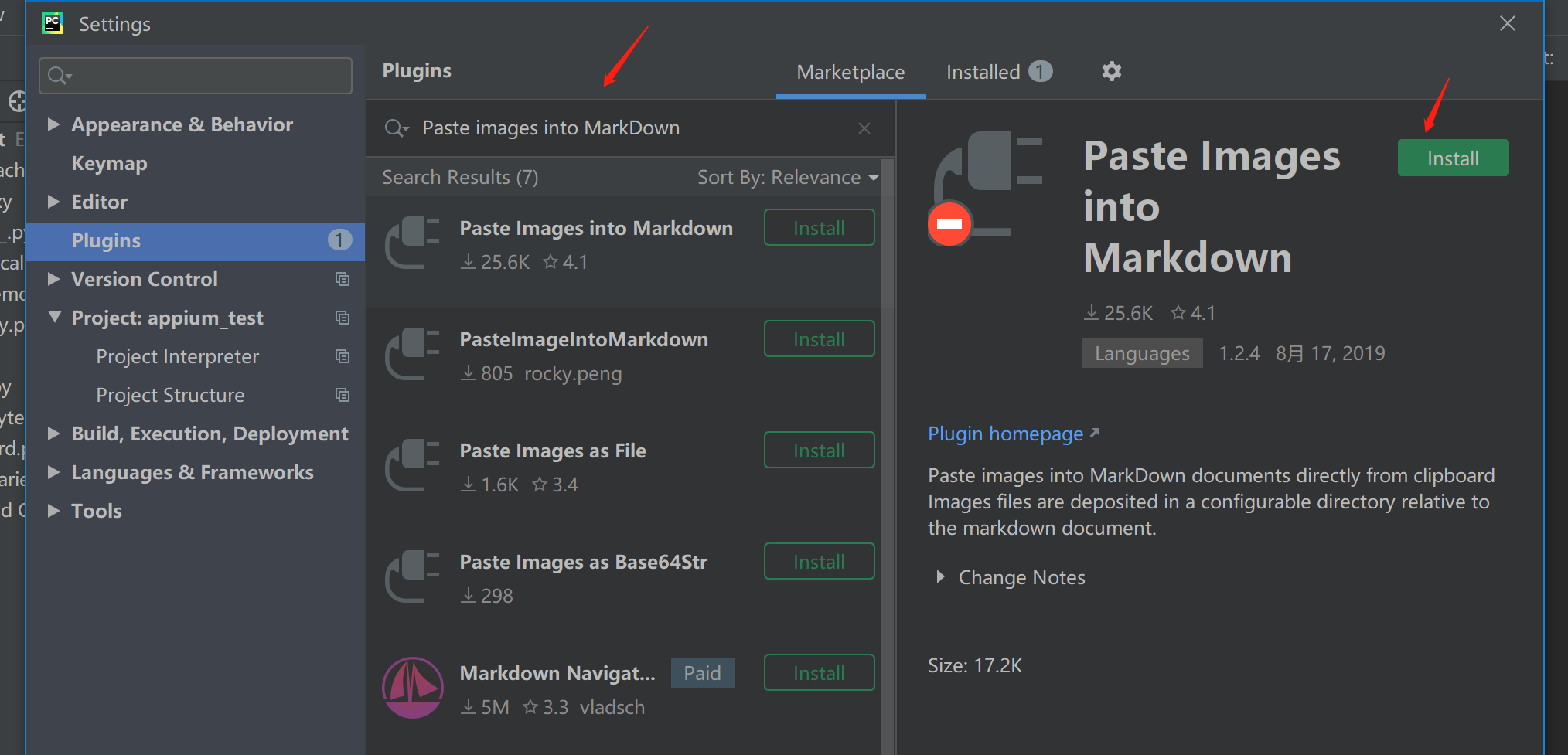
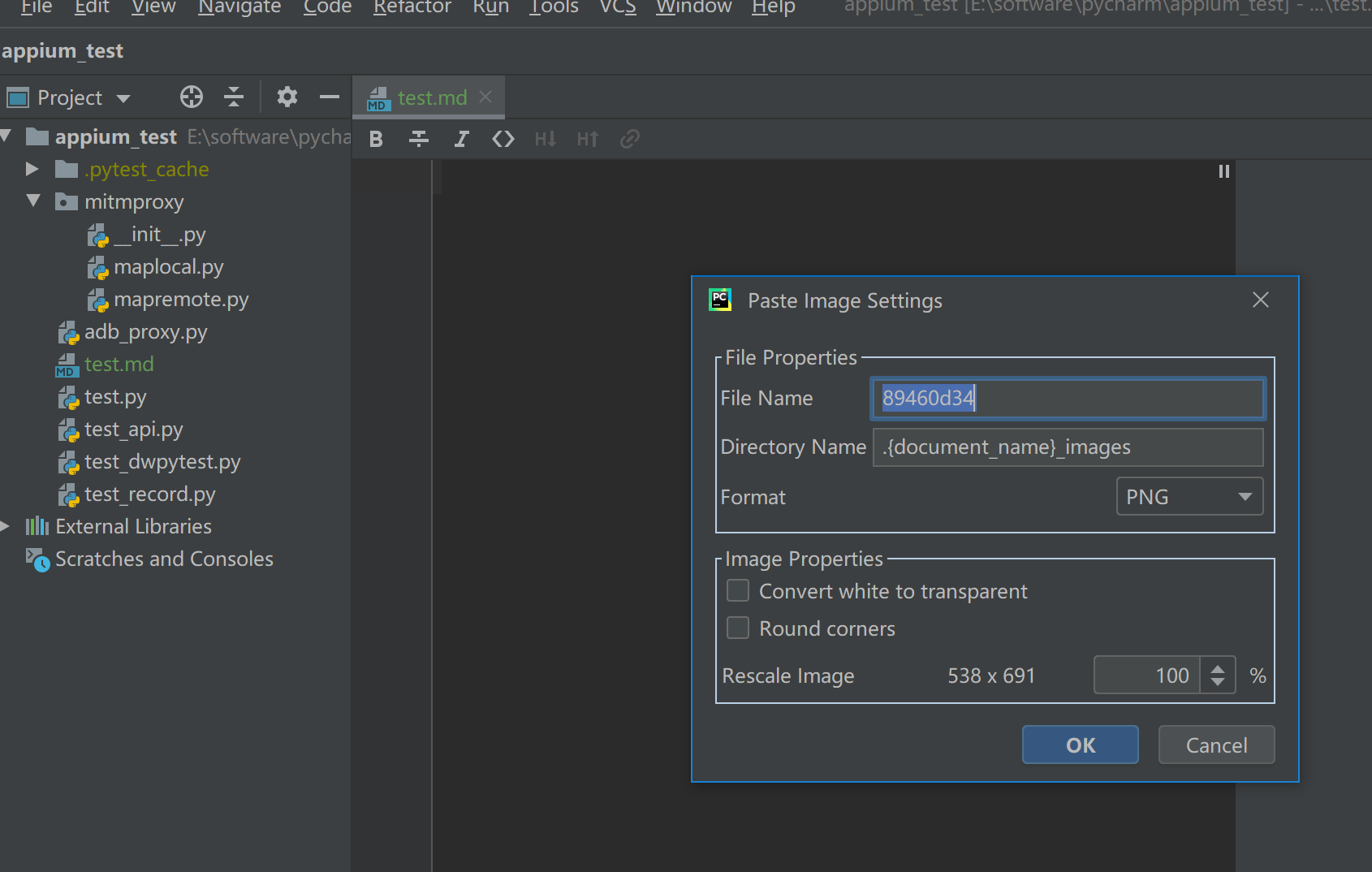
9.3.Pycharm 中使用 Markdown
https://www.cnblogs.com/yaogonewiththewind/p/14188941.html
安装Markdown
安装Paste images into MarkDown
markdown粘贴图片
10.[重要] Pychamrm中 Git 免登录办法
https://segmentfault.com/a/1190000013759207
如果我们git clone的下载代码的时候是连接的https://而不是git@git (ssh)的形式,当我们操作git pull/push到远程的时候,总是提示我们输入账号和密码才能操作成功,频繁的输入账号和密码会很麻烦。
解决办法:
git bash进入你的项目目录,输入:
git config --global credential.helper store
然后你会在你本地生成一个文本,上边记录你的账号和密码。当然这些你可以不用关心。
然后你使用上述的命令配置好之后,再操作一次git pull,然后它会提示你输入账号密码,这一次之后就不需要再次输入密码了。
11.GitGuardian - 开箱即用的 GitHub 敏感信息泄露自动提示平台
作者的博客地址:https://calpa.me/
项目官网地址:https://github.com/calpa/
开源项目作者:Calpa Liu
Github 作为程序员必争之地,上传的代码无可避免地遭到 24x7 的自动机器人扫描。百密一疏,就算是安全意识良好的同学也会不小心上传敏感信息。若是使用 GitGuardian 的话,我们可以马上收到通知,处理问题,及时止血。
无数黑客会用自动脚本扫描 Github 上面的信息,偷取资料,盗取信用卡,直接访问数据库,插入挖矿代码,或者加入后门。
而 GitGuardian 是首个实时,自动扫描开源项目代码的平台。当发布敏感资料到 Github 开源项目时,它就会自动提醒我们,比如说发送电子邮件。
第一个平台实时扫描所有 GitHub 公共活动的 API 秘密令牌,数据库凭证或保险库密钥。在几秒钟内收到警报。在几分钟内集成。
它也提供很多 API 来提示用户问题,不过免费版本就只会发送电子邮件。
11.1 源码解析
12.github 删除敏感提交记录和历史记录
12.1 提交一个新分支替换掉原来的主分支
https://cloud.tencent.com/developer/ask/30403
删除.git文件夹可能会导致git存储库中的问题。如果要删除所有提交历史记录,但将代码保持在当前状态,可以按照以下方式安全地执行此操作:
步骤:
1.尝试 运行 git checkout --orphan latest_branch
2.添加所有文件git add -A
3.提交更改git commit -am "commit message"
4.删除分支git branch -D master
5.将当前分支重命名git branch -m master
6.最后,强制更新存储库。git push -f origin master
解释:使用 orphan 参数创建分支
git checkout --orphan [分支名称]
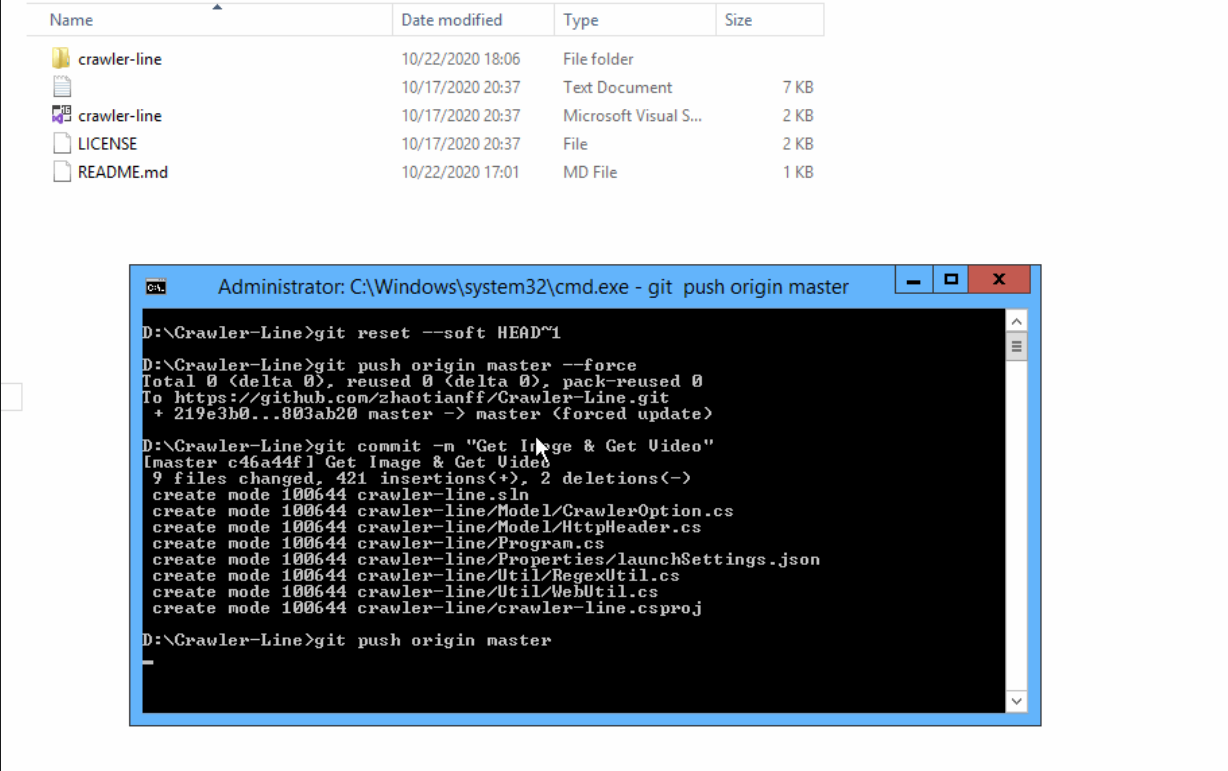
12.2 恢复到第几次的提交记录,后面的全部删除
git reset –soft HEAD~i
i代表要恢复到多少次提交前的状态,如指定i = 2,则恢复到最近两次提交前的版本。–soft代表只删除服务器记录,不删除本地。
再执行
1 git push origin master –force
master代表当前分支
这样操作完成后,服务器最近的两次提交记录已经看不到了。
此时,我们再把本地的文件提交一次就行了。
13.checkout 用法总结 [Git]
https://www.jianshu.com/p/cad4d2ec4da5
1.
checkout最常用的用法莫过于对于工作分支的切换了:
git checkout branchName
该命令会将当前工作分支切换到branchName。另外,可以通过下面的命令在新分支创建的同时切换分支:
git checkout -b newBranch
2.
git checkout --orphan <new_branch>
假如你的某个分支上,积累了无数次的提交,你也懒得去打理,打印出的log也让你无力吐槽,那么这个命令将是你的神器,它会基于当前所在分支新建一个赤裸裸的分支,没有任何的提交历史,但是当前分支的内容一一俱全。新建的分支,严格意义上说,还不是一个分支,因为HEAD指向的引用中没有commit值,只有在进行一次提交后,它才算得上真正的分支。
14.git add -A 和 git add . 的区别
https://blog.csdn.net/caseywei/article/details/90945295
git add -A和 git add . git add -u在功能上看似很相近,但还是存在一点差别
git add . :他会监控工作区的状态树,使用它会把工作时的所有变化提交到暂存区,包括文件内容修改(modified)以及新文件(new),但不包括被删除的文件。
git add -u :他仅监控已经被add的文件(即tracked file),他会将被修改的文件提交到暂存区。add -u 不会提交新文件(untracked file)。(git add --update的缩写)
git add -A :是上面两个功能的合集(git add --all的缩写)
总结:
· git add -A 提交所有变化
· git add -u 提交被修改(modified)和被删除(deleted)文件,不包括新文件(new)
· git add . 提交新文件(new)和被修改(modified)文件,不包括被删除(deleted)文件
15.git branch 使用
15.1 git branch 基础
1.查看本地分支
$ git branch
* br-2.1.2.2
master
2.查看远程分支
$ git branch -r
origin/HEAD -> origin/master
origin/feature/IOS_visualtrack
origin/feature/android_visualtrack
origin/master
3.查看所有分支
$ git branch -a
* br-2.1.2.2
master
remotes/origin/HEAD -> origin/master
remotes/origin/br-2.1.2.1
remotes/origin/br-2.1.2.2
remotes/origin/br-2.1.3
remotes/origin/master
PS: git branch -r 无法获取远程分支,ui可以看见分支但是git 命令无法查看
原因 git branch -a 这条命令并没有每一次都从远程更新仓库信息,我们可以手动更新一下
git fetch origin
git branch -a
4.切换远程分支
$ git branch -a
* master
remotes/origin/HEAD -> origin/master
remotes/origin/Release
remotes/origin/master
git checkout -b 切换分支
$ git checkout -b myRelease origin/Release
Branch myRelease set up to track remote branch Release from origin.
Switched to a new branch 'myRelease'
PS: 作用是checkout远程的Release分支,在本地起名为myRelease分支,并切换到本地的myRelase分支
5.合并分支
合并前要先切回要并入的分支
以下表示要把issue1234分支合并入master分支
$: git checkout master
$: git merge issue1234
Merge made by recursive.
README | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
6.重名分支
$ git branch -m/M
合并分支
16.git中的远程分支被删除后还可以查看到的解决办法
git branch -r
git remote show origin
git remote prune origin
git branch -r
17.Github上的watch、star和fork分别是什么意思
Github上的watch、star和fork分别是什么意思呢?
1、watch可以用来设置接收邮件提醒
2、如果想持续关注该项目就star一下
3、如果想将项目拷贝一份到自己的账号下就fork
fork就相当于在原本的项目分支上建立一个分支,这个分支属于你自己,你也可以任意修改。如果想将你修改后的代码整合到原有的项目中,需要做pull request操作,当然这得经过作者同意。
17.1 watch
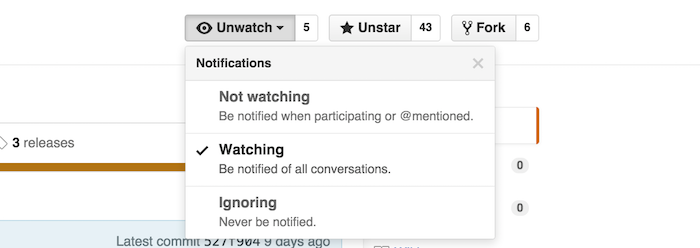
默认每一个用户都是处于Not watching的状态,当你选择Watching,表示你以后会关注这个项目的所有动态,以后只要这个项目发生变动,如被别人提交了pull request、被别人发起了issue等等情况,
你都会在自己的个人通知中心,收到一条通知消息,如果你设置了个人邮箱,那么你的邮箱也可能收到相应的邮件
如下,我 watch 了开源项目android-cn/android-discuss,那么以后任何人只要在这个项目下提交了 issue 或者在 issue 下面有任何留言,
我的通知中心就会通知我。如果你配置了邮箱,你还可能会因此不断的收到邮件。
如果你不想接受这些通知,那么点击 Not Watching 即可。
另外这里有一篇文章讲 如何正确接收 GitHub 的消息邮件,很不错的一篇文章,推荐大家看看。
如何正确接收 GitHub 的消息邮件
https://github.com/cssmagic/blog/issues/49
17.2 star
star 翻译过来应该是星星,但是这个翻译没任何具体意义,这里解释为关注或者点赞更合适,当你点击 star,表示你喜欢这个项目或者通俗点,可以把他理解成朋友圈的点赞吧,表示对这个项目的支持。
不过相比朋友圈的点赞,github 里面会有一个列表,专门收集了你所有 start 过的项目,
点击 github 个人头像,可以看到 your star的条目,点击就可以查看你 star 过的所有项目了。如下图
17.3
当选择 fork,相当于你自己有了一份原项目的拷贝,当然这个拷贝只是针对当时的项目文件,如果后续原项目文件发生改变,你必须通过其他的方式去同步。
一般来说,我们不需要使用 fork 这个功能,除非有一些项目,可能存在 bug 或者可以继续优化的地方,你想帮助原项目作者去完善这个项目或者单纯的想在原来项目基础上己维护一个属于自己项目(比如我 fork 的 AndroidWeekly 客户端,那么你可以 fork 一份项目下来,然后自己对这个项目进行修改完善,当你觉得项目没问题了,你就可以尝试发起 pull request 给原项目作者了。
然后就静静等待他的 merge 邮件通知了。
我看到很多人错误的在使用 fork。很多人把 fork 当成了收藏一样的功能,包括一开始使用 github 的我,每次看到一个好的项目就先 fork,
因为这样,就可以我的 repository(仓库)列表下查看 fork 的项目了。其实你完全可以使用 star 来达到这个目的。
17.4使用建议
1、对于一些可能会经常发生变化的会不定期更新的好项目 多使用 watch.
比如 android-cn 团队的 android-discuss 项目,
你就可以 watching 它,这里面都是一些关于 Android 技术的交流,如果有任何新问题,你都可以收到通知,你可以查看别人的回答,
你可以回答别人提出的问题,这是一个很好的学习成长方式。
其他值得watch的项目还有很多,比如 github 上很多的 Awesome 系列的项目,如 Awesome-MaterialDesign 等,你 watch 这些项目了,
只要项目新增一些好玩好用的东西,你就会收到通知。
我在知乎上看到有人问这样的问题,说 github 上有哪些值得 watch 的项目,其实有很多,我自己也整理了一些,但是没放到 github.
值得注意的是,如果 watch多了,你可能会被无休止的邮件通知烦死(邮件通知可设置),因为被 watch 项目有任何留言、PR等更新都会触发通知,所以做好权衡。
2、喜欢一个项目就 star 它吧~
3、修改开源项目就使用 fork,这样你就可以在原项目的基础上,对项目进行修改提交,现在你是这个项目的主人啦~ 小细节
有些时候,你看到一个项目的 star 数有很多,你就想知道到底都有那些人 star 了这个项目,或者 fork 了这个项目,
但是环顾一圈,你却找不到一个入口,后来自己不经意的发现,只要’点击 star 傍边的数字’,就可以查看有哪些人 star 了这个项目。
是不是有点意思,现在你就可以去试试,watch、fork上面的数字都是可以点击的,道理一样。
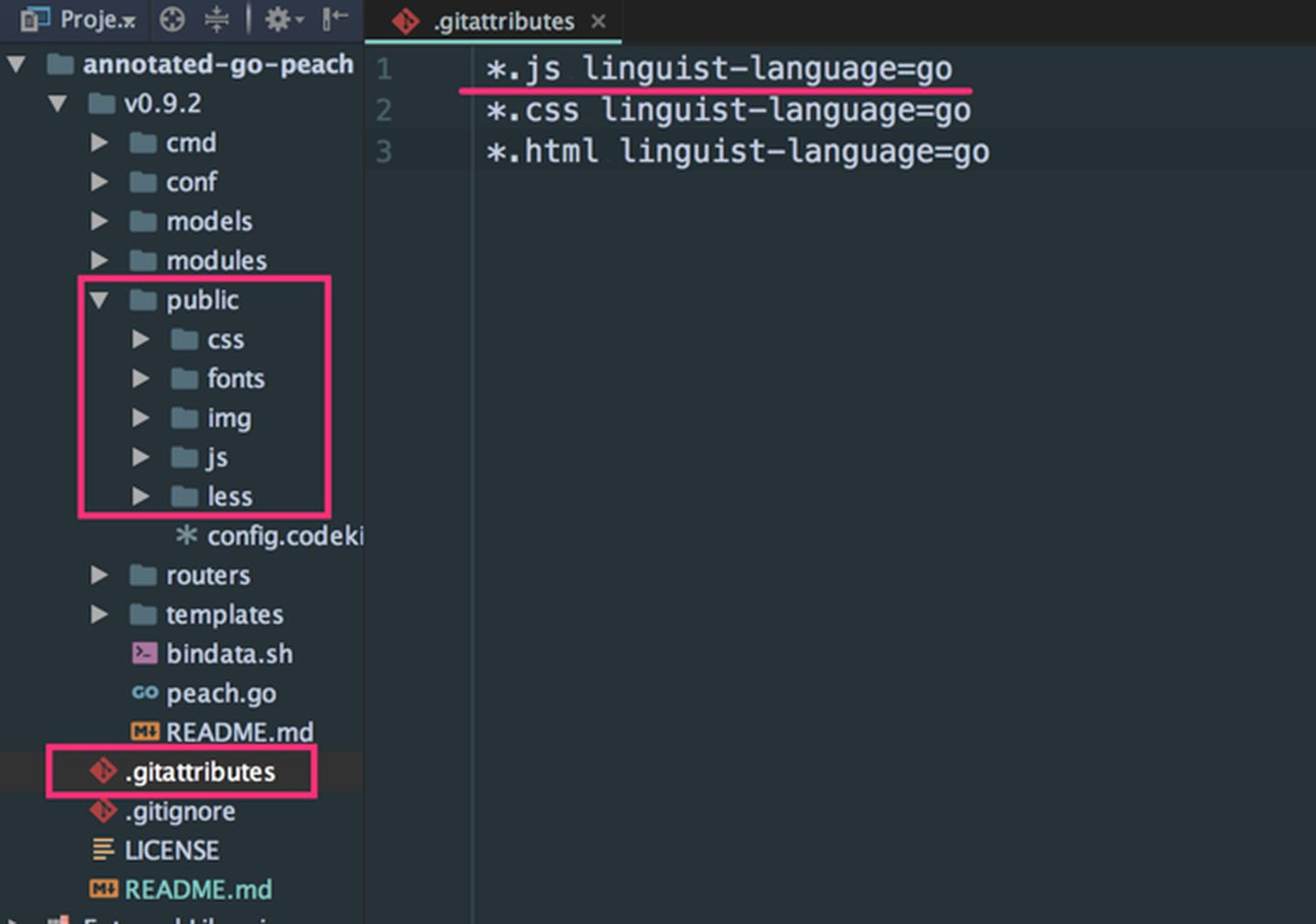
18.github上修改仓库的语言
问题原因: github 是根据项目里文件数目最多的文件类型,识别项目类型.这个够傻.
解决办法:项目根目录添加 .gitattributes 文件, 内容如下 :
*.swift linguist-language=objective-c *.class linguist-language=Java
作用: 把项目里的 .swift 文件, 识别成 objective-c 语言. 这个副作用危害不大.
19.修改github主题
https://blog.csdn.net/qq_40915439/article/details/102154184
首先找到自己喜欢的博客主题https://hexo.io/themes/。
点击进入都有该主题在该博主git下的源码。
如果会使用git,就直接使用git命令进行下载(克隆).(下面是我自己选择的主题)
git clone https://github.com/smackgg/hexo-theme-smackdown themes/smackdown
如果不会使用git命令,就在该博主的git上进行下载
当你把这个文件下载到本地之后,就需要修改配置文件。首先找到自己博客文件夹的地址,将下载的文件夹放到该目录下。
打开该目录下的_config.yml文件,进行修改:
修改为自己的主题名
接下来进行测试,是否修改好
在此目录下打开git
输入 hexo clean进行清理缓存
输入 hexo g重新生成database
输入 hexo s进行本地测试,在命令框会出现一个链接,在浏览器出入此链接看本地博客是否更换主题
成功后,输入 hexo d上传远程仓库。
需要安装git 和 nodejs 和 hexo
https://www.cnblogs.com/visugar/p/6821777.html
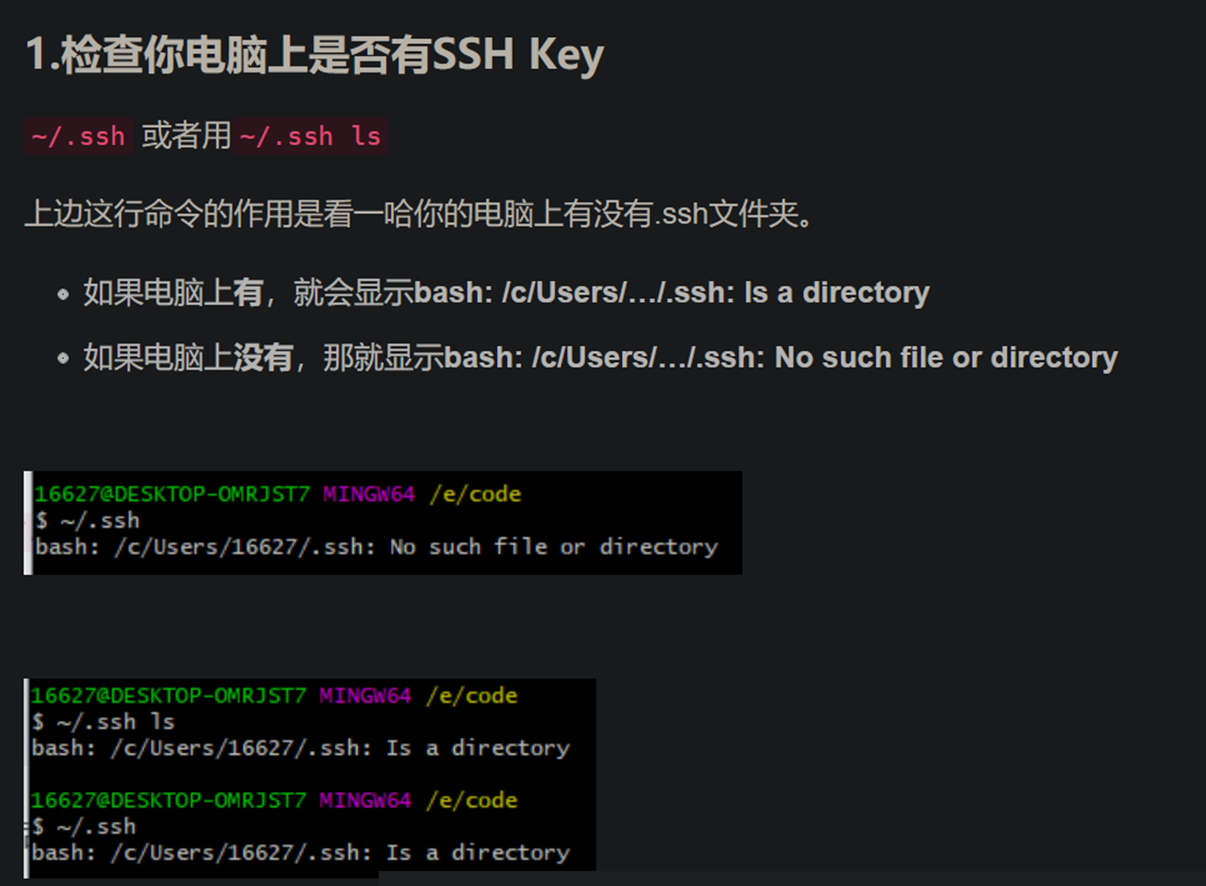
20.git 查看自己的秘匙和秘匙密文地址
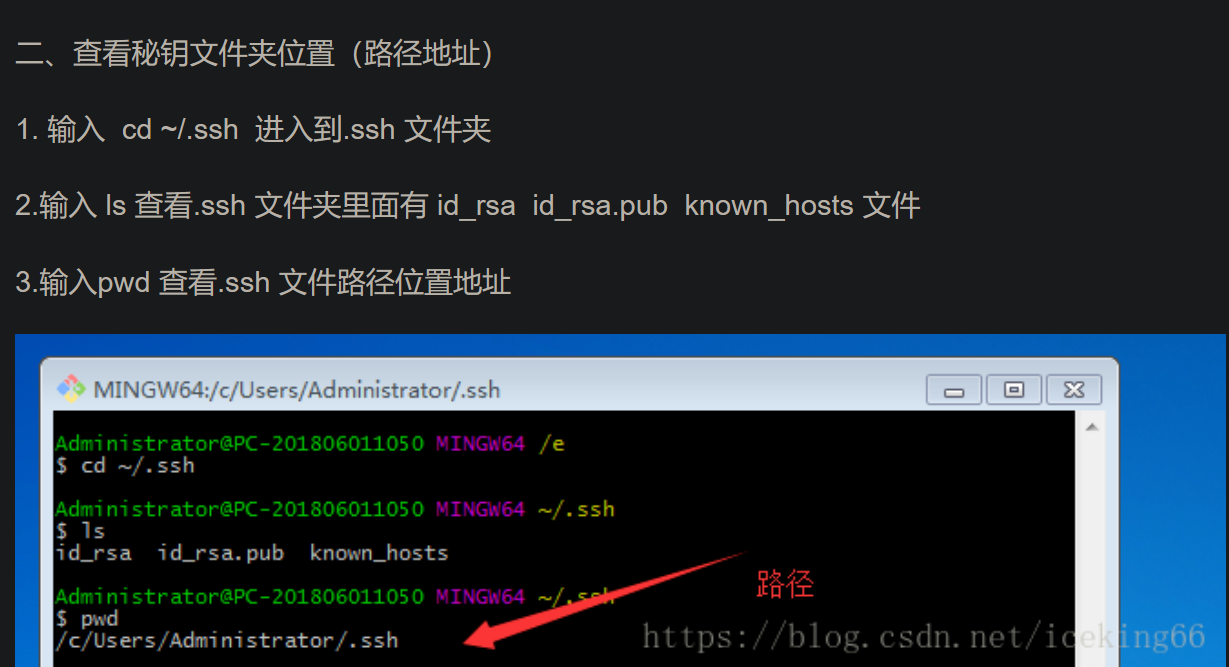
查看本机是否存在SSH keys,
$ ls ~/.ssh/
https://blog.csdn.net/iceking66/article/details/80563716
查看秘钥文件夹位置(路径地址)
1.输入 cd ~/.ssh 进入到.ssh 文件夹
2.输入 ls 查看.ssh 文件夹里面有 id_rsa id_rsa.pub known_hosts 文件
3.输入pwd 查看.ssh 文件路径位置地址
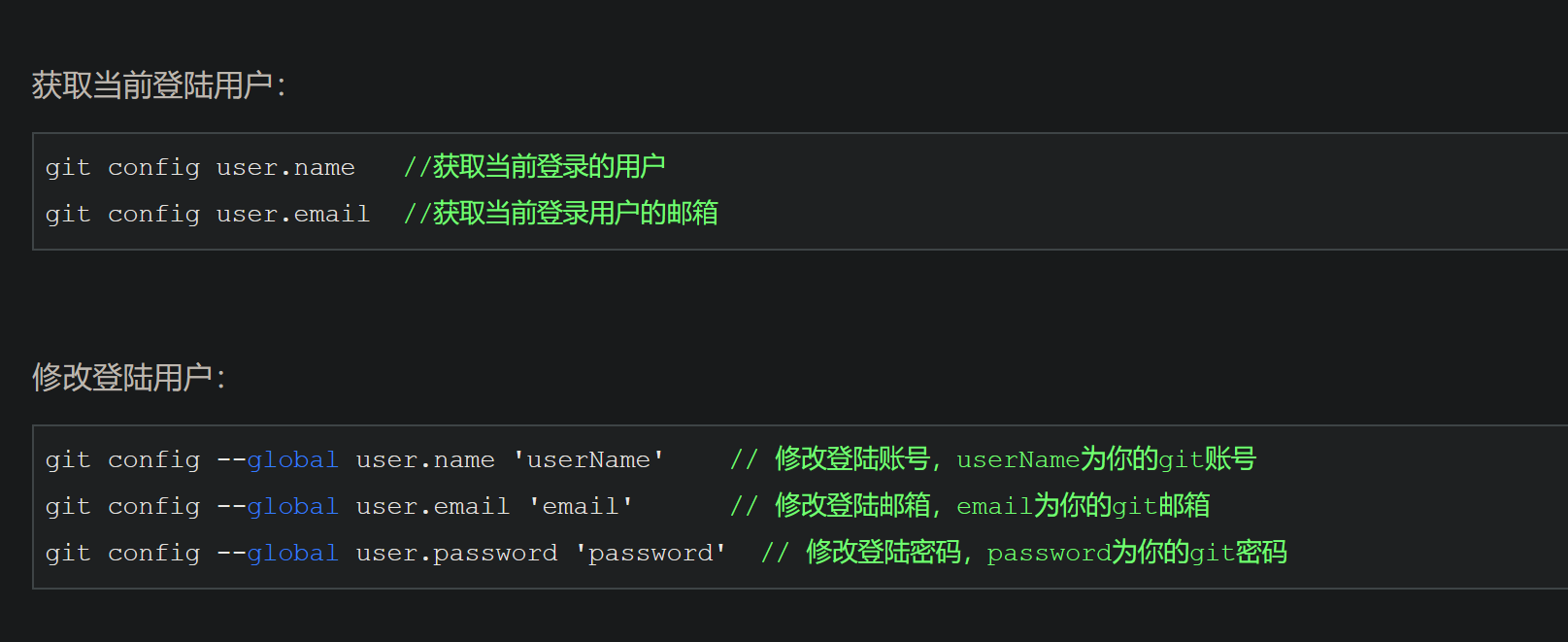
21.git多账号切换
查看当前项目的给git用户名,以及修改当前项目的git用户名
给当前git项目指定git账户
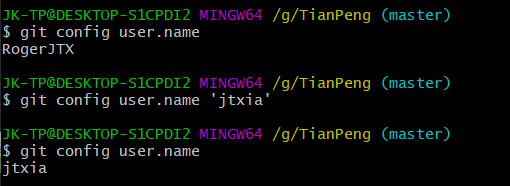
git config user.name //获取当前登录的用户
git config user.email //获取当前登录用户的邮箱
git config user.name 'xxxx..github_name'
22.git 多账号管理
https://blog.csdn.net/joker_zsl/article/details/115494894
我们可能会遇到需要使用多个git账号来操作不同仓库的情况,比如用工作账号来操作公司的gitlab,自己学习的代码则会上传到github,这时就需要管理多个账号。这里记录下git管理多账号的过程。
0 清理旧配置
一般我们是会有曾设置过git的全局配置的,所以首先要清理下。
执行命令先看下是否有全局配置
git config –global –list
如果看到了user.name 和 user.email 信息,执行下面命令清除下
git config --global --unset user.name
git config --global --unset user.email
然后删除下以前生成的公钥和秘钥
1 生成钥对
做完前置的清理工作之后,现在可以重新生成钥对了。分别生成github和gitlab的公钥,注意命名时做出区分。
使用下面命令生成公钥
ssh-keygen -t rsa -C “这里填邮箱地址”
回车之后会让选择保存公钥的文件,默认是id_rsa,这里加上后缀以做区别:id_rsa_github。(注意下文件路径哟,不写路径的话会生成在打开git shell 的目录下)
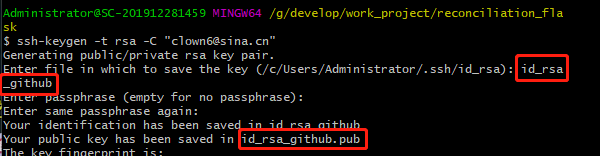
同样的,生成gitlab的公钥即可。
2 添加ssh key
分别为github和gitlab添加ssh key(将 id_rsa_github.pub 和 id_rsa_gitlab.pub 内容分别添加到 github 和 gitlab 的 SSH Keys 中)
3 添加私钥
上一步,我们已经将公钥添加到了 github 或者 gitlab 服务器,现在还需要将私钥添加到本地。使用以下命令
ssh-add ~/.ssh/id_rsa_github
ssh-add ~/.ssh/id_rsa_gitlab
如果添加时出现了Could not open a connection to your authentication agent.的提示,只需先执行下面的命令,之后再执行上述添加命令即可。
ssh-agent bash
添加后,可以使用下面命令确认是否添加完成
ssh-add -l
出现类似下面的东西即是添加成功了

4 管理秘钥
公钥和私钥分别在服务器和本地添加好后,现在需要编辑配置文件来管理账号。在.ssh文件夹的config文件里(如果没有自行创建)
配置内容如下(根据自己的情况填写):
Host github
HostName github.com
User joker
IdentityFile ~/.ssh/id_rsa_github
Host gitlab
HostName gitlab.com
User joker
IdentityFile ~/.ssh/id_rsa_gitlab
该文件分为多个用户配置,每个用户配置包含以下几个配置项:
Host:仓库网站的别名,随意取
HostName:仓库网站的域名(IP地址)
User:仓库网站上的用户名
IdentityFile:私钥的绝对路径
配置后通过下面命令测试下HOST是否能连通
ssh -T git@github
5 仓库配置
现在为不同的仓库配置Local级别的配置,就能使用不能的账号操作不同的仓库了
假设我们要配置 github 的某个仓库,进入该仓库后,执行以下命令
git config --local user.name "你的账号"
git config --local user.email "你的邮箱"
23.git 自动推送程序开发 自动上传程序
https://blog.csdn.net/qq_44926189/article/details/124187232
#!/bin/bash
while true
do
git status
echo "####### 开始自动Git #######"
current_time=$(date "+%Y/%m/%d -%H:%M:%S") # 获取当前时间
echo ${current_time} # 显示当前时间
git add .
git commit -m "modified ${current_time}" # 远程仓库可以看到是什么时间修改的...
git push origin master
echo "####### 自动Git完成 #######"
sleep 20s
done
24.git push origin master和git push的区别
1、git push origin master 指定远程仓库名和分支名。
2、git push 不指定远程仓库名和分支名。
-
这两者的区别:git push是git push origin master的一种简写形式
-
建议使用 git push origin master
25.git .gitignore –指定不上传的文件夹
在使用 vue-cli 脚手架的时候,有一个依赖模板文件夹是不希望被上传到git上的,因为里面文件太多了。
解决办法:手动创建git忽略push清单,node_module以及自身
1.文件夹内右键git bash,输 touch .gitignore,注意中间有空格。
2.编辑器打开生成的 .gitignore 文件,加入:
node_modules
/*以及其他你想要忽略的文件或文件夹*/
3.以后再add到暂存区的时候就会忽略你配置的文件或文件夹了。
忽略具体的文件或文件夹:
/target/ // 忽略这个target 目录
log/* // 忽略log下的所有文件
css/*.css // 忽略css目录下的.css文件
26.git push 大文件失败
最近使用git时,不小心上传了大文件导致push超时缓慢,后面发现.git文件快2G了,于是进行了清理。清理步骤如下
1.网上很多说是.git/objects/pack文件过大,最开始我的objects文件很多而pack文件下没有文件的,所以执行
| git verify-pack -v .git/objects/pack/pack-*.idx | sort -k 3 -g | tail -5 |
报错
fatal: Cannot open existing pack file ‘.git/objects/pack/pack-*.idx’
.git/objects/pack/pack-*.pack: bad
执行git gc之后pack目录下就有文件了
执行下面命令
find .git/objects/ -type f
执行git gc命令
查找大文件
git verify-pack -v .git/objects/pack/pack-*.idx | sort -k 3 -n | tail -3
根据上面提交id看文件
git rev-list --objects --all|grep 7b83aa3d84cb2e523f019e979835a4ffcaf15064

移除doc/book/目录下提交的文件记录
git filter-branch --force --index-filter 'git rm -rf --cached --ignore-unmatch doc/book/**' --prune-empty --tag-name-filter cat -- --all
或者
git filter-branch --force --index-filter 'git rm -rf --cached --ignore-unmatch GO/GoWeb资料.zip --prune-empty --tag-name-filter cat -- --all
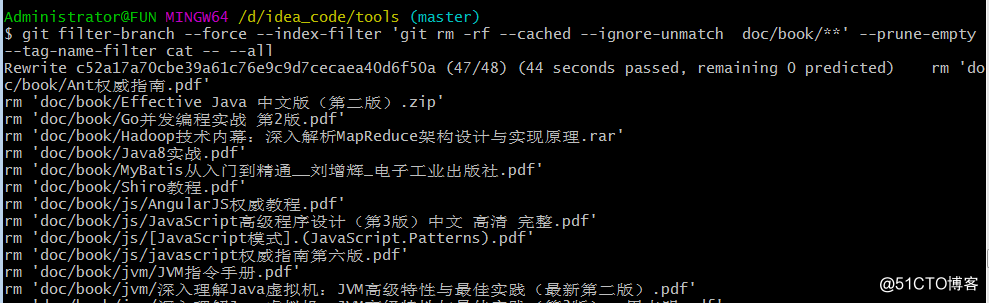
需要注意的是,此处可能会报错
出现这个错误
Cannot rewrite branches : You have unstaged changes
解决方案:执行
git stash即可解决。
真正的删除
rm -rf .git/refs/original/
git reflog expire --expire=now --all
git gc --prune=now
git gc --aggressive --prune=now
git push origin master --force 让远程仓库变小``
git remote prune origin
参考: https://www.jianshu.com/p/fe3023bdc825 https://www.manongdao.com/article-2342370.html http://www.360doc.com/content/21/1216/17/53036841_1008997896.shtml https://blog.csdn.net/biubiu640/article/details/124408507
Python MongoDB 操作
Pycharm编辑器下mongo数据库的可视化配置安装(结果安装了没有可视化功能)
添加mongo插件和配置mongo shell地址(Shell 是一个应用程序,它连接了用户和 Linux 内核,让用户能够更加高效、安全、低成本地使用 Linux 内核,这就是 Shell 的本质。)
https://www.jianshu.com/p/cb75eec056d1
a.集合是否存在判断
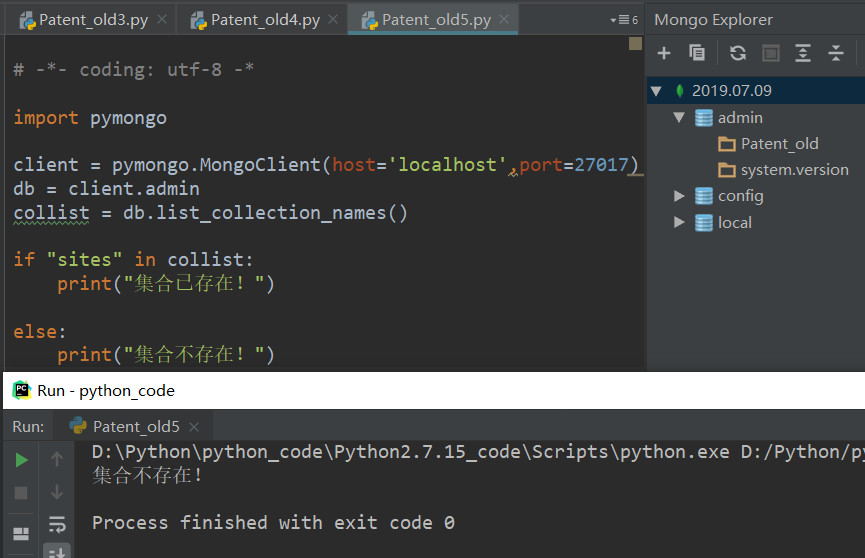
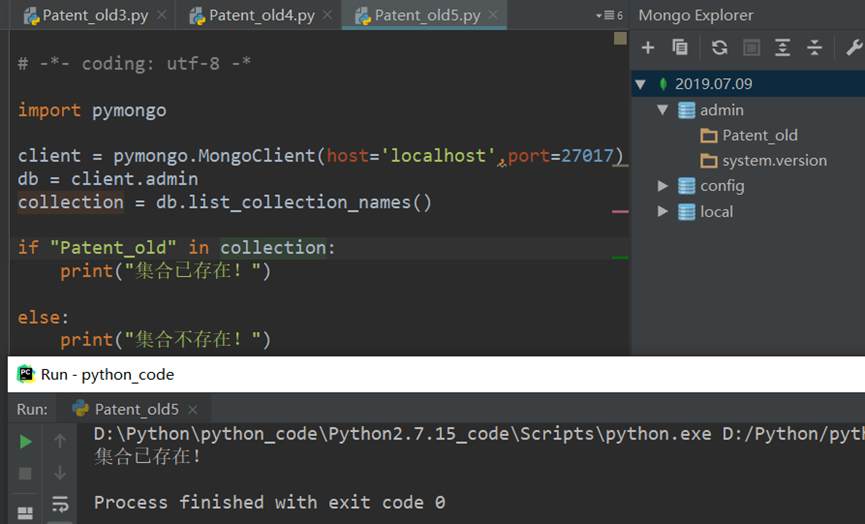
注意: list_database_names()。
b.遍历条目 搜索条目 (问题:出来的字符编码有问题。原因:print()括号中的数据结构没弄好)
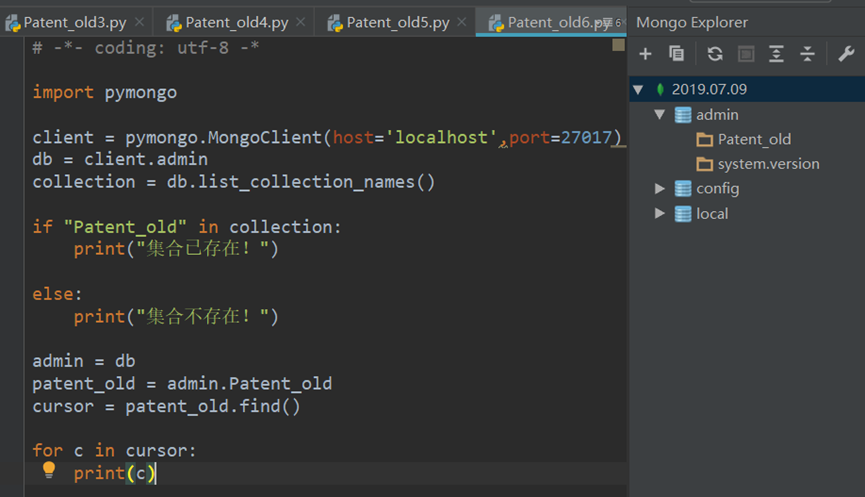
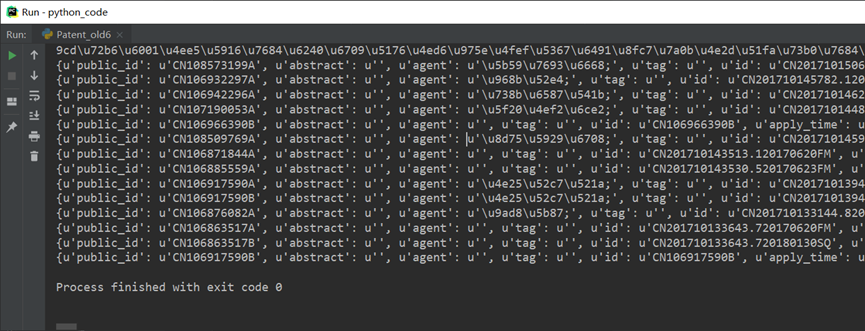
1.查询特定数据
x = patent_old.find_one() #第一条
print(x)
2.高级查询 查询ASCII值apply_time大于2019.01.11的数据
e.g. 以下实例用于读取 name 字段中第一个字母 ASCII 值大于 “H” 的数据,大于的修饰符条件为 {“$gt”: “H”}
ASCII ˈæski可显示字符有 二进制 十进制 十六进制 图形
query 查询
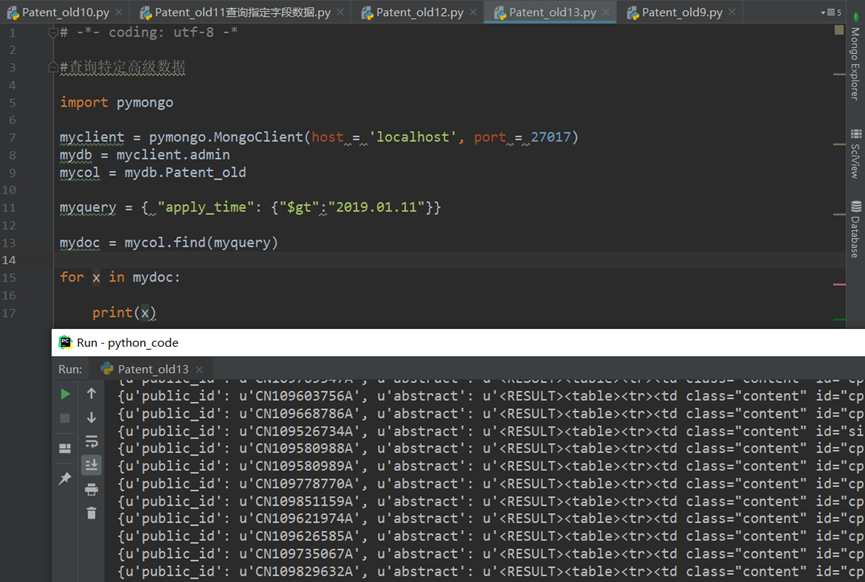
3.使用正则表达式查询
e.g.正则表达式修饰符只用于搜索字符串的字段。用于读取 name 字段中第一个字母为 “R” 的数据,正则表达式修饰符条件为 {“$regex”: “^R”}
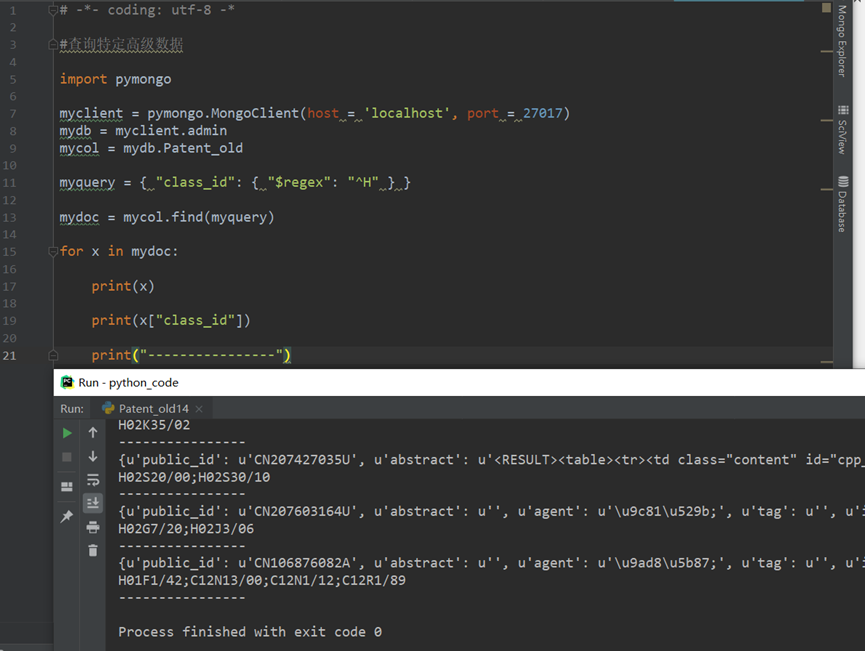
4.返回指定条数记录
e.g.对查询结果设置指定条数的记录可以使用 limit() 方法,该方法只接受一个数字参数
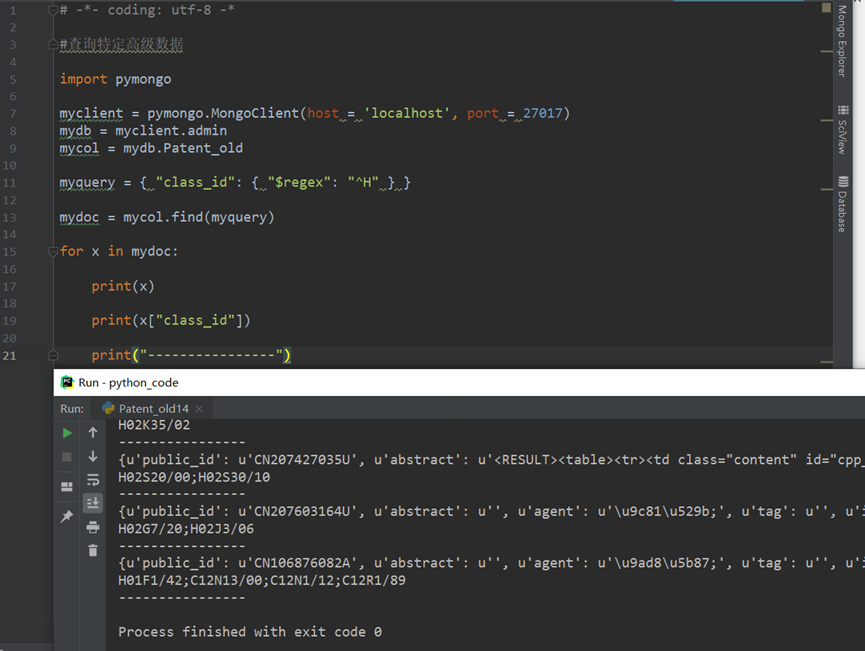
5.字段改名
在数据库中,大多数时,表的”列”称为”字段” ,每个字段包含某一专题的信息。就像”通讯录”数据库中,”姓名”、”联系电话”这些都是表中所有行共有的属性,所以把这些列称为”姓名”字段和”联系电话”字段。
如下图:列表中的字段名字的修改

6.创建数据库、集合
注意:注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。如下图:
集合中插入文档使用 insert_one() 集合中插入多个文档使用insert_many()
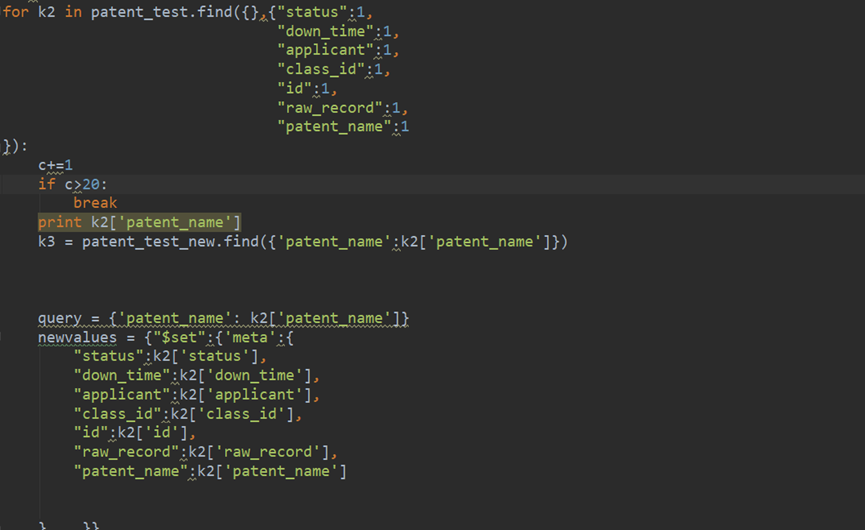
7.mongo内嵌数组匹配
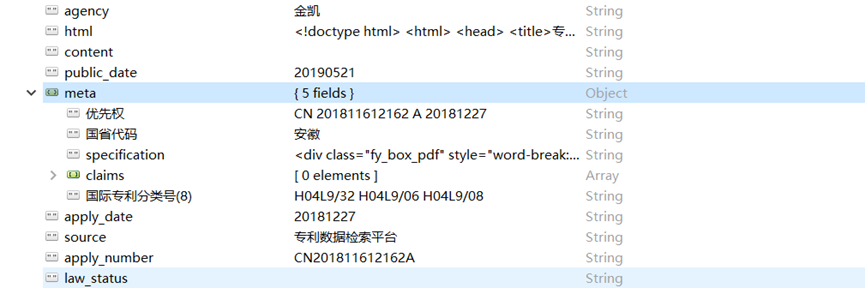
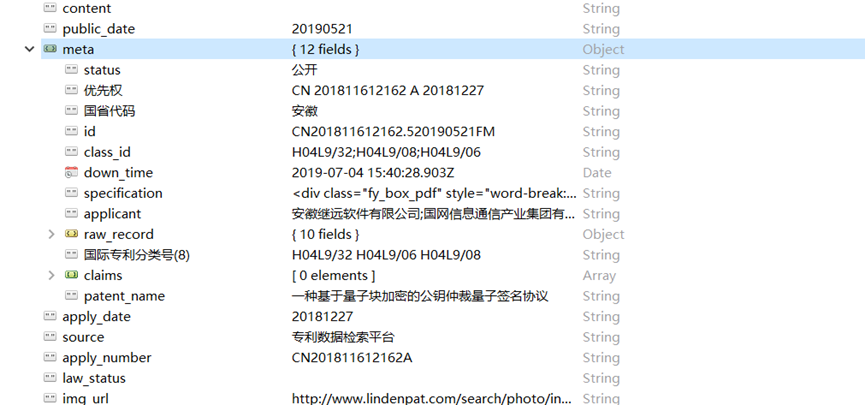
出现问题:将多的文件update更新到”meta”字段的时候字段中原有的五个文件被新的问代替掉了,因为没有定位好”meta”字段的位置。
K3 = patent_test_new.find({‘patent_name’:k2[‘patent_name’]}
8.把多的文件放入对应的object的”meta”
将旧的数据库文件patent_old文件中的多的文件放入新的数据库文件patent 字段”meta”中,用到mongo内嵌数组匹配
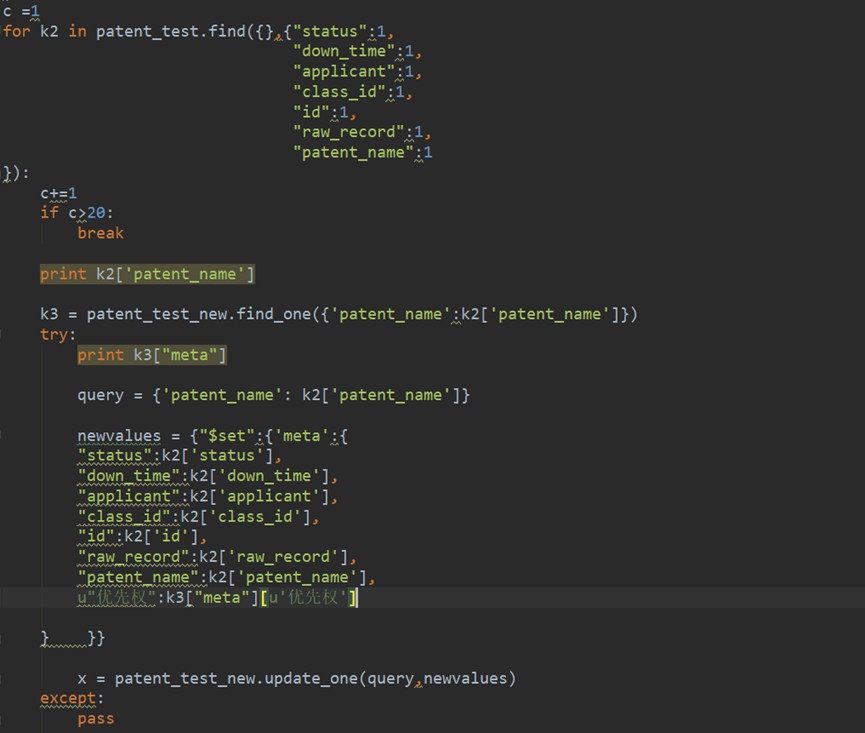
修改前:
修改后:
这里try except 也可以改成if k3
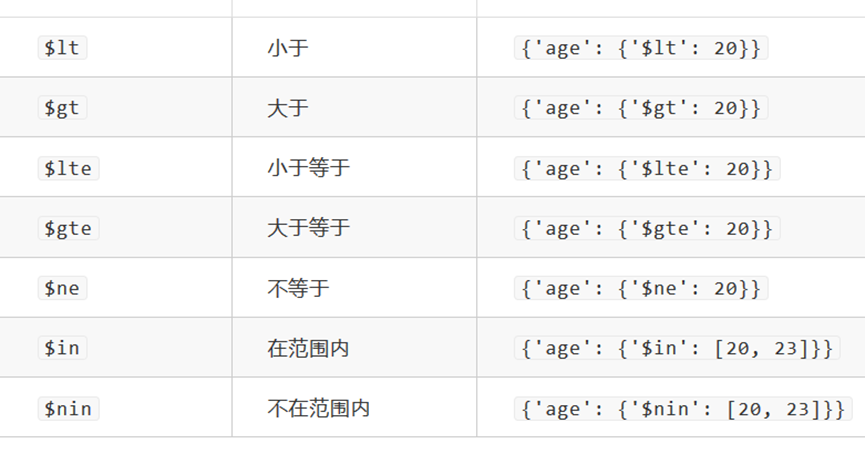
9.mongodb 基础判断符号 大于 小于
10.常见错误
10.1
pymongo.errors.DuplicateKeyError: E11000 duplicate key error collection: test2.patent_test_new index: _id_ dup key: { : ObjectId('5d1dad63251497457c20de2c') }
表示主键重复了
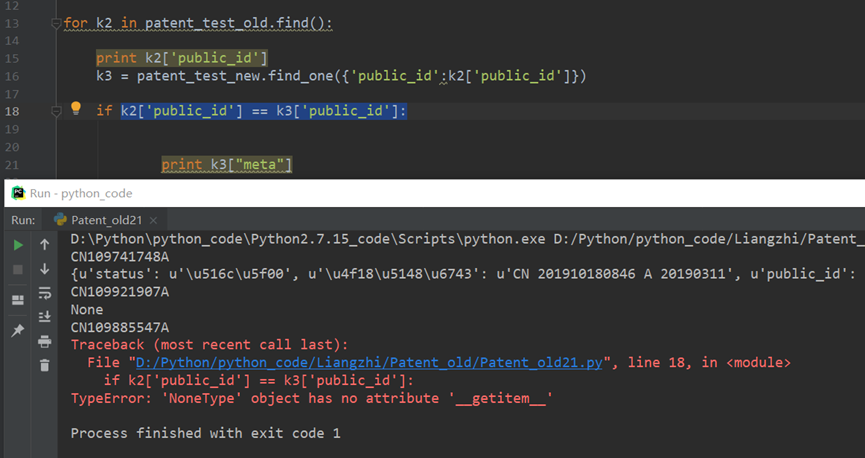
10.2
用if k2['public_id'] == k3['public']: 判断时报错,但k3不存在时会报错。
Nonetype 表示对象为空 对象不存在。
11.python操作mongodb插入修改新的数据库文件
import pymongo
localhost = pymongo.MongoClient(host='localhost',port=27017)
test2 = localhost.test2
patent_test_old = test2.patent_test_old
patent_test_new = test2.patent_test_new
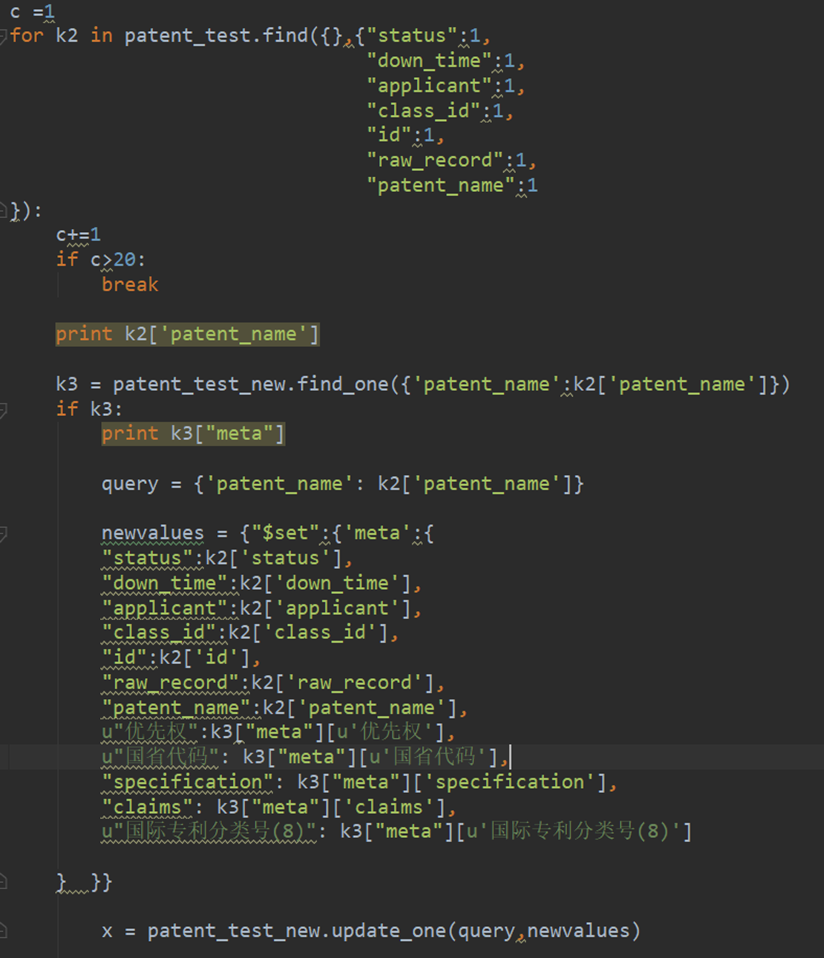
for k2 in patent_test_old.find():
print(k2['public_id'])
k3 = patent_test_new.find_one({'public_id':k2['public_id']})
if k3 :
#跳过无'meta'key值的列表
if k3['meta']:
#跳过无'meta'value值的列表
try:
print('update')
query = {'public_id': k2['public_id']}
newvalues = {"$set":{'meta':{
"status":k2['status'],
"down_time":k2['down_time'],
"applicant":k2['applicant'],
"class_id":k2['class_id'],
"id":k2['id'],
"raw_record":k2['raw_record'],
u"优先权":k3["meta"][u'优先权'],
u"国省代码": k3["meta"][u'国省代码'],
u"国际专利分类号(8)": k3["meta"][u'国际专利分类号(8)'],
"specification": k3["meta"]['specification'],
"claims": k3["meta"]['claims']
} }}
x = patent_test_new.update_one(query,newvalues)
except :
pass
else:
pass
else:
print('insert')
patent_test_new.insert_one(k2)
'''
map1 = {
"title": "patent_name",
"apply_num": "apply_number",
"publictime": "public_date",
"company_tag": "tag",
"pic_url": "img_url",
"lawStatus": "law_status",
"patentType": "patent_type",
"fulltext": "content",
"apply_time": "apply_date",
}
### 重新命名key值的名称,对应新的文件改旧的名字
patent_test_old.update_many({}, {"$rename" : map1})
print("-----------------------------")
'''
12.python操作mongo 堆栈
在电脑内存中修改文件名–出栈 .pop 压入push和 弹出pop
python中pop()将列表指定位置的元素移除,同时可以将移除的元素赋值给某个变量,不填写位置参数则默认删除最后一位。
pop()根据键将字典中指定的键值对删除,同时可以将删除的值赋值给变量
举个例子:
a = ["hello", "world", "dlrb"]
b = ["hello", "world", "dlrb"]
a.pop(1)
b1 = b.pop(0)
print(a)
print(b1)
输出结果:
['hello', 'dlrb']
Hello
将列表a的位置1的元素移除
将列表b的位置0的元素移除并赋值给变量b1
b = {
"name":"dlrb",
"age":25,
"height":168
}
b1 = b.pop("age")
print(b)
print(b1)
输出结果:
{'name': 'dlrb', 'height': 168}
25
13.更新内嵌数组(内嵌字段)
https://blog.csdn.net/hhy1107786871/article/details/87076163
Collection.update(query,newvalues)或Collection.update_one(query,newvalues)
更新一条文档,其中query为筛选条件,newvalue为更新的内容
多行注释快捷键:选中要注释的代码,按Ctrl+/

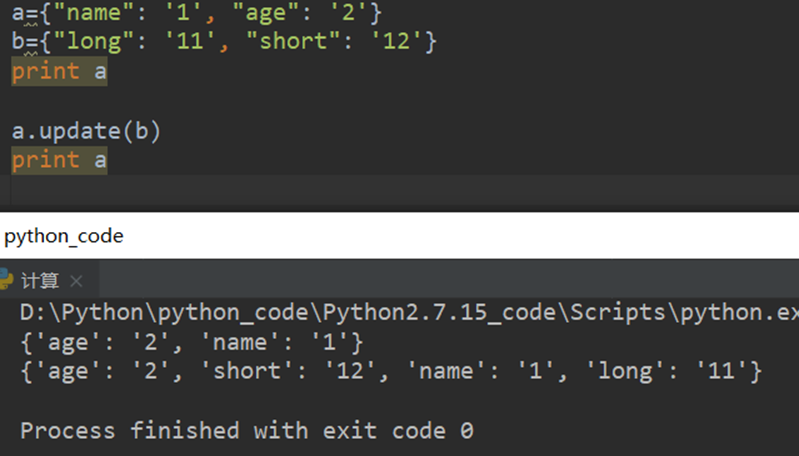
14.理解python .update函数
正确:
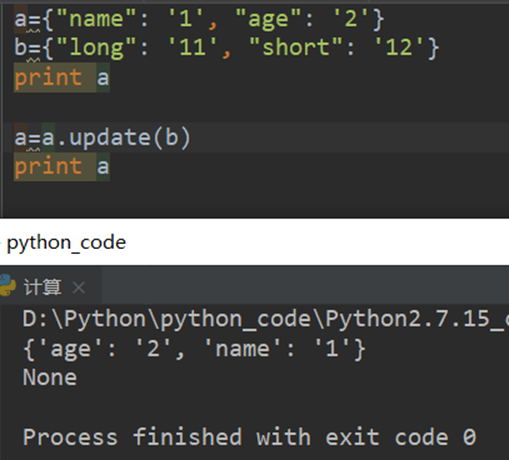
错误:
Python .update函数:
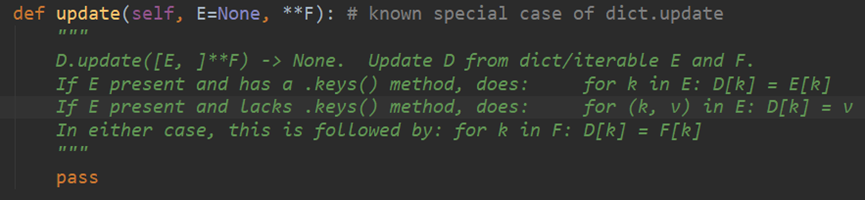
Return和 pass的区别,上图update最后pass什么都没做 所以输出none
15.完整python将patent_old集合修改并插入新的patent_new集合的代码
import pymongo
localhost = pymongo.MongoClient(host='localhost',port=27017)
test2 = localhost.test2
patent_test_old = test2.patent_test_old
patent_test_new = test2.patent_test_new
for k2 in patent_test_old.find():
print k2['public_id']
k3 = patent_test_new.find_one({'public_id':k2['public_id']})
if k3 :
#跳过无'meta'字段的列表
try:
if k3['meta']:
#跳过无'meta'值为null的列表
try:
print 'update'
query = {'public_id': k2['public_id']}
newvalues = {"$set":{'meta':{
"status":k2['status'],
"applicant":k2['applicant'],
"class_id":k2['class_id'],
"id":k2['id'],
"raw_record":k2['raw_record'],
u"优先权":k3["meta"][u'优先权'],
u"国省代码": k3["meta"][u'国省代码'],
u"国际专利分类号(8)": k3["meta"][u'国际专利分类号(8)'],
"specification": k3["meta"]['specification'],
"claims": k3["meta"]['claims']
} }}
x = patent_test_new.update_one(query,newvalues)
except :
query = {'public_id': k2['public_id']}
newvalues = {"$set": {'meta': {
"status": k2['status'],
"applicant": k2['applicant'],
"class_id": k2['class_id'],
"id": k2['id'],
"raw_record": k2['raw_record'],
}}}
x = patent_test_new.update_one(query, newvalues)
else:
query = {'public_id': k2['public_id']}
newvalues = {"$set": {'meta': {
"status": k2['status'],
"applicant": k2['applicant'],
"class_id": k2['class_id'],
"id": k2['id'],
"raw_record": k2['raw_record'],
}}}
x = patent_test_new.update_one(query, newvalues)
except:
query = {'public_id': k2['public_id']
newvalues = {"$set": {'meta': {
"status": k2['status'],
"applicant": k2['applicant'],
"class_id": k2['class_id'],
"id": k2['id'],
"raw_record": k2['raw_record'],
}}}
x = patent_test_new.update_one(query, newvalues)
###插入patent_test_old多的collection
else:
print 'insert'
#for each in k2:
# print each
### 重新命名key值的名称,对应新的文件改旧的名字
k2['patent_name'] = k2.pop('title')
k2['apply_number'] = k2.pop('apply_num')
k2['public_date'] = k2.pop('publictime')
k2['tag'] = k2.pop('company_tag')
k2['img_url'] = k2.pop('pic_url')
k2['content'] = k2.pop('fulltext')
k2['apply_date'] = k2.pop('apply_time')
k2['crawl_time'] = k2.pop('down_time')
try:
k2['law_status'] = k2.pop('lawStatus')
except:
k2['law_status'] = ''
try:
k2['patent_type'] = k2.pop('patentType')
except:
k2['patent_type'] = ''
oldtonew_meta_values = {'status':k2['status'],
'applicant':k2['applicant'],
'class_id':k2['class_id'],
'id':k2['id'],
'raw_record':k2['raw_record'],
}
k2['meta'] = oldtonew_meta_values
del(k2['status'],
k2['applicant'],
k2['class_id'],
k2['id'],
k2['raw_record'])
print("-----------------------------")
patent_test_new.insert_one(k2)
16.插入去重复
方法1: find_one
判断代码——如果代码突然出现情况,是否重复写入数据库
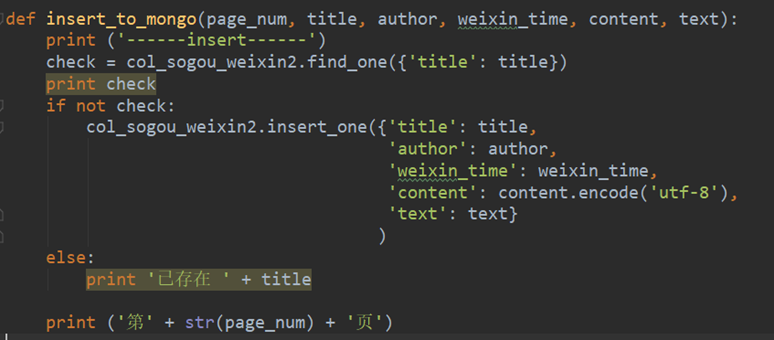
方法2: .count() > 1
mongo 去重复删除办法:操作科维网80+万条数据去重复
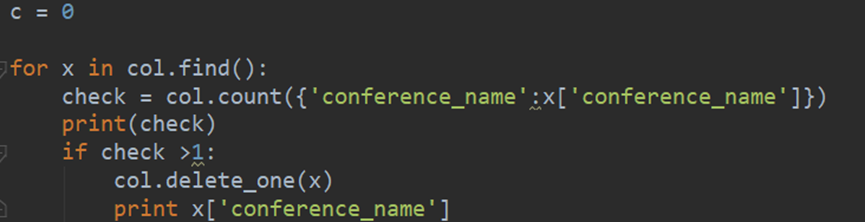
17.python 操作mongo统一字段名
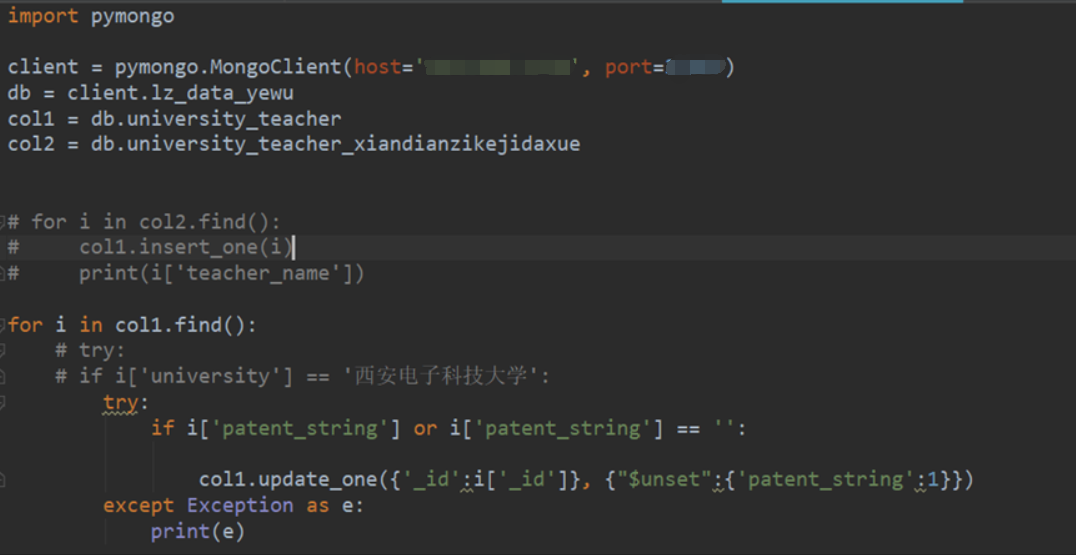
除去col1中某个字段:
col1.update_one({'_id':i['_id']},{"$unset":{'patent_string':1}})
重命名col1中某个key值:
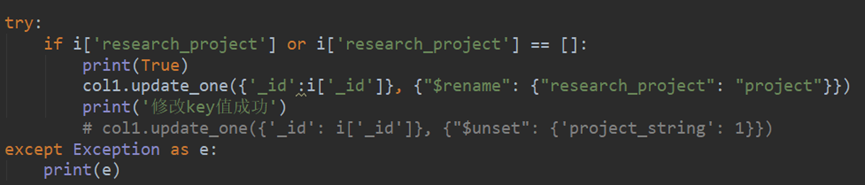
col1.update_one({'_id':i['_id']}, {"$rename": {"research_project": "project"}})
判断col1中是否存在某个key:
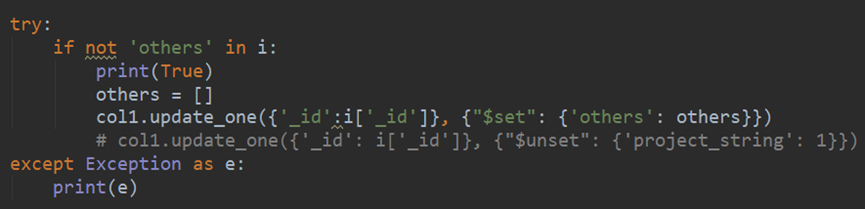
18.Python MongoDB操作记录
从一个数据库插入另一个数据库,不用写两遍。myquery的地方索引必须是一个字段名,不要是一个没有引号的字符串。
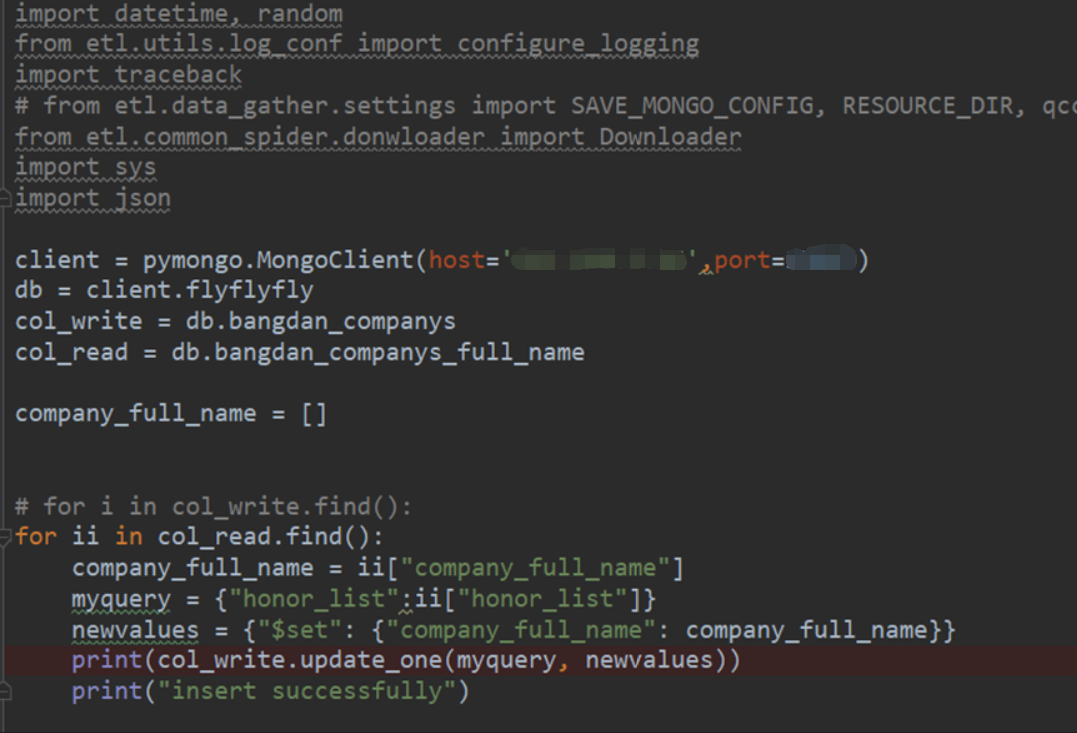
19.关于python mongo的连接 有账户和密码时候
import pymongo
client = pymongo.MongoClient('xxxx', 00000)
client.admin.authenticate("xxxx","xxxx")
db1 = client.res_kb_process
col1 = db1.res_kb_process_expert_lz_article
db2 = client.res_kb
col2 = db2.res_kb_expert_index
20.python 操作mongo 进行排序
for i in col.find().sort([('count', -1)]):
print(i)
21.python mongo 删除某个字段
'compound..'表示要删除的字段
col.update({'_id':i['_id']}, {'$unset':{'compound_split with_3':1}})
22.x.deleted_count 计算delete_many中删除的文档
我们可以使用 delete_many() 方法来删除多个文档,该方法第一个参数为查询对象,指定要删除哪些数据。
删除所有 name 字段中以 F 开头的文档:
#!/usr/bin/python3
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"]
myquery = { "name": {"$regex": "^F"} }
x = mycol.delete_many(myquery)
print(x.deleted_count, "个文档已删除")
输出结果为:
1 个文档已删除
删除集合中的所有文档
delete_many() 方法如果传入的是一个空的查询对象,则会删除集合中的所有文档:
#!/usr/bin/python3
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"]
x = mycol.delete_many({})
print(x.deleted_count, "个文档已删除")
输出结果为:
5 个文档已删除
Shell 命令
1.介绍
shell可以说是Linux命令集的概称,属于命令行的人机界面。shell是一个用C语言编写的程序,它是用户使用Linux的桥梁。shell既是一个命令语言,也是一个程序设计语言;其次,shell也指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
计算机操作的一般交互过程是: 图形界面 <=> Shell/应用程序 <=> 内核 <=> 硬件
硬件:负责具体运算的,如CPU、总线等
内核:CPU调度、内存管理等
Shell:类似Windows下的应用程序
界面:涵盖GUI等
补充:操作系统 就相当于 Shell + 界面
所以,在Linux中,Bash就是系统自带的Shell(App),直白点讲就是常用的命令行窗口。Shell包括Bash,但其他的专门指令操作,也可以集成为另一个Shell(某个命令如man就相当于一个应用程序,然后通过壳程序/命令行模式来调度)。
2.shell 备份文件 拷贝文件
#!/bin/bash
#将一个目录下的一些文件复制到另一个目录下 copy cp
cp /d/00_Shell/backup.txt ./test
#!/bin/bash
#将一个目录下的一些文件移动到另一个目录下
raw_dir="/home/liuyi/evt_test" #可修改绝对路径;
mkdir /home/liuyi/evt_bp #创建新的文件目录;
mv /email/file/error/$file /email/file/collection
#!/bin/bash
:<<!
编写一个脚本实现备份/var/log目录下的所有文件到/lianxi/jingzhou,
要求文件名包含当前日期,精确到秒,文件名例如:2022_3_13_10_58_20-log.tar.gz。
同时要求删除/lianxi/jingzhou目录下七天前的备份文件,只保留最近7天的
!
# 建立存放备份文件的目录
mkdir /lianxi/jingzhou -p
# 获取当前的时间
ctime=$(date +%Y_%m_%d_%H_%M_%S)
# 将/var/log下的文件备份到/lianxi/jingzhou
tar czf /lianxi/jingzhou/${ctime}-log.tar.gz /var/log &>/dev/null
# 找到/lianxi/jingzhou下七天前的备份文件,然后删除
find /lianxi/jingzhou -mtime +7 |xargs rm -rf
3.shell脚本判断文件是否存在
1、判断文件夹是否存在
#如果文件夹不存在,则创建文件夹
tempPath="/home/parasaga/blank"
if [ ! -d "$tempPath" ]; then
mkdir $blankPath
fi
2、判断文件是否存在
#如果文件不存在,则创建文件
tempFile="/home/parasaga/blank/error.log"
if [ ! -f "$tempFile" ]; then
touch $tempFile
fi
文件不存在则创建:
if [ ! -d "/data/" ];then
mkdir /data
else
echo "文件夹已经存在"
fi
文件存在则删除:
if [ ! -f "/data/filename" ];then
echo "文件不存在"
else
rm -f /data/filename
fi
判断文件夹是否存在:
if [ -d "/data/" ];then
echo "文件夹存在"
else
echo "文件夹不存在"
fi
判断文件是否存在:
if [ -f "/data/filename" ];then
echo "文件存在"
else
echo "文件不存在"
fi
-e 判断对象是否存在
-d 判断对象是否存在,并且为目录
-f 判断对象是否存在,并且为常规文件
-L 判断对象是否存在,并且为符号链接
-h 判断对象是否存在,并且为软链接
-s 判断对象是否存在,并且长度不为0
-r 判断对象是否存在,并且可读
-w 判断对象是否存在,并且可写
-x 判断对象是否存在,并且可执行
-O 判断对象是否存在,并且属于当前用户
-G 判断对象是否存在,并且属于当前用户组
-nt 判断file1是否比file2新 [ "/data/file1" -nt "/data/file2" ]
-ot 判断file1是否比file2旧 [ "/data/file1" -ot "/data/file2" ]
5.循环命令
while true
sleep 2s
do
echo "123"
done
6.git push 脚本
#!/bin/bash
while true
do
git status
echo "####### 开始自动Git #######"
current_time=$(date "+%Y/%m/%d -%H:%M:%S") # 获取当前时间
echo ${current_time} # 显示当前时间
git add .
git commit -m "modified ${current_time}" # 远程仓库可以看到是什么时间修改的...
git push origin master
echo "####### 自动Git完成 #######"
sleep 20s
done
7.shell脚本里的 #!/bin/bash
#!/bin/bash
echo "Hello World"
第 1 行的#!是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 shell;后面的/bin/bash就是指明了解释器的具体位置。
Shell 脚本中所有以#开头的都是注释(当然以#!开头的除外)。
Linux 基础 Linux 命令
1.Linux 连接工具 WinSCp, XShell, MobaXterm Professional
winscp 主要用于 window上把代码文件上传到 linux 的服务器上, 然后要重新启动 服务器上的linux 部署的 tomact
xsehll 是主用用于连接远端的服务器, 在window 上查看服务器上的代码, 采用的linux 的指令
MobaXterm Professional是两者的结合
连接远程Linux主机,上传和下载文件的方法
1.打开软件,在打开的页面填写远程主机的IP,用户名和密码,点击保存,会在页面的左边出现一个站点,下次可直接双击该站点,就可以登录到远程主机上了。
2.
2.Linux命令
Ubuntu sudo apt-get update sudo apt-get install
这个命令,会访问源列表里的每个网址,并读取软件列表,然后保存在本地电脑。我们在新立得软件包管理器里看到的软件列表,都是通过update命令更新的
2.1 linux查看程序,杀死程序
ps 查看进程
ps -ef|grep weixin.py
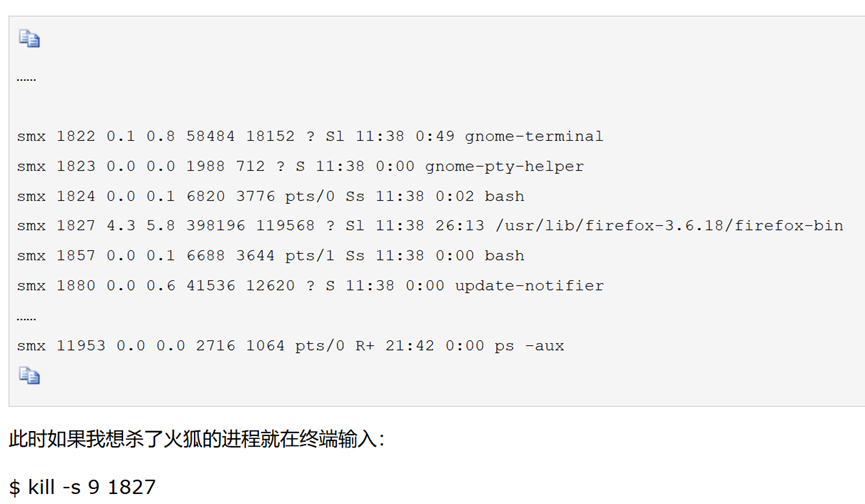
ps -ef|grep python
杀死某一个进程:
kill -s 9 pid
上面进程多了 看得眼花缭乱,不太容易找到目标服务,于是我们可以用管道符来定位一下
1、ps -ef | grep orderant
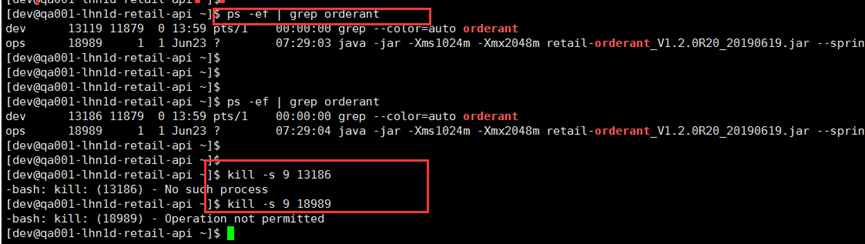
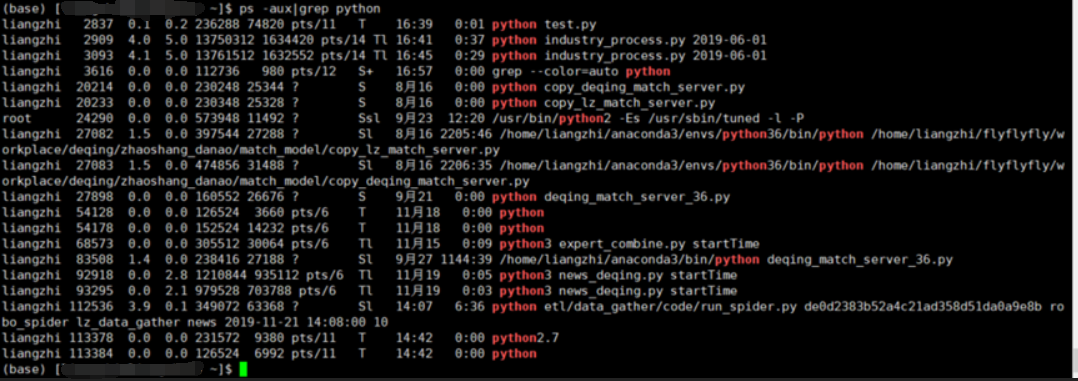
2.2 查看linux上面python的具体程序 ps -aux|grep python
2.3 查看当前空余内存: free -h

2.4 终止当前程序 ctrl+c
2.5 清空屏幕 clear
这个命令将会刷新屏幕,本质上只是让终端显示页向后翻了一页,如果向上滚动屏幕还可以看到之前的操作信息。一般都会使用这个命令。
3.PID的理解
每次新开启,系统都会分配一个PID,这个PID到进程结束之前是不会改变的。
ps -ef|grep 16923 查看该pid的进程的详细信息
top -p
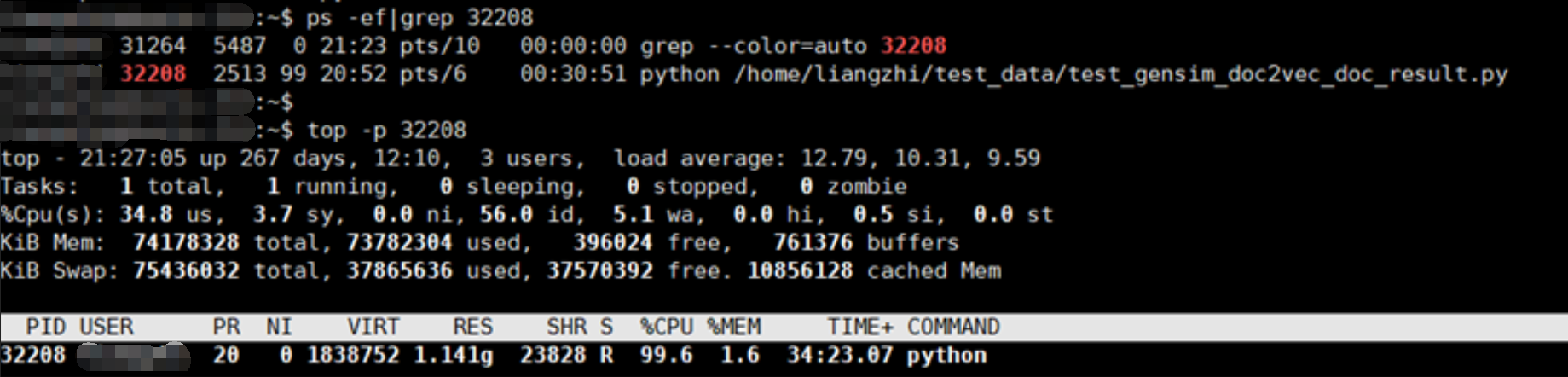
top -c 查看顶部进程详情
4.10个常用的linux命令

linux查看log文件输出:
tailf weike_news_spider_ea7bc96d48c545e8879a6c7a9552215b.log
cd changhuayu/TianPengTrans/log/
linxu查看python运行文件:
$ ps -aux | grep python
$ ps -ef | grep python
杀死进程:
5.linux 定位到指定目录
cd /home 进入根目录
cd jtx 进入下一个目录
cd / 进入根目录
cd ~ 进入用户家目录,比如root用户就进入到/root,比如zzz用户,就进入到/home/zzz
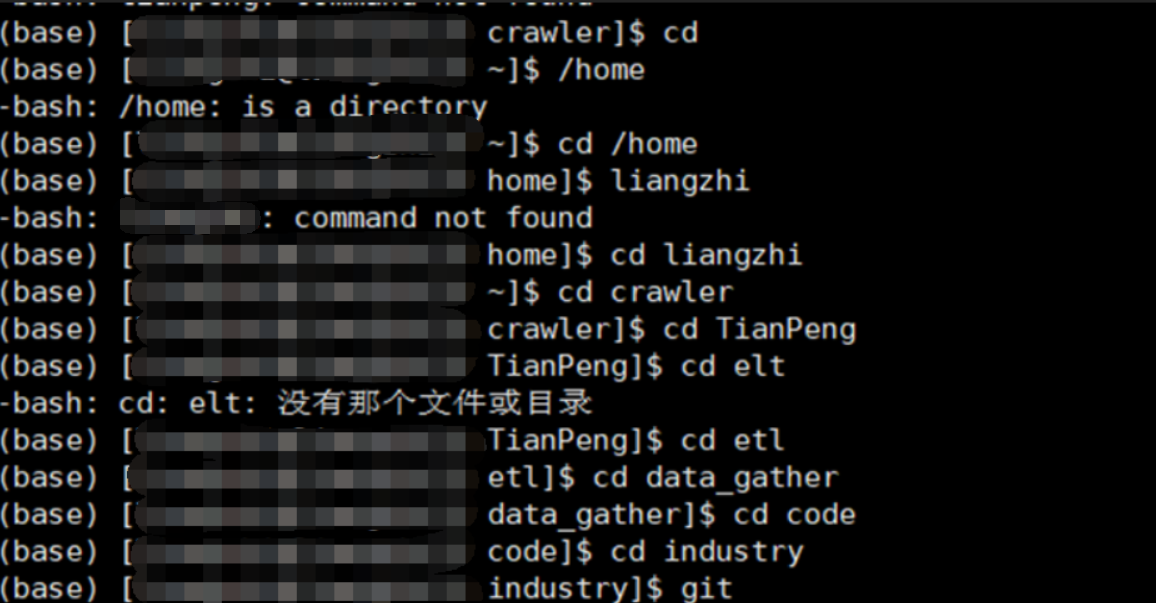
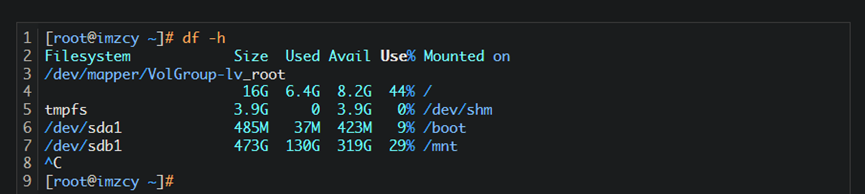
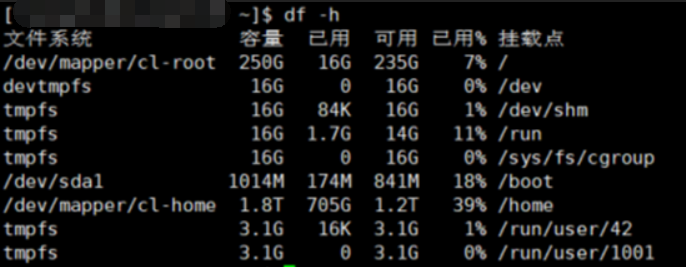
6.linux 查看服务器配置命令: df -h
https://www.imzcy.cn/1992.html
mongo里面的size是字节的意思
7.linux中ctrl+c,ctrl+z,ctrl+d的区别

7.1 Linux系统下ctrl+z挂起进程后怎么恢复
Linux系统下,不小心按了ctrl+z命令后,退出了当前进程的执行界面,程序没有结束,只是被挂起了。
通过ps命令可以查看进程信息,这里不做详细介绍,可通过jobs命令查看被挂起的进程号
jobs
通过fg命令可以恢复进程到前台执行、bg命令恢复进程到后台执行。
示例:
@ubuntu:~/project/test$ jobs
[1]+ Stopped ./gtest //显示进程1被挂起了
@ubuntu:~/project/test$ fg 1 //后面可以恢复进程继续执行
8.linux crontab命令
特殊字符的含义
*(星号) 代表任何时刻都接受。
,(逗号) 代表分隔时段的意思。
-(减号) 代表一段时间范围内。
/n(斜线) 那个 n 代表数字,每隔 n 单位间隔。
eg1: 每年的五月一日 10:5 执行一次
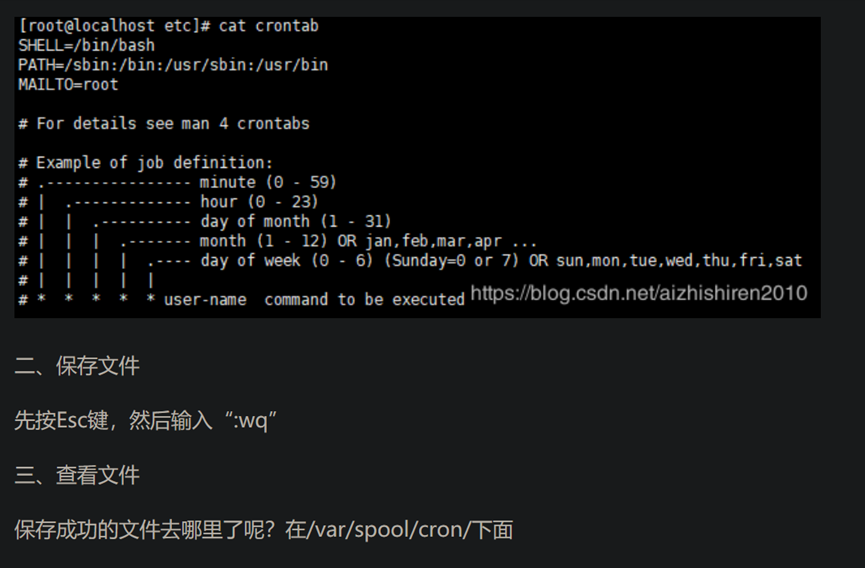
5 10 1 5 * command(要是执行网址(curl "http://网址"),或者执行其它的直接写路径)
eg2: 每天的三点,六点各执行一次
00 3,6 * * * command
eg3: 每天的8:20, 9:20,10:20,11:20各执行一次
20 8-11 * * * command
eg4: 每五分钟执行一次
*/5 * * * * command
eg5: 每周一十点执行一次
00 10 * * 1 command
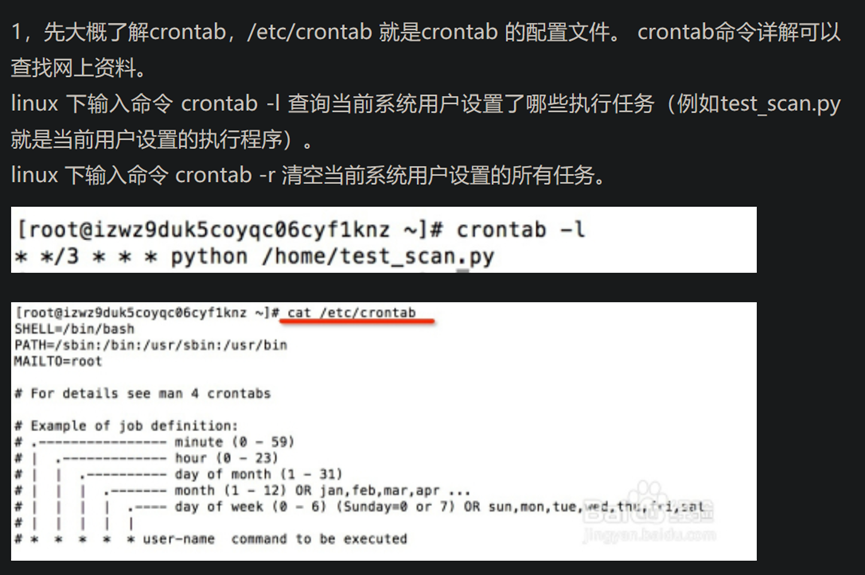
crontab -l

9.清空linux服务器上的nohup.out文件
命令:cp /dev/null /home/liangzhi/nohup.out
然后输入 y

说明:
nohup.out文件包含了通常发到终端显示器上的所有输出,输出会追加到现有的nohup.out文件中。如果用nohup同时运行了同目录中的多个命令,所有输出都将发送到同一个nohup.out文件中,输出结果会让人感到困惑。
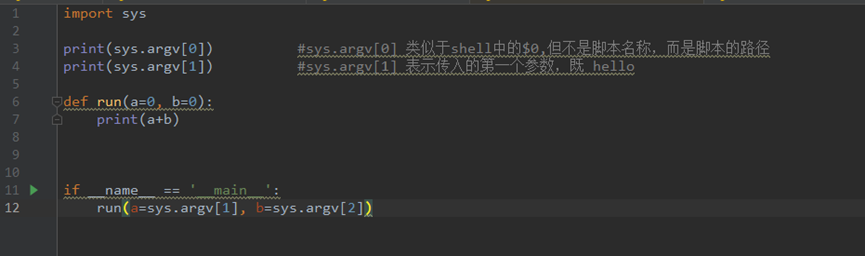
10.linux中给python 传参数
11.linux copy文件

./ 表示当前文件夹
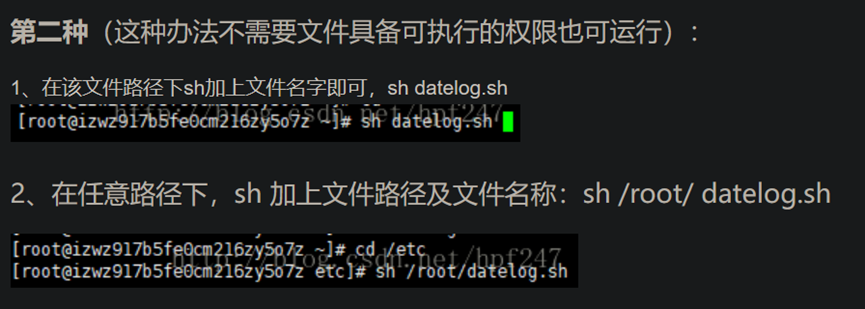
12.linux 执行sh文件
13.查看linux历史命令和时间
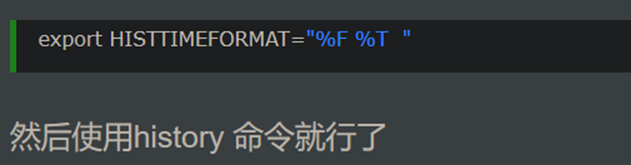
14.linux pid进程id号 ppid父进程id号

10427进程是 10084的子进程
15.linux 实时查看更新日志命令
tail -f file_path
https://www.cnblogs.com/wjlbk/p/11839360.html

很多时候在调试生成或正式平台服务器的时候想查看实时的日志输出,在Linux中可以使用tail 或 watch来实现。
比如我们项目中有个 app.log 的日志文件,我们普通读取都使用 vi app.log。但是要实时查看更新就得使用其他命令了。
• tail的使用
1 tail -f app.log
1. 命令格式;
tail[必要参数][选择参数][文件]
2. 命令功能:
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
3. 命令参数:
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示行数
–pid=PID 与-f合用,表示在进程ID,PID死掉之后结束.
-q, –quiet, –silent 从不输出给出文件名的首部
-s, –sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
• watch
1 watch -d -n 1 cat app.log
1. 命令格式:
watch[参数][命令]
2. 命令功能:
可以将命令的输出结果输出到标准输出设备,多用于周期性执行命令/定时执行命令
3. 命令参数:
-n或–interval watch缺省每2秒运行一下程序,可以用-n或-interval来指定间隔的时间。
-d或–differences 用-d或–differences 选项watch 会高亮显示变化的区域。 而-d=cumulative选项会把变动过的地方(不管最近的那次有没有变动)都高亮显示出来。
-t 或-no-title 会关闭watch命令在顶部的时间间隔,命令,当前时间的输出。
-h, –help 查看帮助文档
一般第一种就够用了
16.查看linux某个文件夹下面有多少个文件
查看bai目录下有多少个文件du及文件夹需在终端输入
ls |zhi wc -w
查看目录dao下有多少个文件需在终端4102输入
ls | wc -c
查看文1653件夹下有多少个文件,多少个子目录需在终端输入
ls -l |wc -l
若只想知道文件的个数,则需在终端输入
/bin/ls -l |grep ^-|wc -l
17.1. Linux Shell 1>/dev/null 2>&1 含义
https://blog.csdn.net/ithomer/article/details/9288353
shell中可能经常能看到:echo log > /dev/null 2>&1
命令的结果可以通过%>的形式来定义输出
/dev/null :代表空设备文件
> :代表重定向到哪里,例如:echo "123" > /home/123.txt
1 :表示stdout标准输出,系统默认值是1,所以">/dev/null"等同于"1>/dev/null"
2 :表示stderr标准错误
& :表示等同于的意思,2>&1,表示2的输出重定向等同于1
1 > /dev/null 2>&1 语句含义:
1 > /dev/null : 首先表示标准输出重定向到空设备文件,也就是不输出任何信息到终端,说白了就是不显示任何信息。
2>&1 :接着,标准错误输出重定向(等同于)标准输出,因为之前标准输出已经重定向到了空设备文件,所以标准错误输出也重定向到空设备文件。
实例解析:
cmd >a 2>a 和 cmd >a 2>&1 为什么不同?
cmd >a 2>a :stdout和stderr都直接送往文件 a ,a文件会被打开两遍,由此导致stdout和stderr互相覆盖。
cmd >a 2>&1 :stdout直接送往文件a ,stderr是继承了FD1的管道之后,再被送往文件a 。a文件只被打开一遍,就是FD1将其打开。
两者的不同点在于:
cmd >a 2>a 相当于使用了FD1、FD2两个互相竞争使用文件 a 的管道;
cmd >a 2>&1 只使用了一个管道FD1,但已经包括了stdout和stderr。
从IO效率上来讲,cmd >a 2>&1的效率更高。
经常可以在一些脚本,尤其是在crontab调用时发现如下形式的命令调用
/tmp/test.sh > /tmp/test.log 2>&1
前半部分/tmp/test.sh > /tmp/test.log很容易理解,那么后面的2>&1是怎么回事呢?
要解释这个问题,还是得提到文件重定向。我们知道>和<是文件重定向符。那么1和2是什么?
在shell中,每个进程都和三个系统文件 相关联:标准输入stdin,标准输出stdout、标准错误stderr,三个系统文件的文件描述符分别为0,1、2。所以这里2>&1 的意思就是将标准错误也输出到标准输出当中。
下面通过一个例子来展示2>&1有什么作用:
$ cat test.sh
t
date
test.sh中包含两个命令,其中t是一个不存在的命令,执行会报错,默认情况下,错误会输出到stderr。date则能正确执行,并且输出时间信息,默认输出到stdout
./test.sh > test1.log
./test.sh: line 1: t: command not found
$ cat test1.log
Wed Jul 10 21:12:02 CST 2013
可以看到,date的执行结果被重定向到log文件中了,而t无法执行的错误则只打印在屏幕上。
$ ./test.sh > test2.log 2>&1
$ cat test2.log
./test.sh: line 1: t: command not found
Tue Oct 9 20:53:44 CST 2007
这次,stderr和stdout的内容都被重定向到log文件中了。
实际上, > 就相当于 1> 也就是重定向标准输出,不包括标准错误。通过2>&1,就将标准错误重定向到标准输出了,那么再使用>重定向就会将标准输出和标准错误信息一同重定向了。如果只想重定向标准错误到文件中,则可以使用2> file。
linux shell 中"2>&1"含义脚本是:
nohup /mnt/Nand3/H2000G >/dev/null 2>&1 &
18.kill -15 linux命令
ctrl+c是终止当前在终端bai窗口中运行的命du令或脚本zhi,
kill -9 pid,是不顾后果dao的强制终止(如果zhuan的你的速度够快,有时候shu是和ctrl+c是一样的)
kill -15 pid,是先关闭和其有关的程序,再将其关闭
19.字体颜色 不出现 grep –color=auto
| ps -ef | grep aaa |

会显示 root 29701 14626 0 16:46 pts/2 00:00:00 grep –color=auto aaa
ps -ef|grep [a]aa

不会显示 grep –color=auto aaa
20.linux source命令
https://blog.csdn.net/violet_echo_0908/article/details/52056071
source命令作用
在当前bash环境下读取并执行FileName中的命令。
*注:该命令通常用命令“.”来替代。
举例:
Linux下读取一个activate文件,激活python环境
source tianpeng/bin/activate
21.linux上查看占用cpu进程 占用内存进程
https://www.linuxprobe.com/linux-sort-max-mc.html
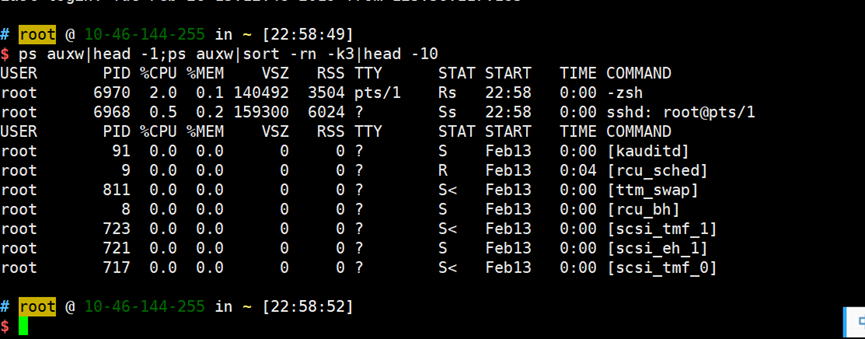
1.CPU占用最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k3|head -10
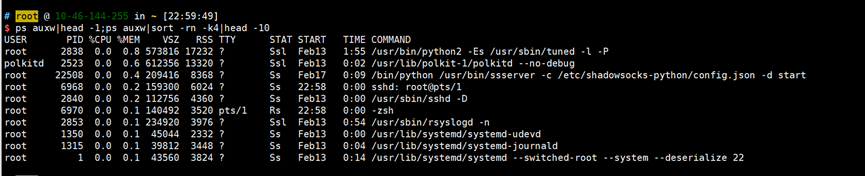
2.内存消耗最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k4|head -10
3.虚拟内存使用最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k5|head -10

4.也可以试试
ps auxw --sort=rss
ps auxw --sort=%cpu
5.看看几个参数含义
1. %MEM 进程的内存占用率
2. MAJFL is the major page fault count,
3. VSZ 进程所使用的虚存的大小
4. RSS 进程使用的驻留集大小或者是实际内存的大小(RSS is the "resident set size" meaning physical memory used)
5. TTY 与进程关联的终端(tty)
启动虚拟环境
在虚拟环境中输入ride.py,打开ride工具
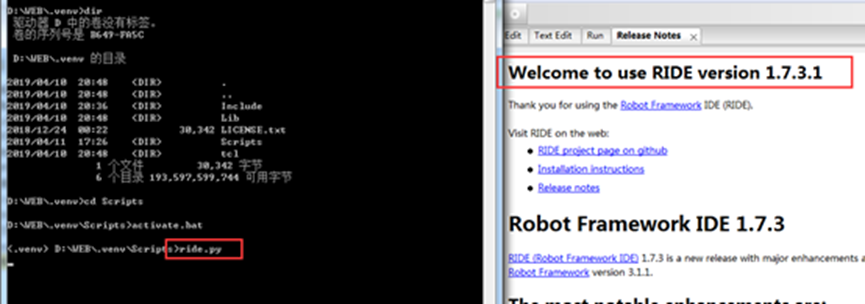
至此,虚拟的python运行环境就搭建好了。
22.pdftotext linux pdf转换成文本工具
https://blog.csdn.net/github_33934628/article/details/50815430

23.实时查看linux中gpu的使用情况
watch的基本用法是:
$ watch [options] command
最常用的参数是 -n, 后面指定是每多少秒来执行一次命令。
监视显存:我们设置为每 10s 显示一次显存的情况:
$ watch -n 10 nvidia-smi
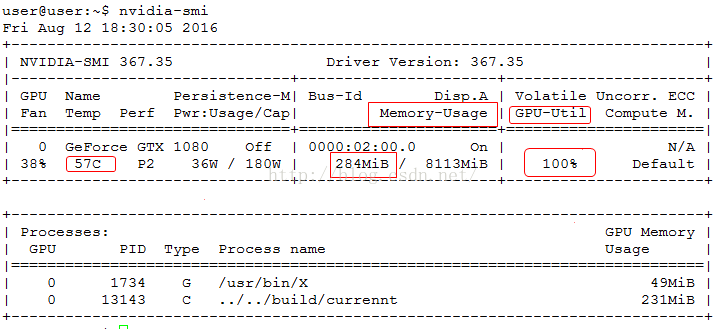
具体如下所示:重要的参数主要是温度、内存使用、GPU占有率,具体如下红框所示。
24.linux at命令 设置一次性定时任务
定时执行一次python文件
方法一:
at 19:00 # 进入内部命令模式
at > python test.py
ctrl + D #保存退出
方法二:
at now + 2 minutes
at > python test.py
ctrl + D #保存退出
at -l
at -c +(任务编号)
参考:https://blog.csdn.net/a1414345/article/details/74857226?utm_term=linux%E6%B7%BB%E5%8A%A0%E4%B8%80%E6%AC%A1%E6%80%A7%E5%AE%9A%E6%97%B6%E4%BB%BB%E5%8A%A1&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduweb~default-5-74857226&spm=3001.4430
25.linux get 请求es数据库 查询es数据
linux直接查es数据:
curl -X get localhost:9200/_index/_type/_id
curl -k -u admin:password -XGET localhost:9200/_index/_type/_id
加上headers 代替账号密码
curl -H "Authorization:Basic YWRXXXXXXXXXXXXX==" -X GET localhost:9200/_index/_type/_id
26.linux telnet命令
用于查看某个ip的某个接口是否是通的,是否是正常的
安装telnet
安装服务 yum install telnet –y 启动服务 service xinetd restart
查看远方服务器ssh端口是否开放:
telnet 192.168.25.133 22

27.linux 动态监控gpu的使用情况
这里推荐一个好用的小工具:gpustat, 直接pip install gpustat即可安装,gpustat 基于nvidia-smi,可以提供更美观简洁的展示,结合 watch 命令,可以动态实时监控GPU 的使用情况。

28.conda python 环境切换
环境切换 通过conda activate 进行环境切换 通过conda deactivate退出环境 如,进入futu环境: conda activate futu
29.linux中的&&和&,|和||
| 在linux中,&和&&, | 和 | 介绍如下: |
& 表示任务在后台执行,如要在后台运行redis-server,则有 redis-server &
&& 表示前一条命令执行成功时,才执行后一条命令 ,如 echo ‘1‘ && echo ‘2’
| 表示管道,上一条命令的输出,作为下一条命令参数,如 echo ‘yes’ | wc -l |
| 表示上一条命令执行失败后,才执行下一条命令,如 cat nofile | echo “fail” |
30.linux echo命令
先介绍下linux中echo命令的使用
echo是打印变量的值或者给定的字符串,
比如,输入echo hello或者echo “hello”都是在控制台打印出hello单词
但是我们需要把打印出来的字符串记录到文本文件中,就需要>和»命令
touch a.txt 新建一个文本文件a.txt
echo hello > a.txt
则a.txt中会记录下hello,但是如果再次执行echo hello > a.txt。则会覆盖之前的hello,
怎样追加呢?需要»命令
echo world » a.txt 则a.txt中会记录的是hello word,但是hello和word不是写在一行的,
而是每个单词占用一行的。
再比如 echo $HOME 控制台则会打印出当前用户的根路径/home/picc4
linux相关环境配置
1. Centos7 更换为网易YUM源
当我们刚刚安装系统的时候 yum 的速度那是真滴慢所以我们就需要一个更加快速的镜像,这时候网易镜像带给我们便捷。下面来一起更换吧!
备份当前的 yum 源(可选)
# yum 源在目录 /etc/yum.repos.d/ 下
$ cd /etc/yum.repos.d/
$ cp CentOS-Base.repo CentOS-Base.repo_bak
查看当前的版本然后去网易 centos 镜像下载 repo 包
这里我给出几个 centos 7 centos 6 centos 5
$ cat /etc/redhat-release
# 我的是 7.5 的本地虚拟机
CentOS Linux release 7.5.1804 (Core)
# 我这里没有 yum 环境所以我只能使用 curl作为下载工具 [-O 要大写]
$ curl -O http://mirrors.163.com/.help/CentOS7-Base-163.repo
# 修改下载的 CentOS7-Base-163.repo 名称为 CentOS7-Base.repo
$ mv CentOS7-Base-163.repo CentOS-Base.repo
mv:是否覆盖"CentOS-Base.repo"? Y
重新生成缓存
yum clean all
yum makecache
测试一下
$ yum repolist
# 这里展示的 163.com,所以我成功了。
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
源标识 源名称 状态
base/7/x86_64 CentOS-7 - Base - 163.com 10,019
extras/7/x86_64 CentOS-7 - Extras - 163.com 409
updates/7/x86_64 CentOS-7 - Updates - 163.com 2,076
repolist: 12,504
2.linux python前环境配置 python3.6配置
1.安装Python前的库环境
yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel -y
2.下载Python源码包
cd /opt/
wget https://www.python.org/ftp/python/3.6.2/Python-3.6.2.tgz
3.安装Python
tar -zxvf Python-3.6.2.tgz -C /usr/local
cd /usr/local/Python-3.6.2
vim Modules/Setup.dist
去掉以下四行注释
_socket socketmodule.c
_ssl _ssl.c \
-DUSE_SSL -I$(SSL)/include -I$(SSL)/include/openssl \
-L$(SSL)/lib -lssl -lcrypto
./configure --prefix=/usr/local/python3
make && make install
4.设置软连接
ln -s /usr/local/python3/bin/python3.6 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
5.查看python3版本以及pip3版本
python3
pip3 -V
6.更新pip3版本
pip3 install --upgrade pip
3.linux安装tesseract
https://www.jianshu.com/p/b0a3defa8ea5 https://blog.csdn.net/diyiday/article/details/80004793 https://www.pianshen.com/article/9026369424/
centos下安装:
1.安装centos7系统依赖
yum install -y automake autoconf libtool gcc gcc-c++
yum install -y libpng-devel libjpeg-devel libtiff-devel
yum -y install python-devel
yum -y install openssl-devel
yum -y install opencv
yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel
yum install -y libffi libffi-devel
yum install libmount -y
2 安装leptonica
下载leptonica-1.78,下载地址:http://www.leptonica.org/source/leptonica-1.78.0.tar.gz
解压并安装
tar -xzvf leptonica-1.78.0.tar.gz
cd leptonica-1.78.0
./configure
make && make install
安装完成后,配置环境变量
在 /etc/profile文件尾部添加
export LD_LIBRARY_PATH=/usr/local/lib
export LIBLEPT_HEADERSDIR=/usr/local/include
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig
或者利用如下命令向 /etc/profile文件添加内容
echo "export LD_LIBRARY_PATH=/usr/local/lib" >> /etc/profile
echo "export LIBLEPT_HEADERSDIR=/usr/local/include" >> /etc/profile
echo "export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig" >> /etc/profile
添加tesseract环境变量
PATH=$PATH:/usr/local/bin
export PATH
使配置立即生效
source /etc/profile
3 安装tesseract-ocr
下载tesseract-ocr4.0,下载地址:https://github.91chifun.workers.dev//https://github.com/tesseract-ocr/tesseract/archive/4.0.0.tar.gz
解压并安装
tar -xzf tesseract-4.0.0.tar.gz
cd tesseract-4.0.0
./autogen.sh
./configure
make && make install
ldconfig
下载OCR识别字符集
cd /usr/local/share/tessdata
wget https://hub.fastgit.org/tesseract-ocr/tessdata/raw/master/eng.traineddata
wget https://hub.fastgit.org/tesseract-ocr/tessdata/raw/master/chi_sim.traineddata
wget https://hub.fastgit.org/tesseract-ocr/tessdata/raw/master/chi_sim_vert.traineddata
测试tesseract-ocr4.0是否可用,分别输入tesseract --version、tesseract和tesseract --list-langs,如果能出现如下界面,则说明tesseract安装成功。
tesseract版本
tesseract 帮助文档
tesseract已安装语言包
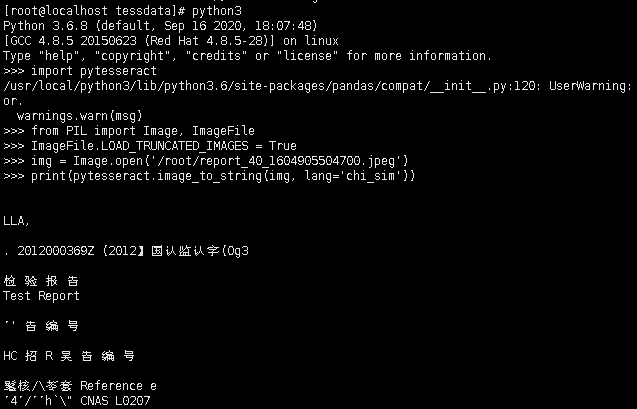
4 安装pytesseract pip install pytesseract
安装完成后,我们就可以利用python调用tesseract-ocr接口来识别图片了。
import pytesseract
from PIL import Image
img=Image.open('test.png')
print(pytesseract.image_to_string(img,lang='chi_sim'))
image.png
Vim命令
1.Vim模式介绍与命令合集
https://www.jianshu.com/p/3604d85710c6
Vim6种基本的模式:
• 普通模式
Vim强大的编辑能来自于其普通模式命令。在普通模式中,用的编辑器命令,比如移动光标,删除文本等等。这也是Vim启动后的默认模式。
• 插入模式
在这个模式中,大多数按键都会向文本缓冲中插入文本。
• 命令模式
在命令行模式中可以输入会被解释成并执行的文本。例如执行命令(:键),搜索(/和?键)或者过滤命令(!键)。在命令执行之后,Vim返回到命令行模式之前的模式,通常是普通模式。
• 可视模式(Visual mode)
这个模式与普通模式比较相似。但是移动命令会扩大高亮的文本区域。高亮区域可以是字符、行或者是一块文本。当执行一个非移动命令时,命令会被执行到这块高亮的区域上。Vim的"文本对象"也能和移动命令一样用在这个模式中。
• 选择模式(Select mode)
这个模式和无模式编辑器的行为比较相似(Windows标准文本控件的方式)。这个模式中,可以用鼠标或者光标键高亮选择文本,不过输入任何字符的话,Vim会用这个字符替换选择的高亮文本块,并且自动进入插入模式。
• Ex模式(Ex mode)
这和命令行模式比较相似,在使用:visual命令离开Ex模式前,可以一次执行多条命令。
我们最常用到就是普通模式、插入模式和命令行模式。
2.linux vim 快速注释 和 去注释代码

3.linux vim 查看文件编码 和 编码转换
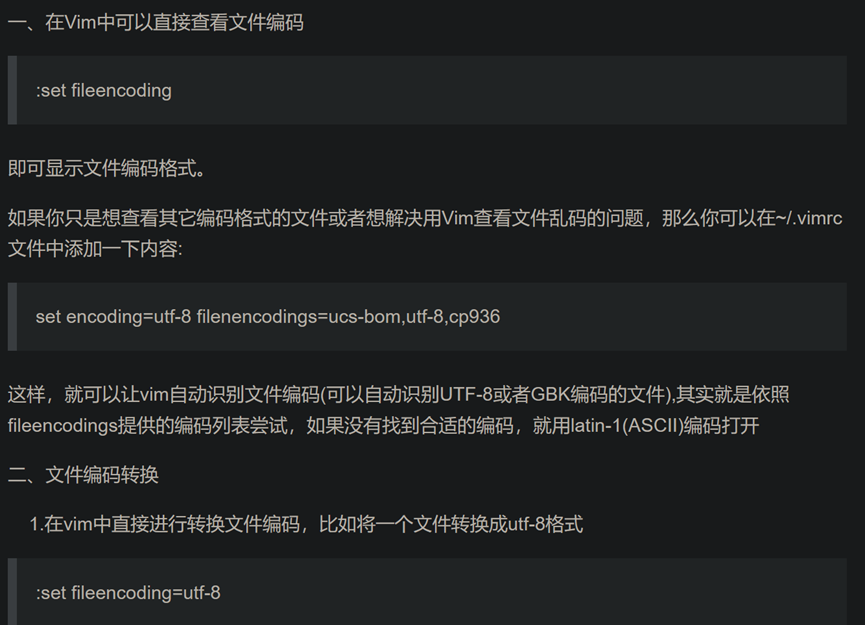
4.linux vim 跳到文本的最后一行:按“G”,即“shift+g”
vi操作
1.跳到文本的最后一行:按“G”,即“shift+g”
2.跳到最后一行的最后一个字符 : 先重复1的操作即按“G”,之后按“$”键,即“shift+4”。
3.跳到第一行的第一个字符:先按两次“g”,
4.跳转到当前行的第一个字符:在当前行按“0”。
5.vi加密。进入vi,输入":" + "X" 之后就提示你输入两次密码。
6.文件重新载入 :e!
7.单行复制 将光标移到复制行 按 'yy'进行复制
8.多行复制 将光标移到复制首行 按 'nyy'进行复制 n=1.2.3.4。。。。。
9.粘贴 将光标移到粘贴行 按 'p'进行粘贴
10.查找 /pattern Enter
5.linux 进入vim和退出vim
1) :w 保存文件但不退出vi
2) :w file 将修改另外保存到file中,不退出vi
3) :w! 强制保存,不推出vi
4) :wq 保存文件并退出vi
5) :wq! 强制保存文件,并退出vi
6) :q 不保存文件,退出vi
7) :q! 不保存文件,强制退出vi
8) :e! 放弃所有修改,从上次保存文件开始再编辑
6.linux vim 查看某个文件某一行
vim + 文件位置
然后按 : + 行数
: + a 开始修改
: + w 保存
: + q 退出
: + wq 保存并退出

7.Linux vim 快捷键
涉及在linux命令行下进行快速移动光标、命令编辑、编辑后执行历史命令、Bang(!)命令、控制命令等。让basher更有效率。
• 常用
1. ctrl+左右键:在单词之间跳转
2. ctrl+a:跳到本行的行首
3. ctrl+e:跳到页尾
4. Ctrl+u:删除当前光标前面的文字 (还有剪切功能)
5. ctrl+k:删除当前光标后面的文字(还有剪切功能)
6. Ctrl+L:进行清屏操作
7. Ctrl+y:粘贴Ctrl+u或ctrl+k剪切的内容
8. Ctrl+w:删除光标前面的单词的字符
9. Alt – d :由光标位置开始,往右删除单词。往行尾删
说明
• Ctrl – k: 先按住 Ctrl 键,然后再按 k 键;
• Alt – k: 先按住 Alt 键,然后再按 k 键;
• M – k:先单击 Esc 键,然后再按 k 键。
移动光标
• Ctrl – a :移到行首
• Ctrl – e :移到行尾
• Ctrl – b :往回(左)移动一个字符
• Ctrl – f :往后(右)移动一个字符
• Alt – b :往回(左)移动一个单词
• Alt – f :往后(右)移动一个单词
• Ctrl – xx :在命令行尾和光标之间移动
• M-b :往回(左)移动一个单词
• M-f :往后(右)移动一个单词
编辑命令
• Ctrl – h :删除光标左方位置的字符
• Ctrl – d :删除光标右方位置的字符(注意:当前命令行没有任何字符时,会注销系统或结束终端)
• Ctrl – w :由光标位置开始,往左删除单词。往行首删
• Alt – d :由光标位置开始,往右删除单词。往行尾删
• M – d :由光标位置开始,删除单词,直到该单词结束。
• Ctrl – k :由光标所在位置开始,删除右方所有的字符,直到该行结束。
• Ctrl – u :由光标所在位置开始,删除左方所有的字符,直到该行开始。
• Ctrl – y :粘贴之前删除的内容到光标后。
• ctrl – t :交换光标处和之前两个字符的位置。
• Alt + . :使用上一条命令的最后一个参数。
• Ctrl – _ :回复之前的状态。撤销操作。
Ctrl -a + Ctrl -k 或 Ctrl -e + Ctrl -u 或 Ctrl -k + Ctrl -u 组合可删除整行。
Bang(!)命令
• !! :执行上一条命令。
• ^foo^bar :把上一条命令里的foo替换为bar,并执行。
• !wget :执行最近的以wget开头的命令。
• !wget:p :仅打印最近的以wget开头的命令,不执行。
• !$ :上一条命令的最后一个参数, 与 Alt - . 和 $_ 相同。
• !* :上一条命令的所有参数
• !*:p :打印上一条命令是所有参数,也即 !*的内容。
• ^abc :删除上一条命令中的abc。
• ^foo^bar :将上一条命令中的 foo 替换为 bar
• ^foo^bar^ :将上一条命令中的 foo 替换为 bar
• !-n :执行前n条命令,执行上一条命令: !-1, 执行前5条命令的格式是: !-5
查找历史命令
• Ctrl – p :显示当前命令的上一条历史命令
• Ctrl – n :显示当前命令的下一条历史命令
• Ctrl – r :搜索历史命令,随着输入会显示历史命令中的一条匹配命令,Enter键执行匹配命令;ESC键在命令行显示而不执行匹配命令。
• Ctrl – g :从历史搜索模式(Ctrl – r)退出。
控制命令
• Ctrl – l :清除屏幕,然后,在最上面重新显示目前光标所在的这一行的内容。
• Ctrl – o :执行当前命令,并选择上一条命令。
• Ctrl – s :阻止屏幕输出
• Ctrl – q :允许屏幕输出
• Ctrl – c :终止命令
• Ctrl – z :挂起命令
重复执行操作动作
• M – 操作次数 操作动作 : 指定操作次数,重复执行指定的操作。
cmd命令
1.cmd回到根目录
cmd.exe对话框中如何返回上一级,如何返回根目录?
返回上一级 输入 cd.. 回车
返回根目录 输入 cd\ 回车
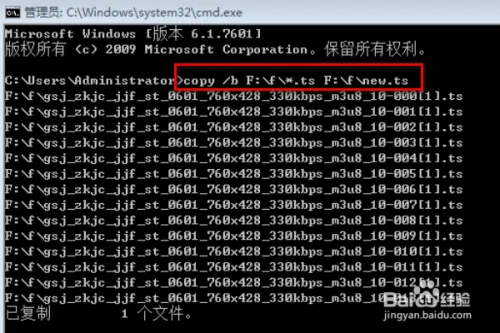
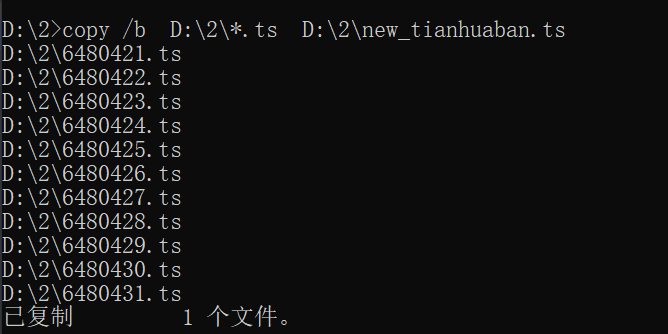
2.合并多个ts文件
copy /b F:\f*.ts E:\f\new.ts
https://jingyan.baidu.com/article/d45ad1489e84d528542b8072.html
将要合成的ts文件放在同一个文件夹下,ts文件的排序要有一定的规则,最简单的就是:1.ts、2.ts、3.ts等。
然后cmd输入命令 copy /b F:\f\*.ts E:\f\new.ts
Pyhton的数据类型
https://www.cnblogs.com/snaildev/p/7544558.html
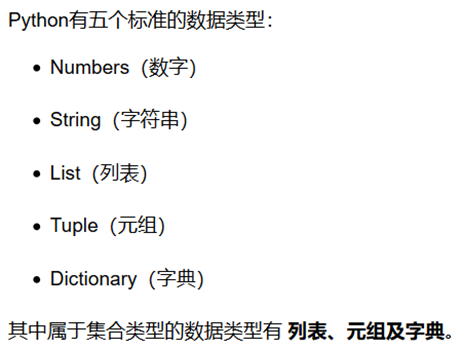
字典(dictionary)是除列表以外Python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。
print(c["inventor"])
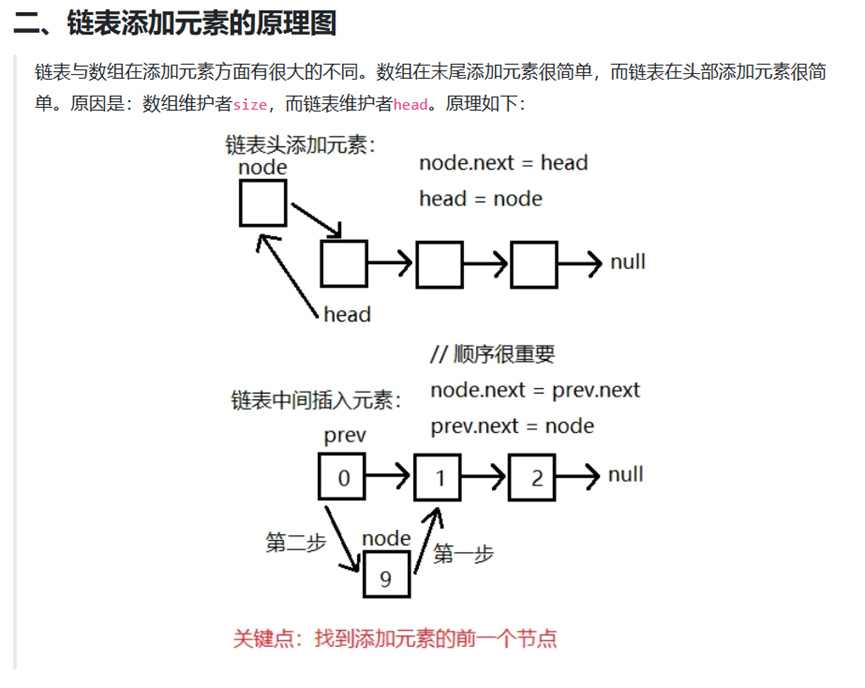
Data Structure and Algorithm 数据结构和算法
1.链表 (Linked List)
1.1 概念
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。链表可以在多种编程语言中实现。像Lisp和Scheme这样的语言的内建数据类型中就包含了链表的存取和操作。程序语言或面向对象语言,如C,C++和Java依靠易变工具来生成链表。

当数据量不大时(比如只有一万个数据),顺序表在所有方面的表现全都优于链表。就连在插入和删除时也是如此。因为链表插入新的结点要构造对象,这是非常耗时的;而在删除时,同于现代的计算机进行复制操作的效率极高,因为表现不比链表差。链表删除时还要执行析构操作,所以会慢不少。当顺序表长度大于一定的值时,插入和删除操作速度就会变得不如链表。链表的缺点主要在于按元素序号随机访问时效率低下。一些其它数据结构,比如图和树,在形式上也类似链表。(当然也有基于顺序表的实现)
1.2 链表和数组的区别
https://zhuanlan.zhihu.com/p/52440208
在知道同类数据的数量范围且不超过静态内存容许值时用数组,编程简单快速。 当你处理权的同类数据的数据量未知时,或者数据量超过静态数组定义范围时,就要用链表。
=============================
普通数组在用户的静态数据空间中分配内存,链表在操作系统的堆中动态分配内存。
从逻辑结构上来说,这两种数据结构都属于线性表。所谓线性表,就是所有数据都排列在只有一个维度的“线”上,就像羊肉串一样,把数据串成一串。对其中任意一个节点来说,除了头尾,只有一个前趋,也只有一个后继。
从物理上来说,即在内存中,这两种逻辑结构所对应的物理存储分布上看,数组占用的是一块连续的内存区,而链表在内存中,是分散的,因为是分散的,就需要一种东西把他们串起来,这样才能形成逻辑上的线性表,不像数组,与生俱来具有“线性”的成分。因为链表比数组多了一个“串起来”的额外操作,这个操作就是加了个指向下个节点的指针,所以对于链表来说,存储一个节点,所要消耗的资源就多了。也正因为这种物理结构上的差异,导致了他们在访问、增加、删除节点这三种操作上所带来的时间复杂度不同。
对于访问,数组在物理内存上是连续存储的,硬件上支持“随机访问”,所谓随机访问,就是你访问一个a[3]的元素与访问一个a[10000],使用数组下标访问时,这两个元素的时间消耗是一样的。但是对于链表就不是了,链表也没有下标的概念,只能通过头节点指针,从每一个节点,依次往下找,因为下个节点的位置信息只能通过上个节点知晓(这里只考虑单向链表),所以访链表中的List(3)与List(10000),时间就不一样了,访问List(3),只要通过前两个节点,但要想访问List(10000),不得不通过前面的9999个节点;而数组是一下子就跳到了a[10000],无需逐个访问a[10000]之前的这些个元素。所以对于访问,数组和链表时间复杂度分别是O(1)与O(n),方式一种是“随机访问”,一种是“顺序访问”。
1.3 静态链表和动态链表
静态链表和动态链表是线性表链式存储结构的两种不同的表示方式。
1、静态链表是用类似于数组方法实现的,是顺序的存储结构,在物理地址上是连续的,而且需要预先分配地址空间大小。所以静态链表的初始长度一般是固定的,在做插入和删除操作时不需要移动元素,仅需修改指针。
2、动态链表是用内存申请函数(malloc/new)动态申请内存的,所以在链表的长度上没有限制。动态链表因为是动态申请内存的,所以每个节点的物理地址不连续,要通过指针来顺序访问。
静态链表:静态链表就是长度大小固定的,链式存储的线性表。
链式存储结构:它不要求逻辑上相邻的元素在物理位置上也相邻.因此它没有顺序存储结构所具有的弱点,但也同时失去了顺序表可随机存取的优点.
–静态链表–
使用静态链表存储数据,需要预先申请足够大的一整块内存空间,也就是说,静态链表存储数据元素的个数从其创建的那一刻就已经确定,后期无法更改。
比如,如果创建静态链表时只申请存储 10 个数据元素的空间,那么在使用静态链表时,数据的存储个数就不能超过 10 个,否则程序就会发生错误。
不仅如此,静态链表是在固定大小的存储空间内随机存储各个数据元素,这就造成了静态链表中需要使用另一条链表(通常称为”备用链表”)来记录空间存储空间的位置,以便后期分配给新添加元素使用,如图 2 所示。
这意味着,如果你选择使用静态链表存储数据,你需要通过操控两条链表,一条是存储数据,另一条是记录空闲空间的位置。
–动态链表–
使用动态链表存储数据,不需要预先申请内存空间,而是在需要的时候才向内存申请。也就是说,动态链表存储数据元素的个数是不限的,想存多少就存多少。
同时,使用动态链表的整个过程,你也只需操控一条存储数据的链表。当表中添加或删除数据元素时,你只需要通过 malloc 或 free 函数来申请或释放空间即可,实现起来比较简单。
1.4 如何判断链表是否有环
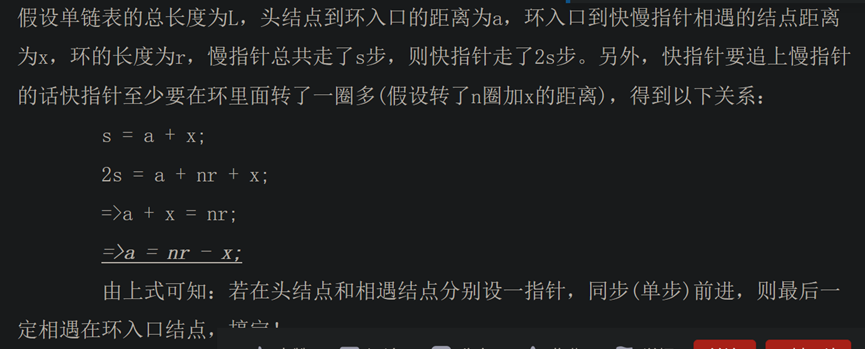
https://www.jianshu.com/p/95cd7eb17856

问题3的证明:
1.5 链表&跳表
https://blog.csdn.net/ian_she/article/details/104345037
2.堆, 栈
3.指针
编程语言中的一个对象
在计算机科学中,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接指向(points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。因此,将地址形象化的称为“指针”。意思是通过它能找到以它为地址的内存单元。 [1] 在高级语言中,指针有效地取代了在低级语言,如汇编语言与机器码,直接使用通用暂存器的地方,但它可能只适用于合法地址之中。指针参考了存储器中某个地址,通过被称为反参考指针的动作,可以取出在那个地址中存储的值。作个比喻,假设将电脑存储器当成一本书,一张内容记录了某个页码加上行号的便利贴,可以被当成是一个指向特定页面的指针;根据便利粘贴面的页码与行号,翻到那个页面,把那个页面的那一行文字读出来,就相当于是对这个指针进行反参考的动作。
在信息工程中指针是一个用来指示一个内存地址的计算机语言的变量或中央处理器(CPU)中寄存器(Register)【用来指向该内存地址所对应的变量或数组】。指针一般出现在比较接近机器语言的语言,如汇编语言或C语言。面向对象的语言如Java一般避免用指针。指针一般指向一个函数或一个变量。在使用一个指针时,一个程序既可以直接使用这个指针所储存的内存地址,又可以使用这个地址里储存的函数的值。
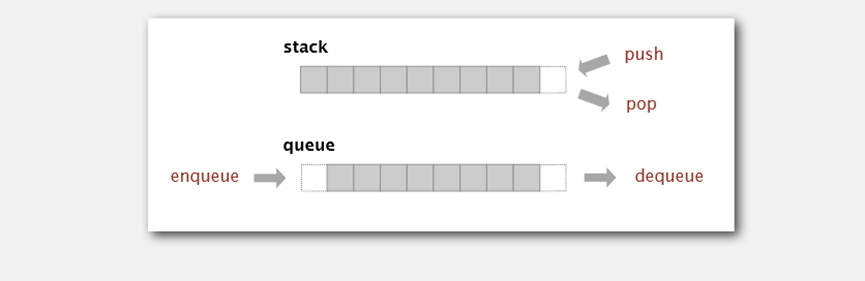
4.队列 (Queue)
4.1 概念
https://www.jianshu.com/p/5dac973feda2
队列(Queue)也是一种运算受限的线性表。它只允许在表的一端进行插入,而在另一端进行删除。允许删除的一端称为队头(front),允许插入的一端称为队尾(rear)。先进先出(FIFO)。
题目:
队列的应用--击鼓传花大逃杀
题目描述
你和你的 39 个同学外出露营,晚上无聊时,大家围在火堆边做游戏。游戏规则如下:40人围成一个圈,其中一人被指定为第一个人,顺时针报数到第七人,就将他杀死。之后,下一个活着的人继续报数,每次都是杀死第七个人。直到只剩一人时,游戏结束。如果你并不想死,那么应该坐到哪里才能成为最后一人?(假设第一个报数者的位置记为1)
解题思路
如果能想到将这个问题抽象为一个简单队列的问题,那么就已经解决了一大半。
报数而不被杀的人:相当于从队首出队再从队尾入队;
被杀的人:只出队;
留到最后的人:当队列长度为1时,再出队一次,返回。
def dataosha(name_list, kill_num=7):
"""击鼓传花大逃杀"""
Q = Queue()
for name in name_list:
Q.enqueue(name)
while Q.size() > 1:
for _ in range(kill_num - 1): # 这里没有用到_,只是为了循环而已
Q.enqueue(Q.dequeue())
print("Kill:", Q.dequeue())
return Q.dequeue()
name_list = []
for i in range(40):
name_list.append(i + 1)
print("Safe number:", dataosha(name_list))
队列是一种有次序的数据集合,其特征是新数据项的添加总发生在一端(通常称为“尾 rear”端),而现存数据项的移除总发生在另一端(通常称为“首front”端)。
当数据项加入队列,首先出现在队尾,随着队首数据项的移除,它逐渐接近队首。
队列特征
(1)先进先出或先到先服务;
(2)队列只有一个入口和一个出口。
(3)不允许数据项直接插入队中,也不允许从中间移除数据项。
4.2 Python3中 deque队列、list、栈的区别
https://blog.csdn.net/qq_34979346/article/details/83540389
deque是Python中stack和queue的通用形式,也就是既能当做栈使用,又能当做双向队列,list是单向队列.
队列和栈是两种数据结构,其内部都是按照固定顺序来存放变量的,二者的区别在于对数据的存取顺序:
• 队列是,先存入的数据最先取出,即“先进先出”。
• 栈是,最后存入的数据最先取出,即“后进先出”。

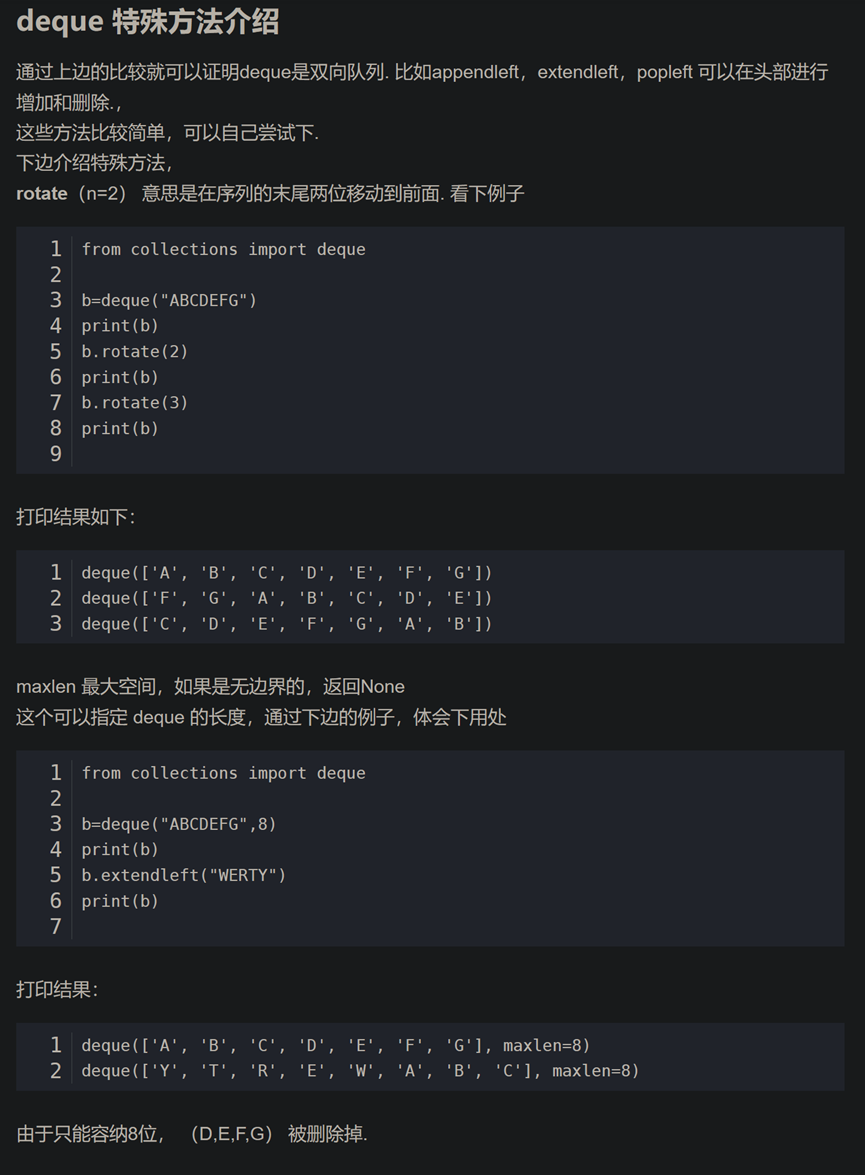
5.树 trie
5.1 概念
https://www.cnblogs.com/ceo-python/p/11625093.html
一、树的定义
树形结构是一类重要的非线性结构。树形结构是结点之间有分支,并具有层次关系的结构。它非常类似于自然界中的树。
树的递归定义:
树(Tree)是n(n≥0)个结点的有限集T,T为空时称为空树,否则它满足如下两个条件:
(1)有且仅有一个特定的称为根(Root)的结点;
(2)其余的结点可分为m(m≥0)个互不相交的子集Tl,T2,…,Tm,其中每个子集本身又是一棵树,并称其为根的子树(Subree)。
二、二叉树的定义
二叉树是由n(n≥0)个结点组成的有限集合、每个结点最多有两个子树的有序树。它或者是空集,或者是由一个根和称为左、右子树的两个不相交的二叉树组成。
特点:
(1)二叉树是有序树,即使只有一个子树,也必须区分左、右子树;
(2)二叉树的每个结点的度不能大于2,只能取0、1、2三者之一;
(3)二叉树中所有结点的形态有5种:空结点、无左右子树的结点、只有左子树的结点、只有右子树的结点和具有左右子树的结点。
树的前 中 后 序 遍历
https://blog.csdn.net/weixin_41275510/article/details/82287948 非线性结构 每个元素可以有多个前驱和后继
5.1 有树根
6.基础数据结构总汇
https://blog.csdn.net/qq_33414271/article/details/78516443

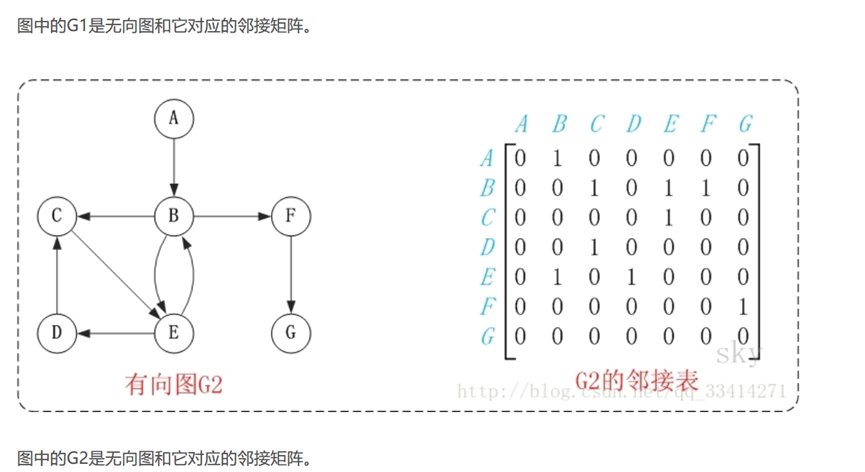
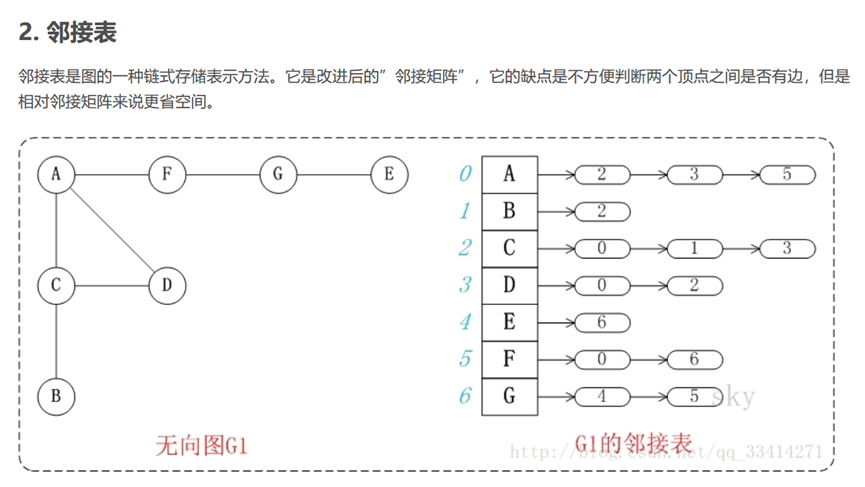
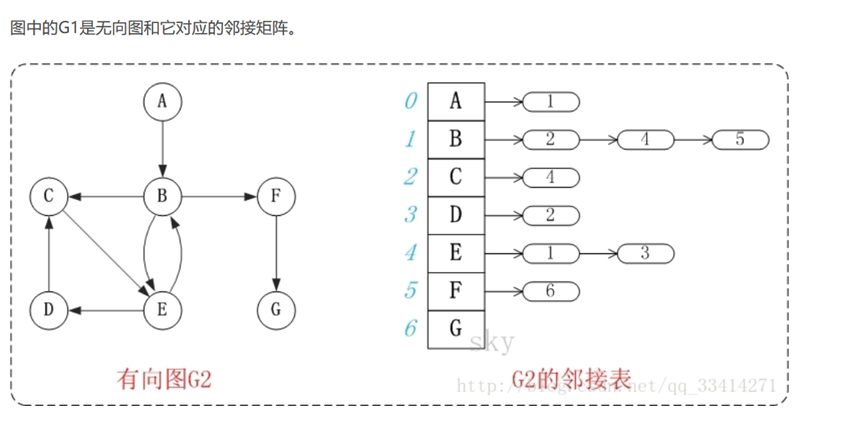
7.图 Graph
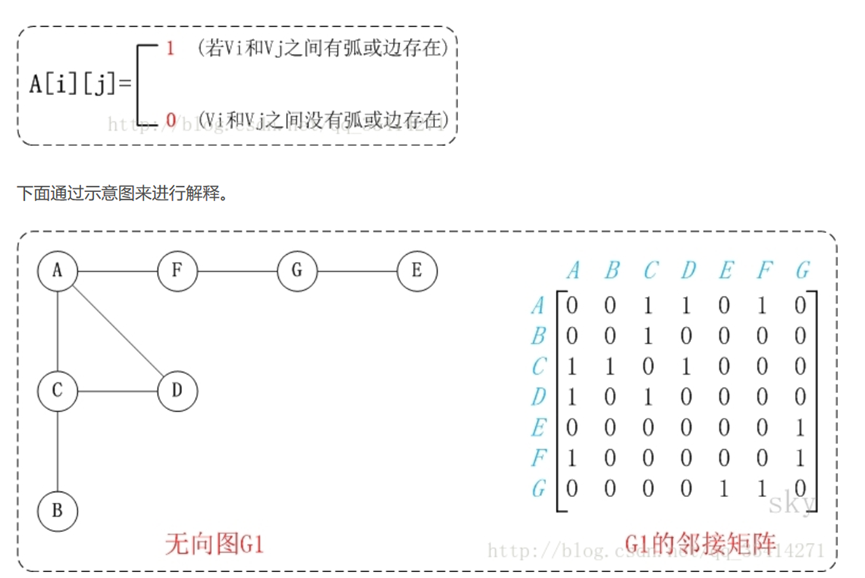
图由顶点和边组成。如果图中顶点是有序的,则称之为有向图。
由顶点组成的序列,称为路径。
除了可以对图进行遍历外,还可以搜索图中任意两个顶点之间的最短路径。
在python中,可利用字典 {键:值} 来创建图。
图中的每个顶点,都是字典中的键,该键对应的值为“该顶点所指向的图中其他的顶点”。
有向图,无向图
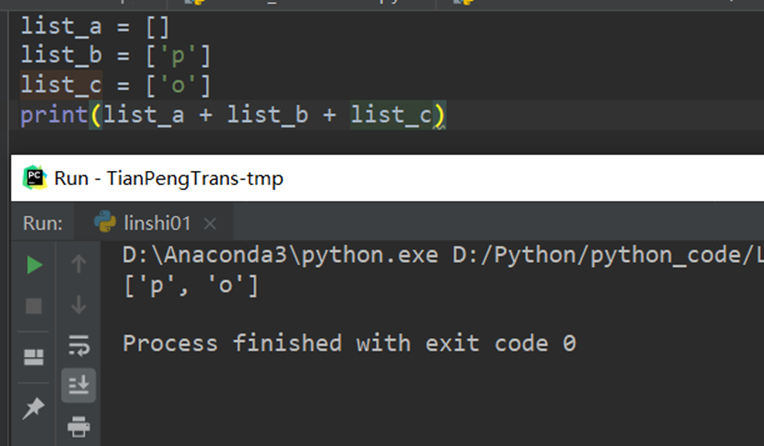
列表相加:
8.线性表
线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。数据元素是一个抽象的符号,其具体含义在不同的情况下一般不同。
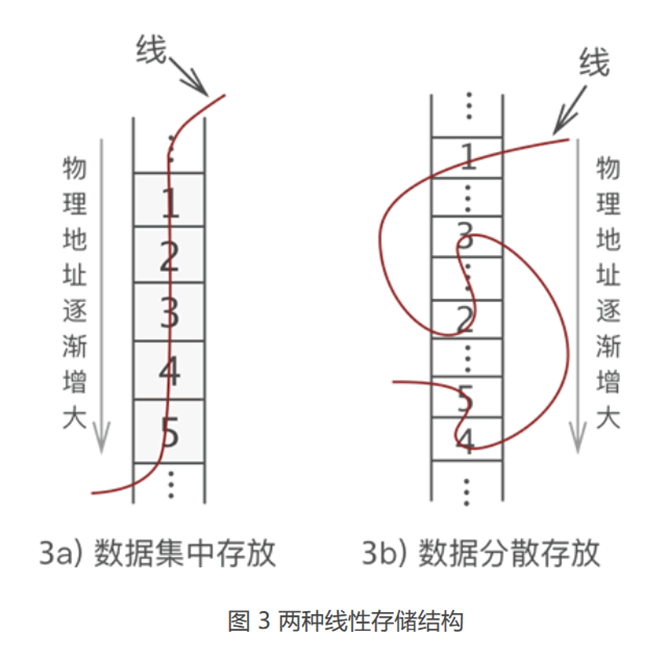
将具有“一对一”关系的数据“线性”地存储到物理空间中,这种存储结构就称为线性存储结构(简称线性表)。
使用线性表存储的数据,如同向数组中存储数据那样,要求数据类型必须一致,也就是说,线性表存储的数据,要么全不都是整形,要么全部都是字符串。一半是整形,另一半是字符串的一组数据无法使用线性表存储。
前驱元素和后继元素

9.序列
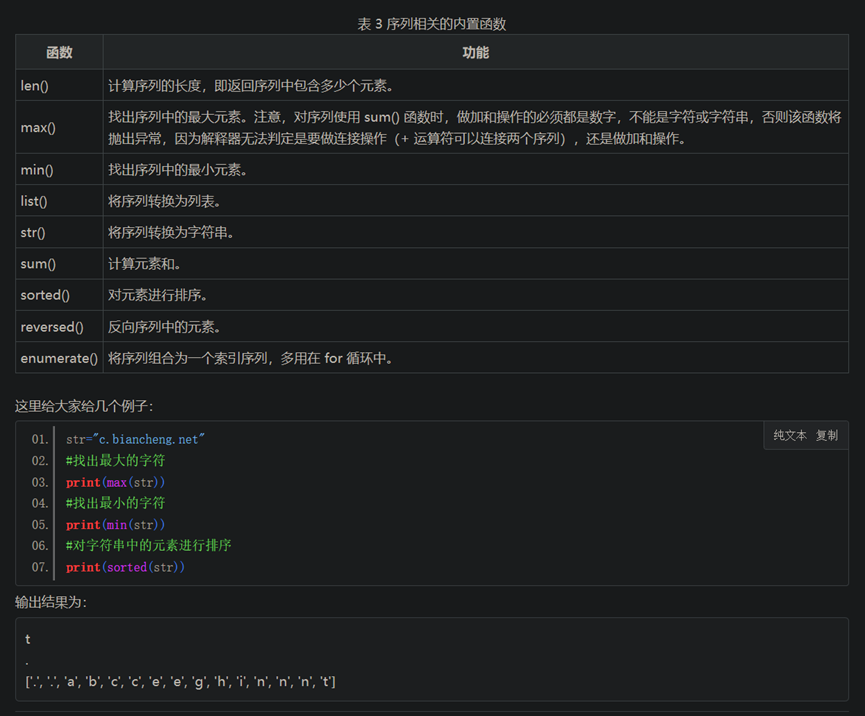
所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。
为了更形象的认识序列,可以将它看做是一家旅店,那么店中的每个房间就如同序列存储数据的一个个内存空间,每个房间所特有的房间号就相当于索引值。也就是说,通过房间号(索引)我们可以找到这家旅店(序列)中的每个房间(内存空间)。
10.# JSON 数据结构
https://blog.csdn.net/sinat_17775997/article/details/80667381
JSON支持的数据类型:
浮点表示(浮点数):即小数的位数可动 ,如:3.12*e2, 0.312*e3
nall表示0
json对象和json字符串的区别和相互转换
json对象,首先说到对象的概念,对象的属性是可以用:对象.属性进行调用的
数据类型: 嵌套对象、数组、字符串、数字、布尔值或空值。
布尔值(Booleans)是一个逻辑值,只有true和false。
嵌套,指的是在已有的表格、图像或图层中再加进去一个或多个表格、图像或图层,亦或两个物体有装配关系时,将一个物体嵌入另一物体的方法。可理解为镶嵌、套用。
JSON解析两条规则:1.如果看到是{ }–>使用JSONObject 2.如果看到的[ ]–>使用JSONArray解析
较为复杂的键值对: 
11.快速排序
https://www.cnblogs.com/sfencs-hcy/p/10602598.html
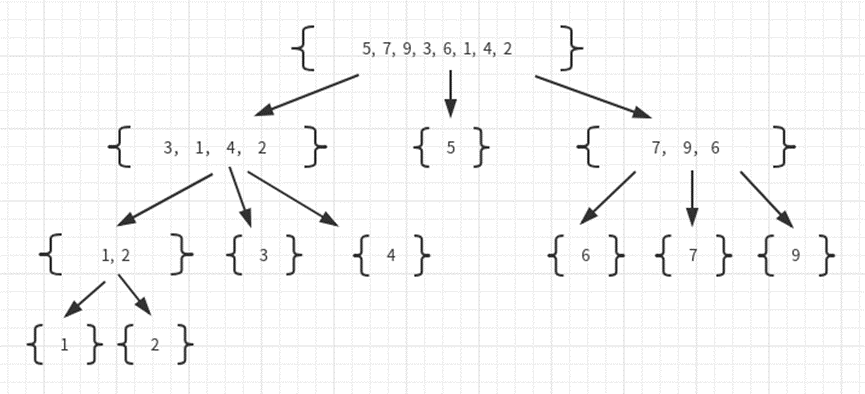
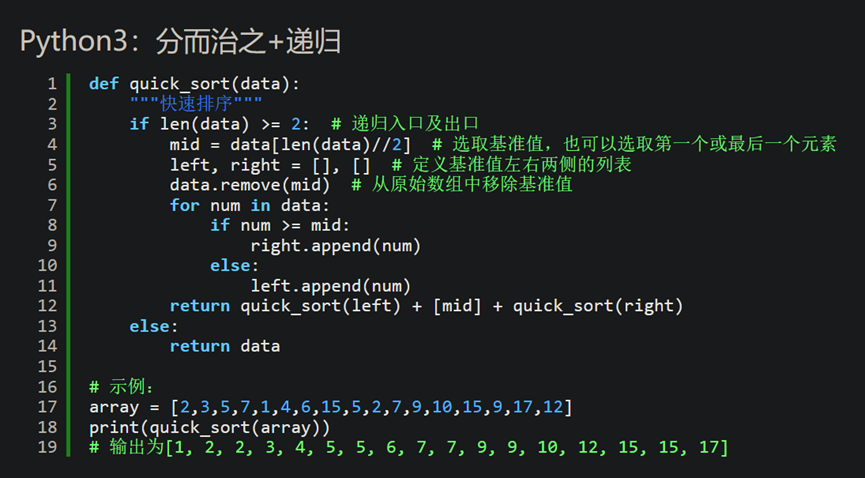
快速排序的实现同样使用分治法,它的原理是从序列中选择一个值作为基准值,然后分成比基准值小的序列集合和比基准值小的序列集合和与基准值相等的序列集合。
–时间复杂度–
理想的情况是,每次划分所选择的中间数恰好将当前序列几乎等分,经过log2n趟划分,便可得到长度为1的子表。这样,整个算法的时间复杂度为O(nlog2n)。 最坏的情况是,每次所选的中间数是当前序列中的最大或最小元素,这使得每次划分所得的子表中一个为空表,另一子表的长度为原表的长度-1。这样,长度为n的数据表的快速排序需要经过n趟划分,使得整个排序算法的时间复杂度为O(n2)。
快速排序的时间复杂度有最优情况与最坏情况
最优情况为每一次的基准值都正好为序列的中位数,时间复杂度为nlog(n)
最坏情况为每一次的基准值都恰好是序列的最大值或最小值,时间复杂度为n^2。有意思的是如果每次选第一个数做基准值,但每次这个数又是最小值,那么序列本身就是有序的,但时间复杂度也是最高的
要想
要想优化时间复杂度,基准值的选择很关键,可以使用类似的从序列中选几个数,再求出他们的中位数做基准值
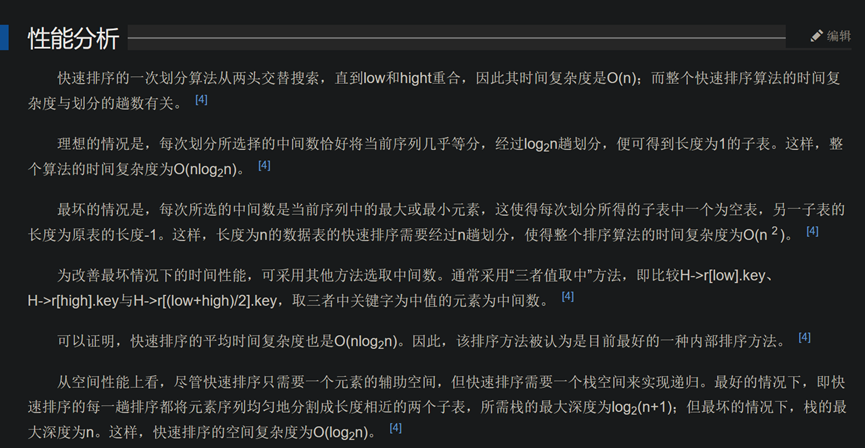
–空间复杂度–
空间复杂度:用来评估算法内存占用大小的一个式子

12.归并排序

分治法的思想:分解,解决,合并
Ps: 伪代码(Pseudocode)是一种非正式的,类似于英语结构的,用于描述模块结构图的语言。
13.插入算法
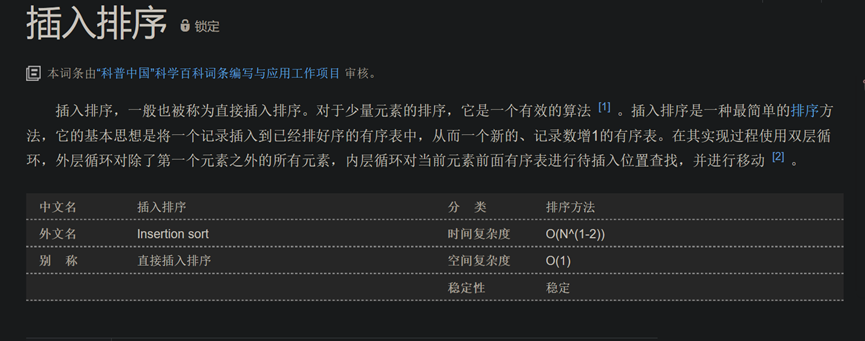
def insertionSort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
arr = [12, 11, 13, 5, 6]
insertionSort(arr)
print("排序后的数组:")
for i in range(len(arr)):
print("%d" % arr[i])
14.算法 时间复杂度 空间复杂度
15.B+ 树
计算机基础知识
1.锚文本
2.重定向
重定向(Redirect)就是通过各种方法将各种网络请求重新定个方向转到其它位置(如:网页重定向、域名的重定向、路由选择的变化也是对数据报文经由路径的一种重定向)。
样式1:
样式2:
2.1 JS转跳和301、302http转跳
JS转跳是浏览器解析页面时候,通过执行JS脚本,将当前页面转跳到另外一个页面,需要浏览器支持JS脚本的运行,对一些网页爬虫不起作用。
301是通过HTTP协议进行转跳,更加标准和通用。
301是永久定向转 如果你是从老域名换新域名建议用301 JS不太利于优化。302是临时转跳。
3.时间戳 timestamp
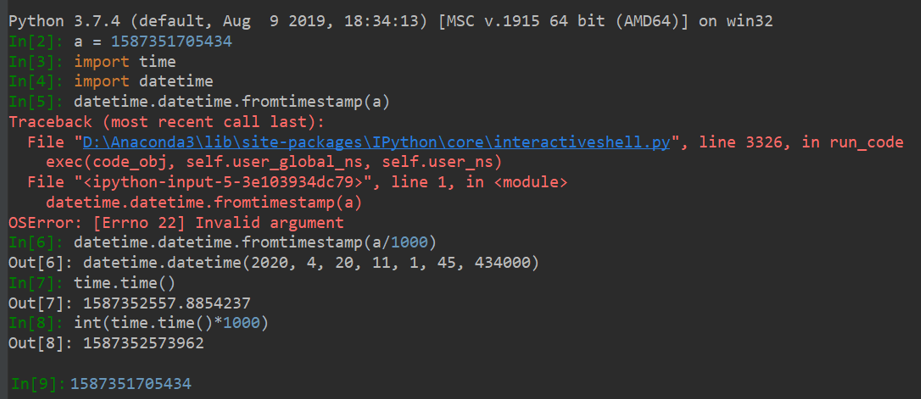
时间戳转成指定字符串
https://blog.csdn.net/qdPython/article/details/123696118
strftime:根据传入格式
datetime.now().strftime(‘%Y-%m-%d’)
4.同步接口与异步接口
同步需要等待,异步不需要等待

5.shell和终端
shell是(与核心交互的)语言,”终端”是shell的操作界面
Shell是系统的用bai户界面,提供了用户与内核进行交du互操作的一种接口。它接收用户输zhi入的命令并把它送入内核dao去执行。
实际上Shell是一个命令解释器,它解释由用户输入的命令并且把它们送到内核。不仅如此,Shell有自己的编程语言用于对命令的编辑,它允许用户编写由shell命令组成的程序。Shell编程语言具有普通编程语言的很多特点,比如它也有循环结构和分支控制结构等,用这种编程语言编写的Shell程序与其他应用程序具有同样的效果。
Linux提供了像Microsoft Windows那样的可视的命令输入界面(也就是你说的终端),Window是图形用户界面(GUI)。它提供了很多窗口管理器。
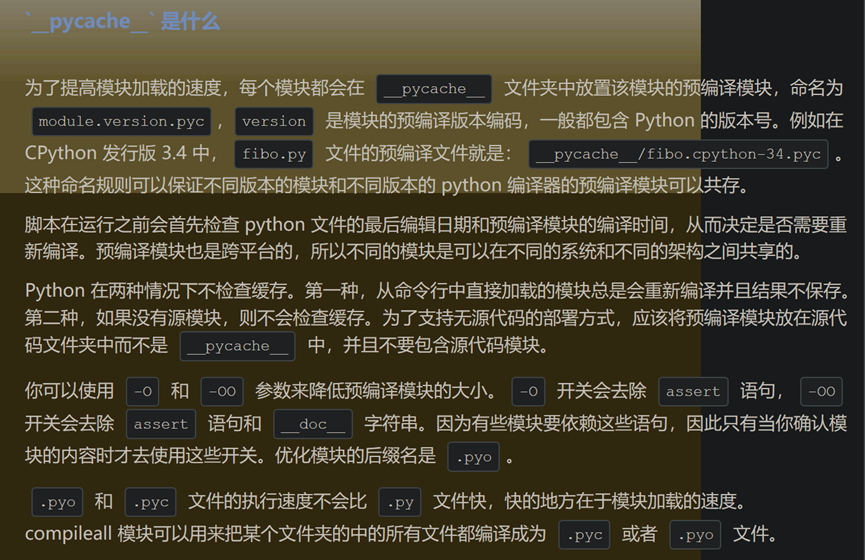
6.pycache 文件夹是什么
为了提高模块加载的速度,每个模块都会在 pycache 文件夹中放置该模块的预编译模块,命名为 module.version.pyc, version 是模块的预编译版本编码,一般都包含 Python 的版本号。
__pycache__文件夹的意义何在呢? 因为第一次执行代码的时候,Python解释器已经把编译的字节码放在__pycache__文件夹中,这样以后再次运行的话,如果被调用的模块未发生改变,那就直接跳过编译这一步,直接去__pycache__文件夹中去运行相关的 *.pyc 文件,嫩缩短运行时间。在有时候运行代码第一次运行成功后会产生__pycache__文件夹,在此基础上继续运行一次,则会报错。此时将该文件夹删除,重启Anaconda,则继续运行不会报错。
7.流




8.图片转成 bsae64编码 再转成 xlsx文件 储存在网上的
base64定义:
8Bit字节代码的编码方式之一
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法
图片转base64原理

没什么原理,过程就是讲文件的完整二进制数据每八位一组转化为ascii字符,然后base64就行了。你可以用 fileReader获取二进制数据试试看
9.序列化
序列化 (Serialization)是指将对象、数据结构的状态信bai息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
我们编写的程序,会涉及到各种各样的对象、数据结构,它们通常是以变量的形式在内存中存在着。当程序运行结束后,这些变量也就会被清理。但我们有时希望能够在下一次编写程序时恢复上一次的某个对象(如机器学习中的到结果,需要程序运行较长时间,多次运行时间成本太大),这就需要我们将变量进行持久化的存储。一种方式是利用文件读写的方式将变量转化为某种形式的字符串写入文件内,但需要自己控制存储格式显得十分笨拙。更好的方式是通过序列化的方式将变量持久化至本地。
本文主要针对python中的序列化操作进行记录,定期更新python中的涉及到的序列化问题,以作备忘。
1.json序列化变量
序列化对象至本地文件:
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
对应的反序列化方法:
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
序列化对象至字符串:
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
对应的反序列化方法:
json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
2.numpy序列化ndarray
序列化array:np.save(file, arr, allow_pickle=True, fix_imports=True)
序列化并压缩:np.savez(file, *args, **kwds)
反序列化array:numpy.load(file, mmap_mode=None, allow_pickle=True, fix_imports=True, encoding='ASCII')
10.面向对象三大特性:封装,继承,多态
10.1 继承
https://www.cnblogs.com/bigberg/p/7182741.html#_label1
继承概念的实现方式主要有2类:实现继承、接口继承。
1.实现继承是指使用基类的属性和方法而无需额外编码的能力。 2.接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力(子类重构爹类方法)。
class Person(object): # 定义一个父类
def talk(self): # 父类中的方法
print("person is talking....")
class Chinese(Person): # 定义一个子类, 继承Person类
def walk(self): # 在子类中定义其自身的方法
print('is walking...')
c = Chinese()
c.talk() # 调用继承的Person类的方法
c.walk() # 调用本身的方法
# 输出
# person is talking....
# is walking...
10.2 多态
子类重写父类的方法后可以实现多态,重写时形参必须和父类的形参相同。如果不同,那么就不算重写,对子类来说,该方法属于重载。
11.注意 写代码时候账号密码一定要单独建个文件夹
方便以后上传代码,避免一个个文件夹去改账号密码
12.编译器
简单讲,编译器就是将”一种语言(通常为高级语言)”翻译为”另一种语言(通常为低级语言)”的程序。一个现代编译器的主要工作流程:源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器 (Linker) → 可执行程序 (executables)
高级计算机语言便于人编写,阅读交流,维护。机器语言是计算机能直接解读、运行的。编译器将汇编或高级计算机语言源程序(Source program)作为输入,翻译成目标语言(Target language)机器代码的等价程序。源代码一般为高级语言 (High-level language), 如Pascal、C、C++、Java、汉语编程等或汇编语言,而目标则是机器语言的目标代码(Object code),有时也称作机器代码(Machine code)。
13.多态与虚函数
https://blog.csdn.net/tony_wong/article/details/39638887
14.数据仓库DW层
操作性数据
ODS(Operational Data Store) ,是作为数据库到数据仓库的一种过渡,ODS的数据结构一般与数据来源保持一致,便于减少ETL的工作复杂性,而且ODS的数据周期一般比较短,ODS的数据最终流入DW。
数据仓库
DW (Data Warehouse),是数据的归宿,这里保持所有从ODS到来的数据,并长期保存,而且这些数据不会被修改。
数据集市
DM(Data Mart) ,为了特定的应用目的,而从数据仓库中独立出来的一部分数据,也可称为主题数据。DM结构清晰,针对性强、拓展性好。
参考:https://blog.csdn.net/weixin_32940141/article/details/112752611
15.文件大小和储存大小
windows用NTFS和FAT的文件系统管理磁盘文件,所有文件系统都是基于簇(分配单元)大小,它代表了可以分配用来保存文件的最小磁盘空间量。Windows XP NTFS下最大的默认簇大小为 4 千字节 (KB)。也就是说,每个文件都是按4K的空间划分保存的,即使这个文件只有100字节。
打个比方,作文纸,每页可以写400字;超过400字,就要翻一页。可是只写一首20字的诗,也要用一页纸
1、.“文件大小”与“所占空间”的差别 ,为了便于大家理解,先来看两个例子:
例1: 找到D盘上的Ersave2.dat文件,用鼠标右键单击该文件,选择“属性”,即可打开对话框,我们可以看到,Ersave2.dat的实际大小为655,628 Byte(字节),但它所占用的空间却为688,128 Byte, 两者整整相差了32KB。
例2: 同样是该文件,如果将它复制到A盘, 你会发现该文件实际大小和所占空间基本一致 ,同为640KB,但字节数稍有差别。再将它复制到C盘,查看其属性后,你会惊奇地发现它的大小和所占空间的差别又不相同了!
显然,在这两种情况中,文件的实际大小没有变化,但在不同的磁盘上它所占的空间却都有变化。事实上,只要理解了文件在磁盘上的存储机制后,就不难理解上述的三种情况了。文件的大小其实就是文件内容实际具有的字节数,它以Byte为衡量单位,只要文件内容和格式不发生变化,文件大小就不会发生变化。但文件在磁盘上的所占空间却不是以Byte为衡量单位的,它最小的计量单位是“簇(Cluster)”。
2、分区格式与簇大小
在例2中, 同一个文件在不同磁盘分区上所占的空间不一样大小,这是由于不同磁盘簇的大小不一样导致的。 簇的大小主要由磁盘的分区格式和容量大小来决定,其对应关系如表1所示。
笔者的软盘采用FAT分区,容量1.44MB,簇大小为512 Byte(一个扇区);C盘采用FAT 32分区,容量为4.87GB,簇大小为8KB;D盘采用FAT 32分区,容量为32.3GB,簇大小为32KB。计算文件所占空间时,可以用如下公式:
簇数=取整(文件大小/簇大小)+1 所占空间=簇数×磁盘簇大小 公式中文件大小和簇大小应以Byte为单位,否则可能会产生误差。如果要以KB为单位,将字节数除以1024即可。利用上述的计算公式,可以计算ersave2.dat文件的实际占用空间。
3、轻松查看簇大小
①用Chkdsk查看簇大小 在Windows操作系统中,我们可以使用Chkdsk命令查看硬盘分区的簇大小。例如要在Windows XP下查看C盘的簇大小,可以单击“开始→运行”,键入“CMD”后回车,再键入“C:”后回车,然后输入“Chkdsk”后回车,稍候片刻从它的分析结果中,我们就可以得到C盘的簇大小,不过它把簇称之为“分配单元”或者“Allocation unit”。
②用PQ Magic等磁盘工具来检测 很多磁盘工具都具备磁盘信息显示等功能。例如在PQ Magic中,选择要查看的磁盘分区,然后单击右键选择“高级→调整簇大小”功能,即可从显示的对话框中可以看到该磁盘当前设置的簇大小。
③手工查看 手动创建一个100字节以下的文本文档。然后将该文件复制到欲查看簇大小的磁盘分区中,在Windows下显示该文件的属性,其中“所占空间”处显示的数值就是簇大小。
环境配置 软件安装
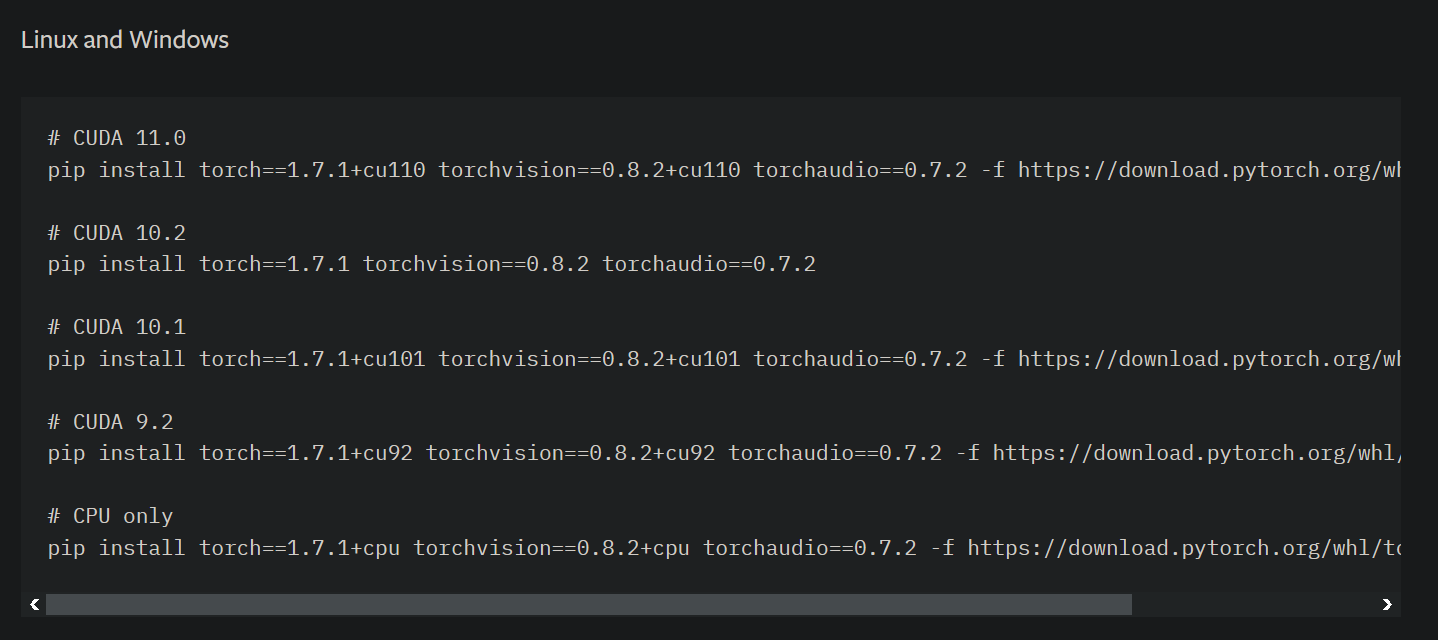
1.cuda 和 torch
报错:
The NVIDIA driver on your system is too old (found version 8000).
Please update your GPU driver by downloading and installing a new
原因:
并不是说你的 CUDA 驱动版本太低了,而是 Pytorch 的版本和 CUDA 不匹配。
解决方法:
从新安装torch 和torchvision
对应如下图
# CUDA 10.1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
Python 基础操作
1.引号
str = ‘my name is “xxx”!’
str = “my name is ‘xxx’!”
使用上没有太大区别
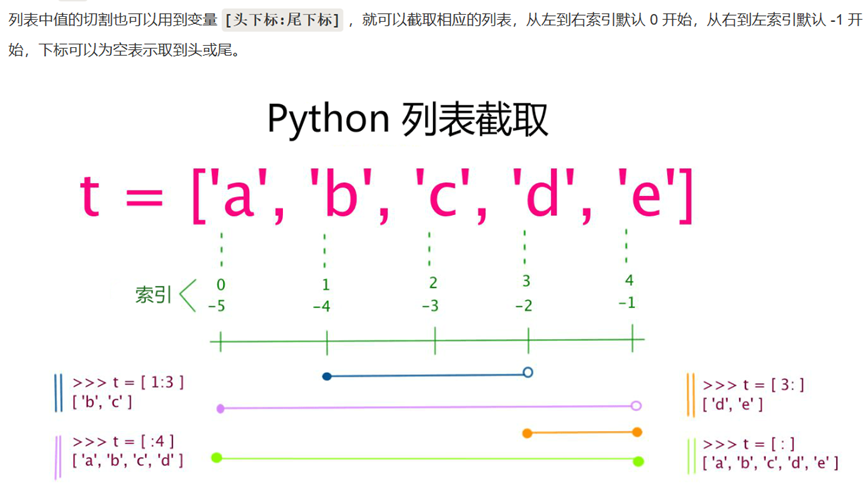
2.List列表
列表用 [ ] 标识
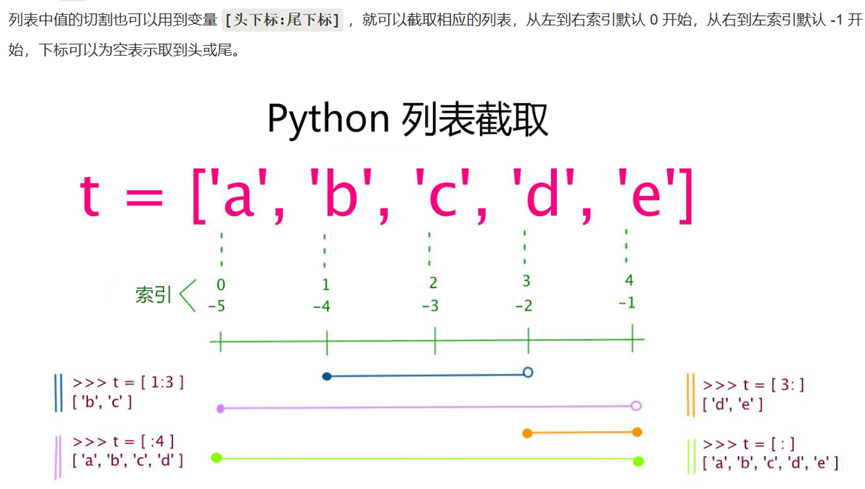
3.元组
元组用 () 标识,内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
注意:
4.字典dic的操作
5.python中+=是什么意思?

6.% 拼接 指代

我的拼接:

%的使用
https://www.cnblogs.com/wh-ff-ly520/p/9390855.html
%s string型 表示格式化一个对象为字符 “%s1”%S2 s1放置的是一个字符串(格式化字符串) S2放置的是一个希望要格式化的值

print("string=%s" %string) #输出的打印结果为 string=good
print("string=%3s" %string) # 输出的打印结果为 string=good(数字3的意思是:字符串的长度为3。当字符串的长度大于3时,按照字符串的长度打印出结果)
print("string=%(+)6s" %string) # 输出的打印结果为 string= good(当字符串的长度小于6时,在字符串的左侧填补空格,使得字符串的长度为6)
print("string=%-6s" %string) # 输出的打印结果为 string=good (当字符串的长度小于6时,在字符串的右侧填补空格,使得字符串的长度为6)
7.join的使用
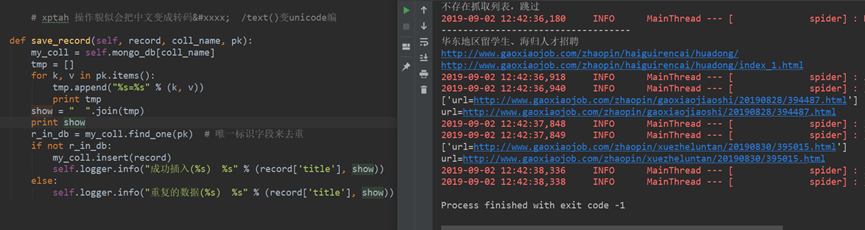
str = "-";
seq = ("a", "b", "c"); # 字符串序列
print str.join( seq );
输出结果:
a-b-c
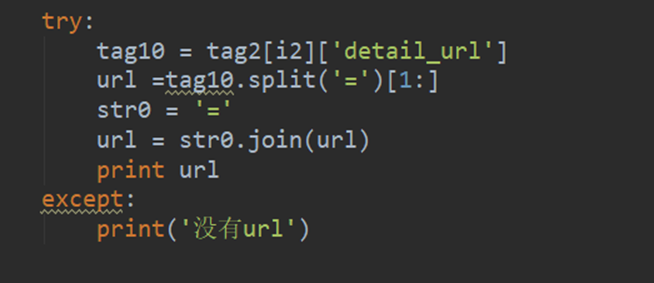
seq4 = {'hello':1,'good':2,'boy':3,'doiido':4}
print ':'.join(seq4)
boy:good:doiido:hello
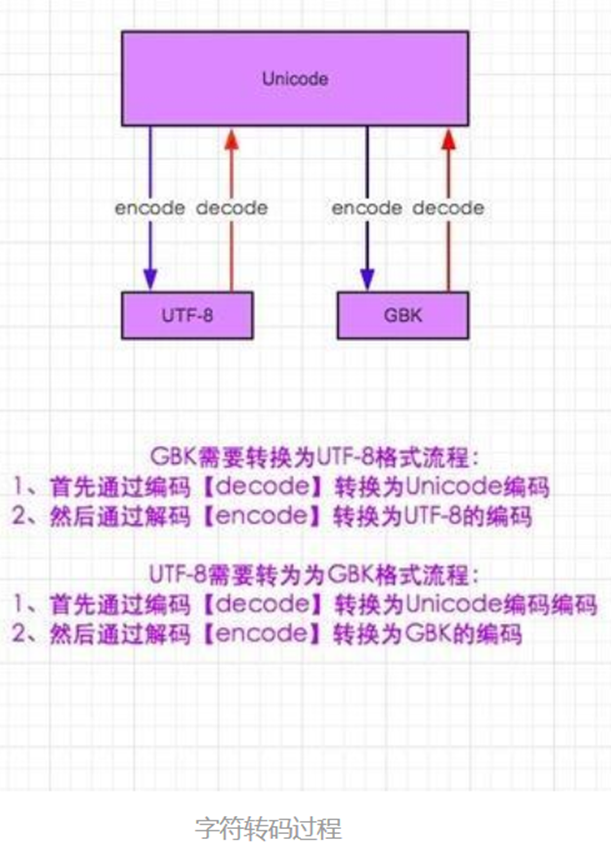
8.encoding 和 encode
这个没有encoding方法
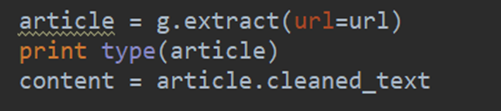
这个有encoding方法

9.Python isdigit() 方法检测字符串是否只由数字组成 isalpha isalnum
9.1 用isdigit函数判断是否数字
str = "123456"; # Only digit in this string
print str.isdigit();
str = "this is string example....wow!!!";
print str.isdigit();
以上实例输出结果如下:
True
False
str_1 = "123"
str_2 = "Abc"
str_3 = "123Abc"
print(str_1.isdigit())
Ture
print(str_2.isdigit())
False
print(str_3.isdigit())
False

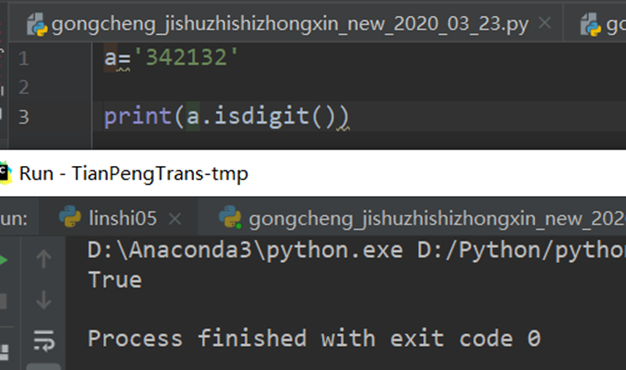
9.2 用isalpha判断是否字母
print(str_1.isalpha())
False
print(str_2.isalpha())
Ture
print(str_3.isalpha())
False
9.3 isalnum判断是否数字和字母的组合
print(str_1.isalnum())
Ture
print(str_2.isalnum())
Ture
print(str_1.isalnum())
Ture
注意:如果字符串中含有除了字母或者数字之外的字符,比如空格,也会返回False
10.startswith 和 endswith
如果你要用python匹配字符串的开头或末尾是否包含一个字符串,就可以用startswith 和 endswith
用途:与str.endwith()相反,判断字符串是否以指定前缀开始。
语法:str.startwith(prefix[, start[, end]]):
示例1:
s = 'Apollo'
s.startswith('Ap')
print(s.startswith('Ap'))
打印结果:True
示例2:
s = 'Apollo'
s.startswith('po')
print(s.startswith('po',1,4))
打印结果:True
示例3:
s = 'Apollo'
s.startswith('Apo')
print(s.startswith('Apo',1,4))
打印结果:False


11.unicode转字符串
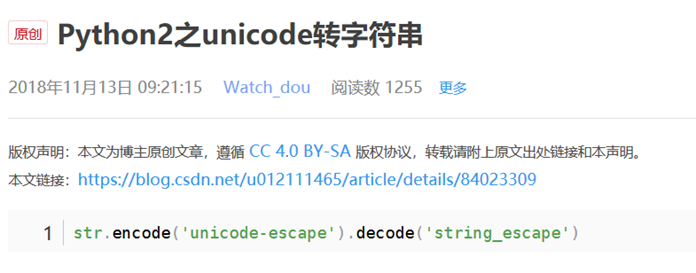
12.list map, list dict

13.json.loads()
json.dumps()函数是将一个Python数据类型列表进行json格式的编码
json.loads()函数是将json格式数据转换为字典
14.查看系统/服务器 cpu 内核数
CPU内核数
cores = multiprocessing.cpu_count()
15.list.index()

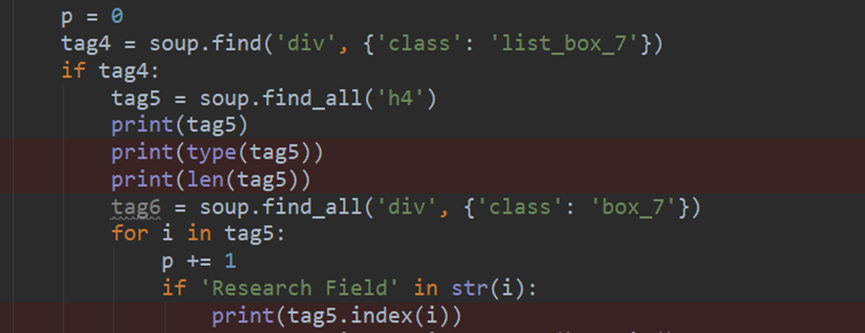
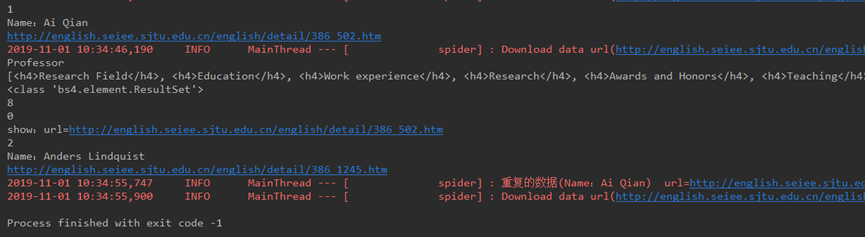

16.math.pow(x,y)
Math.pow(x,y)的作用就是计算x的y次方,其计算后是浮点数
17.实现将多个空格换为一个空格的方法 re
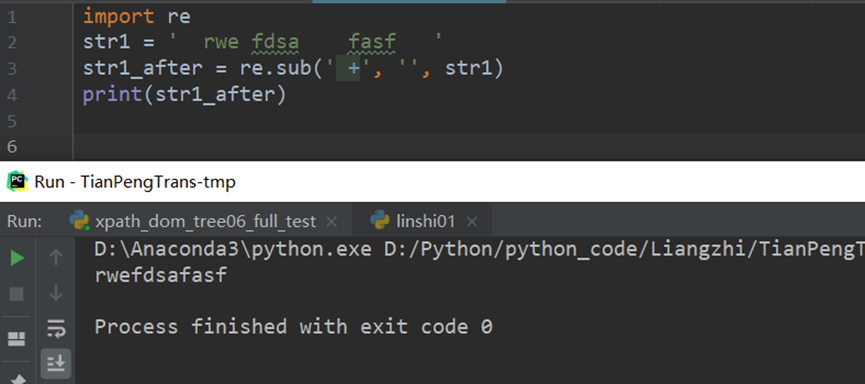
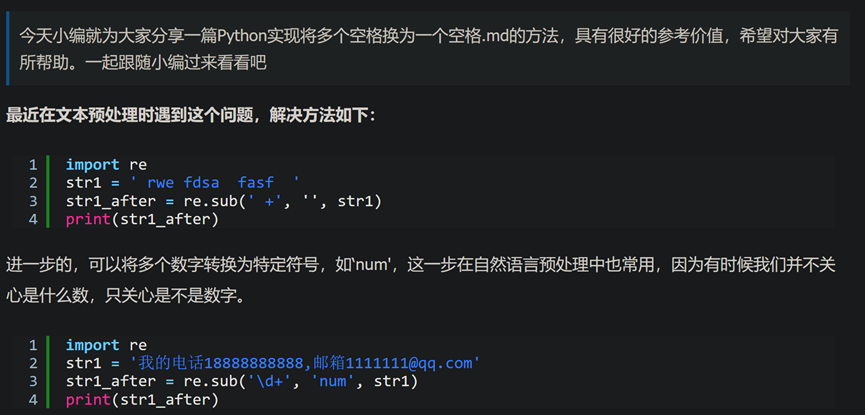
import re
str1 = ' rwe fdsa fasf '
str1_after = re.sub(' +', '', str1)
print(str1_after)
18.split多分割
s2_list = re.split('[。;?!]', s1)
print(s2_list)
19.字节 bit byte kb mb gb
8bit(位)=1Byte(字节) 1024Byte(字节)=1KB 1024KB=1MB 1024MB=1GB 1024GB=1TB
float对象是24字节的
字节:
float:4个字节
double:8个字节
Mongodb中bson
byte 1字节(8位)
int32 4字节 (32位的有符号整数)
int64 8字节 (64柆的有符号整数)
double 8字节 (64柆的浮点数)
20.sort排序 list排序 字符串从长到短排序
>>> list2 = [4,3,2,1]
>>> list3 = sorted(list2)
>>> list2
[4, 3, 2, 1]
>>> list3
[1, 2, 3, 4]
a = ["flower", "flat", "float"]
s = sorted(a, key=len, reverse=True)
print(s)
# ["flower", "float", "flat"]
20.1 python list 按字符长度进行排序
https://blog.csdn.net/moxiaobeiMM/article/details/80702496
https://blog.csdn.net/moshiyaofei/article/details/86376058
myList = ['青海省','内蒙古自治区','西藏自治区','新疆维吾尔自治区','广西壮族自治区']
myList1 = sorted(myList,key = lambda i:len(i),reverse=True)
print(myList1)
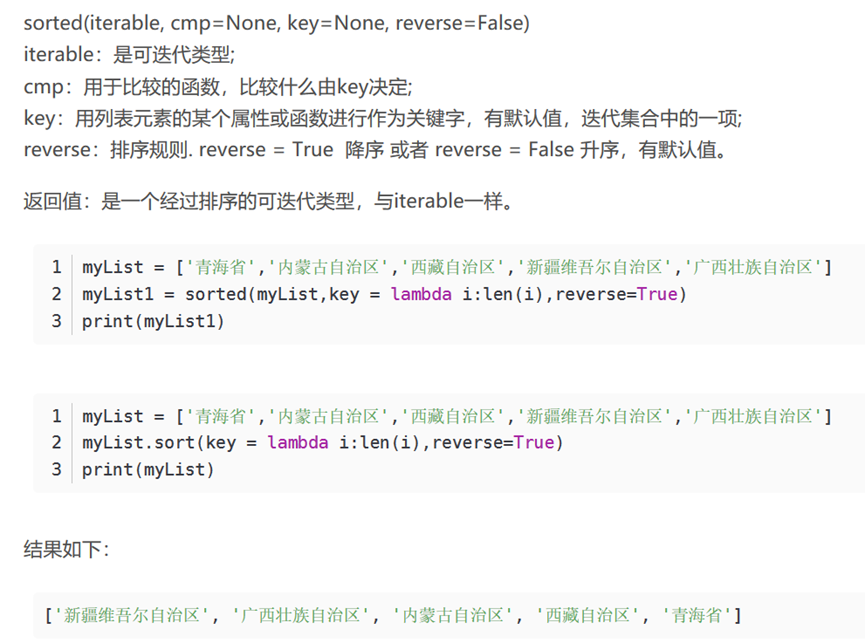
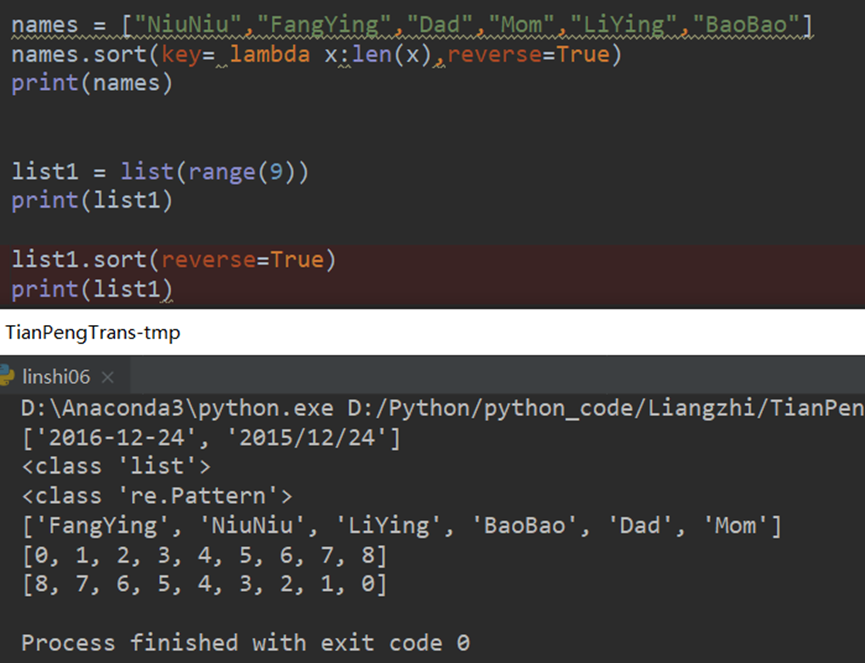
20.2 字符串从大到小排序 从小到大排序
从短到长
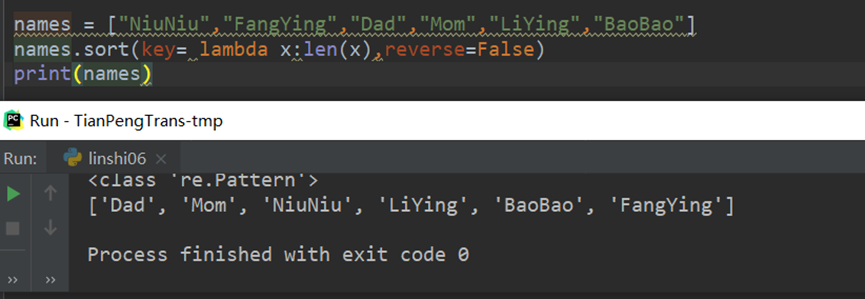
从长到短

从大到小 reverse=True
21.collections模块
硬匹配和权重
https://www.cnblogs.com/dianel/p/10787693.html
Python中collections模块
这个模块实现了特定目标的容器,以提供Python标准内建容器 dict、list、set、tuple 的替代选择。
• Counter:字典的子类,提供了可哈希对象的计数功能
• defaultdict:字典的子类,提供了一个工厂函数,为字典查询提供了默认值
• OrderedDict:字典的子类,保留了他们被添加的顺序
• namedtuple:创建命名元组子类的工厂函数
• deque:类似列表容器,实现了在两端快速添加(append)和弹出(pop)
• ChainMap:类似字典的容器类,将多个映射集合到一个视图里面
22.python基础变量命名规则 https://baijiahao.baidu.com/s?id=1591459328108616859&wfr=spider&for=pc
变量的命名
目标
· 标识符和关键字
· 变量的命名规则
0.1 标识符和关键字
1.1 标识符
标示符就是程序员定义的 变量名、函数名
名字 需要有 见名知义 的效果,见下图:
· 标示符可以由 字母、下划线 和 数字 组成
· 不能以数字开头
· 不能与关键字重名
思考:下面的标示符哪些是正确的,哪些不正确为什么?
fromNo12 from#12 my_Boolean my-Boolean Obj2 2ndObj myInt My_tExt _test test!32 haha(da)tt jack_rose jack&rose GUI G.U.I
1.2 关键字
· 关键字 就是在 Python 内部已经使用的标识符
· 关键字 具有特殊的功能和含义
· 开发者 不允许定义和关键字相同的名字的标示符
通过以下命令可以查看 Python 中的关键字
python In [1]: import keyword In [2]: print(keyword.kwlist)
提示:关键字的学习及使用,会在后面的课程中不断介绍
import 关键字 可以导入一个 “工具包”
在 Python 中不同的工具包,提供有不同的工具
·
02. 变量的命名规则
命名规则 可以被视为一种 惯例,并无绝对与强制 目的是为了 增加代码的识别和可读性
注意 Python 中的 标识符 是 区分大小写的
1. 在定义变量时,为了保证代码格式,= 的左右应该各保留一个空格
2. 在 Python 中,如果 变量名 需要由 二个 或 多个单词 组成时,可以按照以下方式命名
1. 每个单词都使用小写字母
2. 单词与单词之间使用 _下划线 连接
3. 例如:first_name、last_name、qq_number、qq_password
驼峰命名法
· 当 变量名 是由二个或多个单词组成时,还可以利用驼峰命名法来命名
· 小驼峰式命名法
o 第一个单词以小写字母开始,后续单词的首字母大写
o 例如:firstName、lastName
· 大驼峰式命名法
o 每一个单词的首字母都采用大写字母
o 例如:FirstName、LastName、CamelCase
23.cmd 中 pip 指定版本

24.PyQt5 的安装 https://www.cnblogs.com/pywjh/p/9835931.html
PyQt是一个用于创建GUI应用程序的跨平台工具包,它将Python与Qt库融为一体。也就是说,PyQt允许使用Python语言调用Qt库中的API。这样做的最大好处就是在保留了Qt高运行效率的同时,大大提高了开发效率。因为,使用Python语言开发程序要比使用C++语言开发程序快得多。PyQt对Qt做了完整的封装,几乎可以用PyQt做Qt能做的任何事情。
图形用户界面(Graphical User Interface,简称 GUI,又称图形用户接口)是指采用图形方式显示的计算机操作用户界面。
25.multtiprocessing查自己的cpu核数


26.numpy
numpy.reshape(-1,1) numpy中reshape的使用
https://blog.csdn.net/qq_42804678/article/details/99062431
数组新的shape属性应该要与原来的配套,如果等于-1的话,那么Numpy会根据剩下的维度计算出数组的另外一个shape属性值。
举个例子:
x = np.array([[2, 0], [1, 1], [2, 3]])
指定新数组行为3,列为,2,则:
y = x.reshape(3,2)
y
Out[43]:
array([[2, 0],
[1, 1],
[2, 3]])
26.1 np.concatenate函数


27.导入包的两种写法

28.enumerate
A = [1, 4, 5]
for i, x in enumerate(A):
print(i, x)
29.迭代器 iterator
解释
迭代器(iterator)是一种对象,它能够用来遍历标准模板库容器中的部分或全部元素,每个迭代器对象代表容器中的确定的地址。迭代器修改了常规指针的接口,所谓迭代器是一种概念上的抽象:那些行为上像迭代器的东西都可以叫做迭代器。然而迭代器有很多不同的能力,它可以把抽象容器和通用算法有机的统一起来。 迭代器提供一些基本操作符:*、++、==、!=、=。这些操作和C/C++“操作array元素”时的指针接口一致。不同之处在于,迭代器是个所谓的复杂的指针,具有遍历复杂数据结构的能力。其下层运行机制取决于其所遍历的数据结构。因此,每一种容器型都必须提供自己的迭代器。事实上每一种容器都将其迭代器以嵌套的方式定义于内部。因此各种迭代器的接口相同,型号却不同。这直接导出了泛型程序设计的概念:所有操作行为都使用相同接口,虽然它们的型别不同。
功能
迭代器使开发人员能够在类或结构中支持foreach迭代,而不必整个实现IEnumerable或者IEnumerator接口。只需提供一个迭代器,即可遍历类中的数据结构。当编译器检测到迭代器时,将自动生成IEnumerable接口或者IEnumerator接口的Current,MoveNext和Dispose方法。
30.参数的含义 (*args,**kwargs)
31.token的含义
token是什么Token (计算机术语)在计算机身份认证中是令牌(临时)的意思,
在词法分析中是标记的意思。
令牌(信息安全术语)Token, 令牌,代表执行某些操作的权利的对象访问令牌(Access token)表示访问控制操作主体的系统对象邀请码,在邀请系统中使用Token, Petri 网(Petri net)理论中的Token密保令牌(Security token),或者硬件令牌,例如U盾,或者叫做认证令牌或者加密令牌,一种计算机身份校验的物理设备会话令牌(Session token),交互会话中唯一身份标识符令牌化技术 (Tokenization), 取代敏感信息条目的处理过程。
32.数组和列表的区别
ArrayList可以算是Array的加强版,(对array有所取舍的加强)。
另附分类比较:
存储内容比较:
Array数组可以包含基本类型和对象类型,
ArrayList却只能包含对象类型。
但是需要注意的是:Array数组在存放的时候一定是同种类型的元素。ArrayList就不一定了,因为ArrayList可以存储Object。
空间大小比较:
它的空间大小是固定的,空间不够时也不能再次申请,所以需要事前确定合适的空间大小。
ArrayList的空间是动态增长的,如果空间不够,它会创建一个空间比原空间大约0.5倍的新数组,然后将所有元素复制到新数组中,接着抛弃旧数组。而且,每次添加新的元素的时候都会检查内部数组的空间是否足够。(比较麻烦的地方)
33.Python super() 函数
https://www.runoob.com/python/python-func-super.html
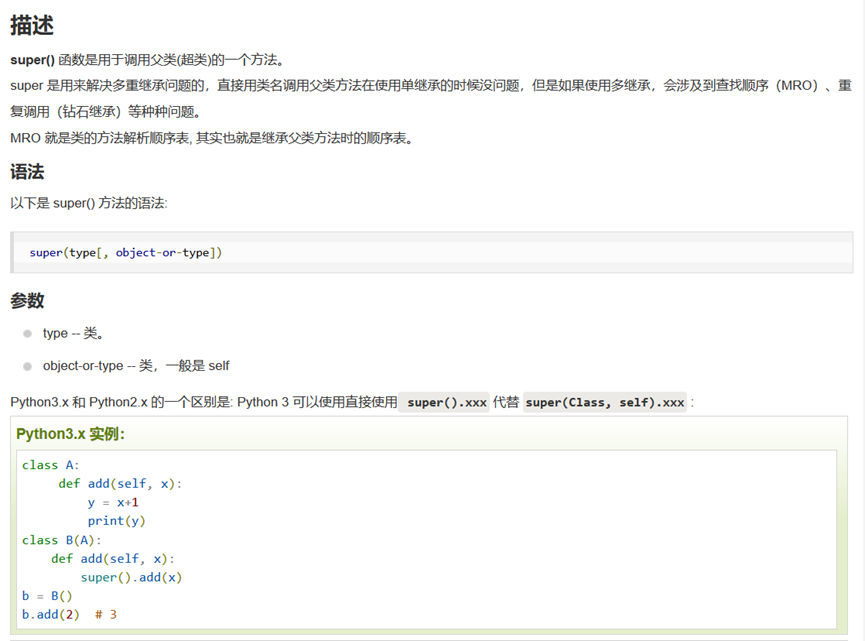
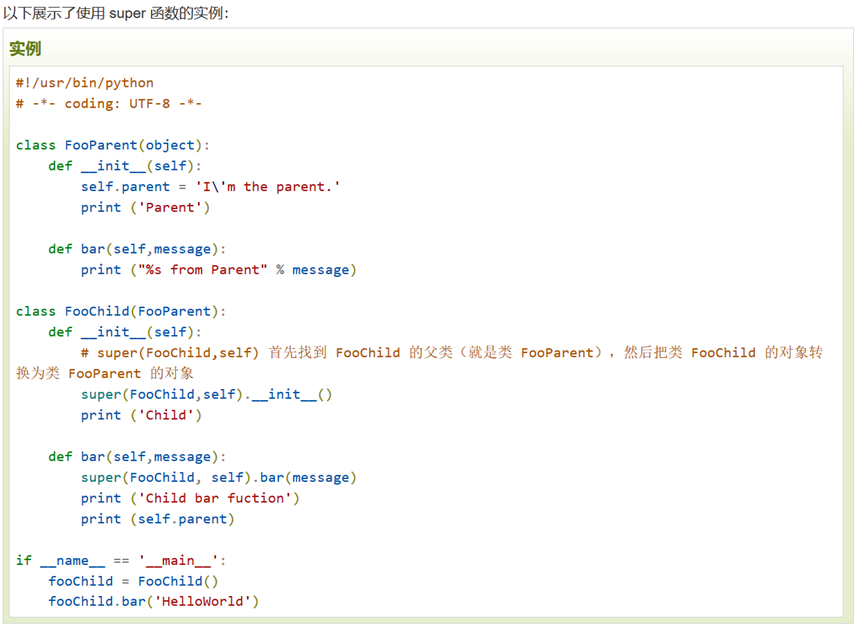

父类(超类)(SuperClass) 继承
编写类时,并非总是要从空白开始。如果你要编写的类时另一个现成版本的特殊版本,可使用继承。一个类继承另一个子类时,他将自动获得另一个类的所有属性和方法;原有的类称为父类,而新类成为子类。子类继承了其父类的所有属性和方法,同时还可以定义自己的属性和方法。
34.读取动态列表
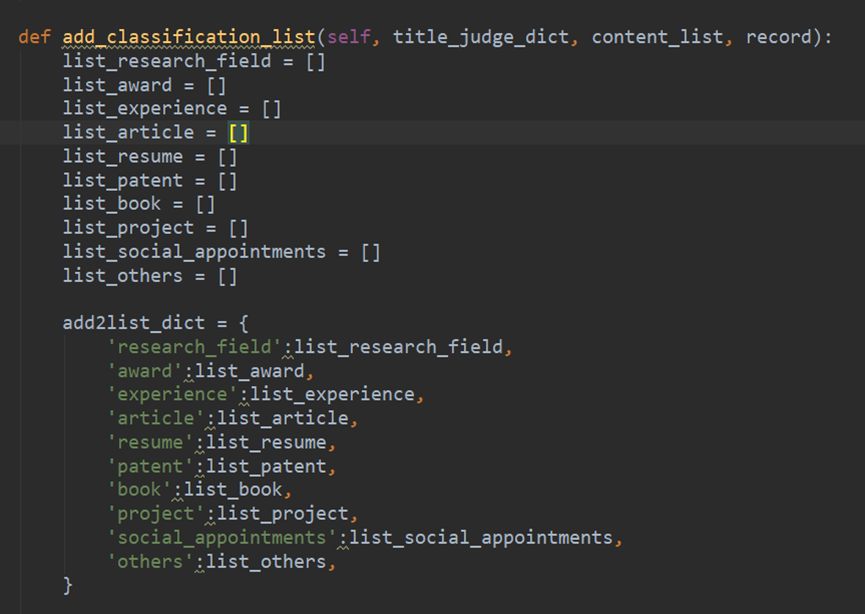
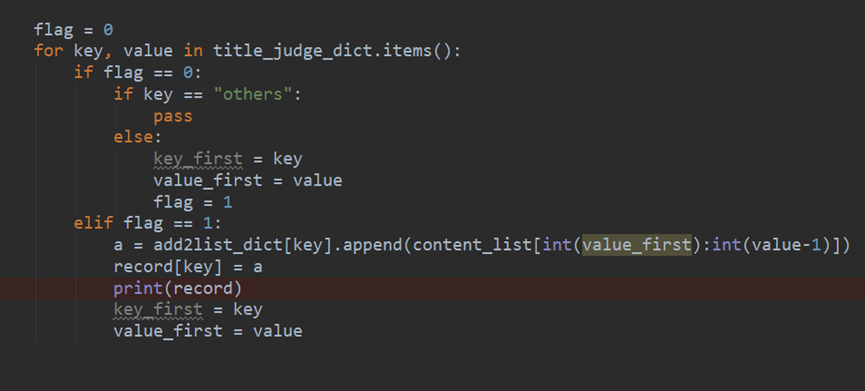
35.字典update方法 dict.update(dict2)
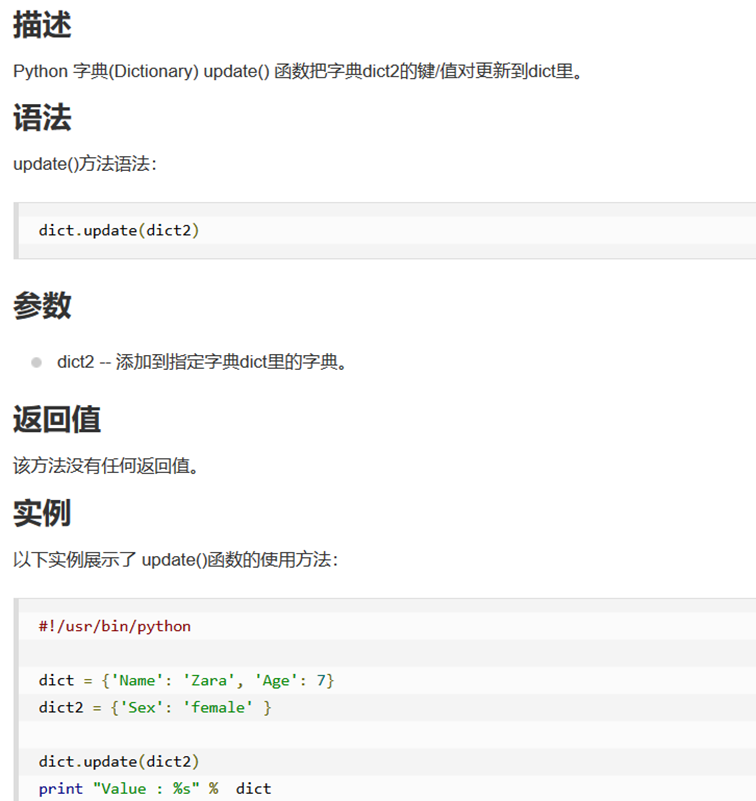
36.OrderedDict用法 from collections import OrderedDict

from collections import OrderedDict
your_dict = {19: 7, 31: 6, 28: 5, 16: 5, 32: 5, 2: 4, 24: 4, 29: 4, 6: 4, 18: 4, 15: 4, 12: 4}
order_of_keys = your_dict.keys()
list_of_tuples = [(key, your_dict[key]) for key in order_of_keys]
your_dict = OrderedDict(list_of_tuples)
print(next(reversed(your_dict)))
37.python map() 函数
描述
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。 语法
map() 函数语法:
map(function, iterable, …)

38.python str.strip([chars]) strip除去首尾指定字符
第一种情况:
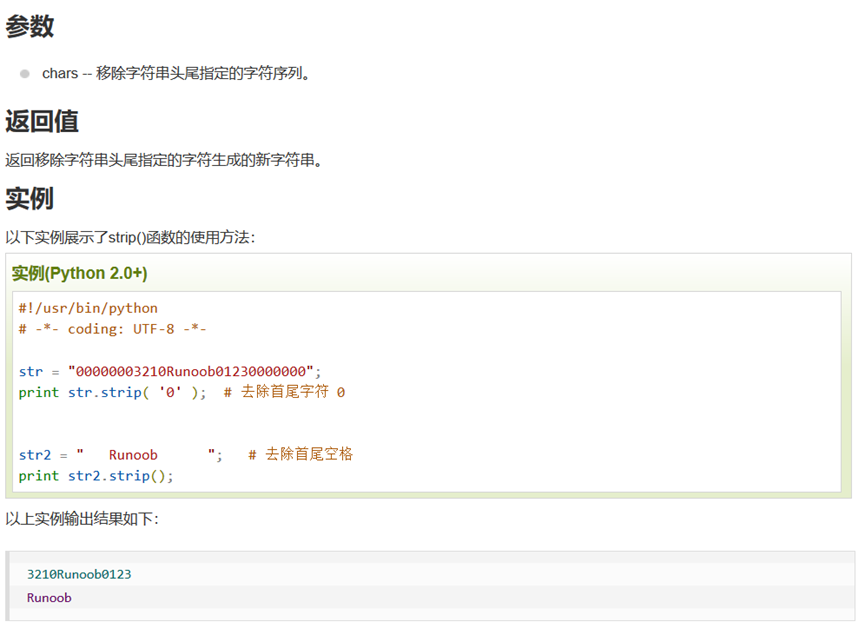
第二种情况:
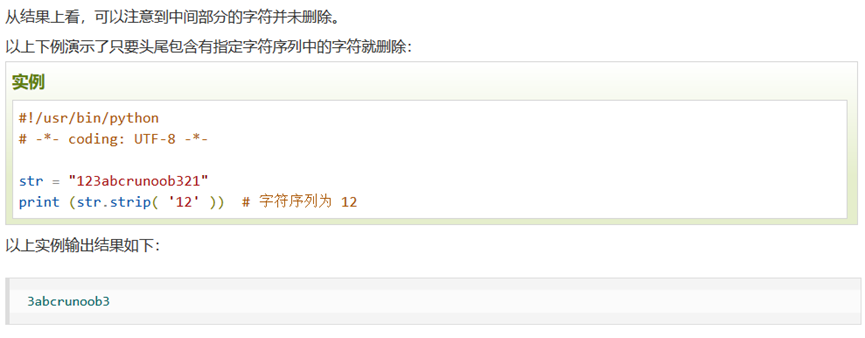
39.pow() 函数

40.\转义的使用
找出str中()内的内容
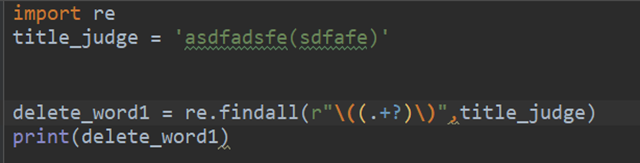
41.找出list最大值 找出dict中value最大值
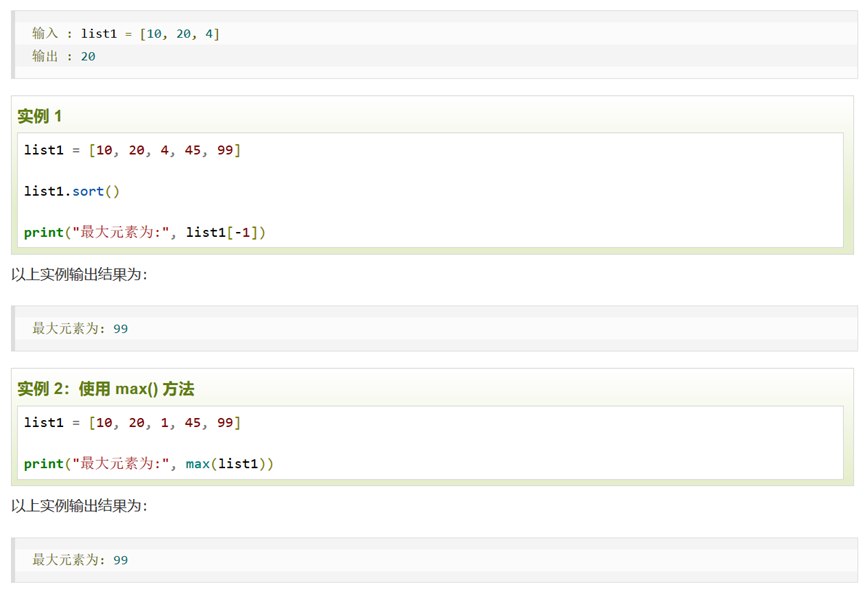
找出最大的value:

42.round()函数
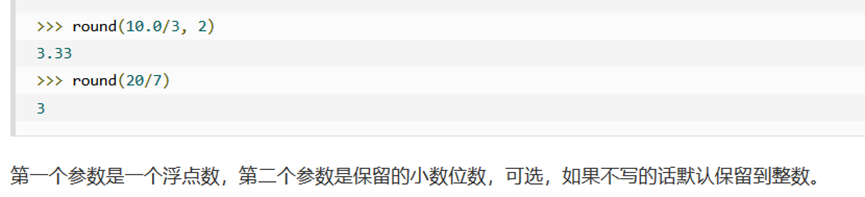
43.float函数
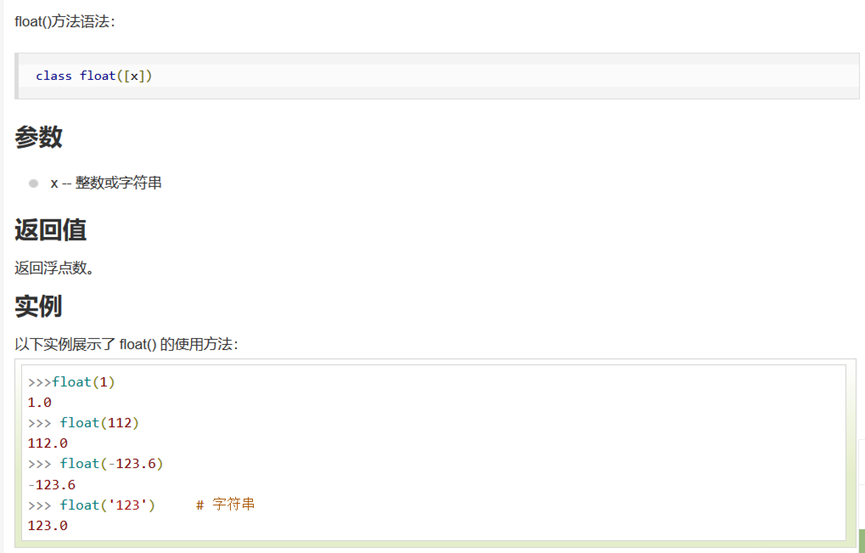
44.list.pop 移除列表中某个参数

Pop赋值,相当于把某个变量取出来

应用:

45.isinstance()函数 判断是否是某一个类型
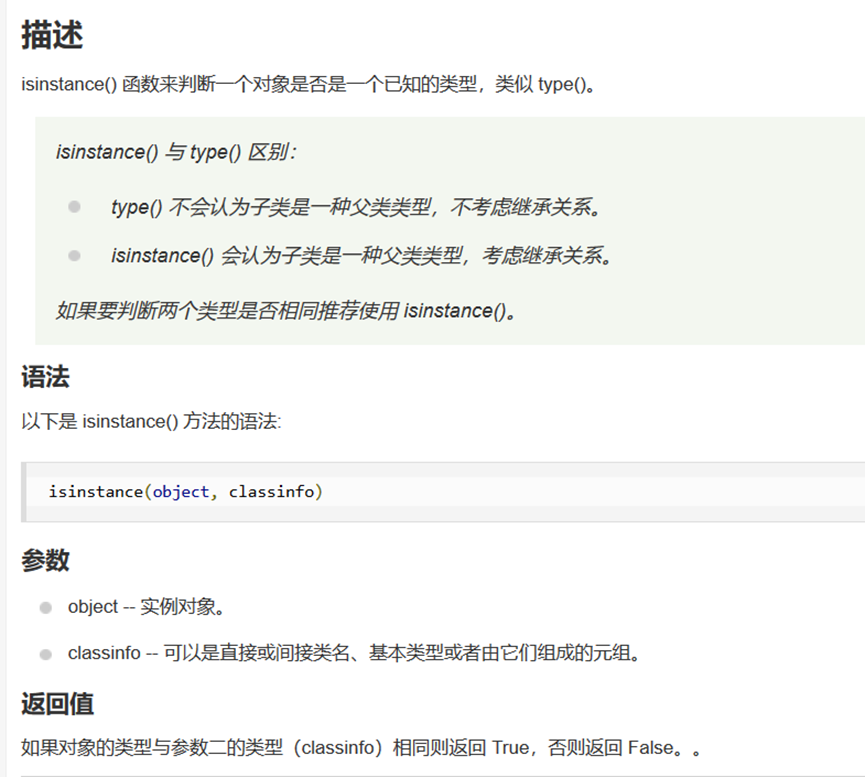
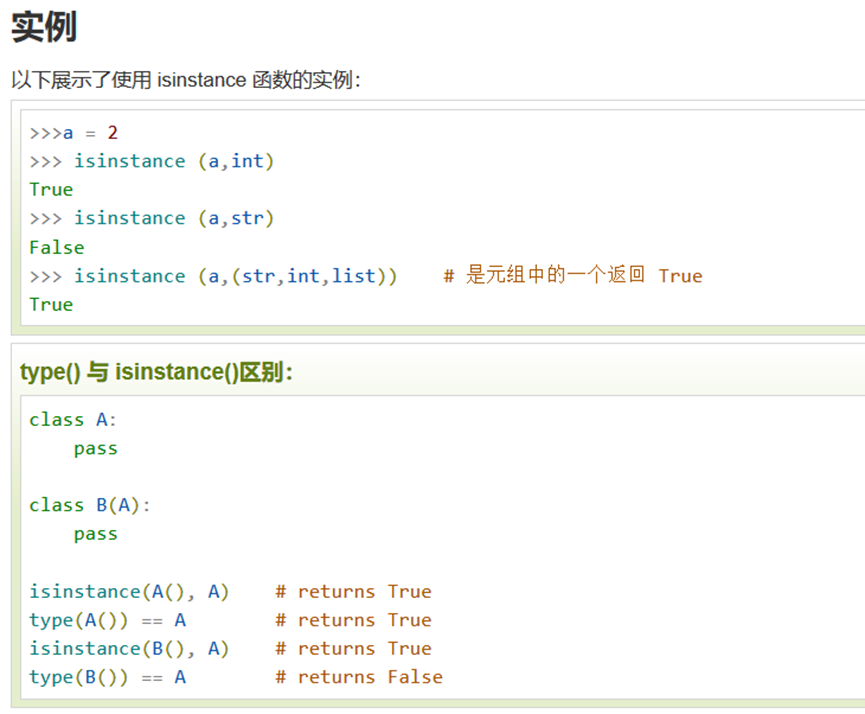
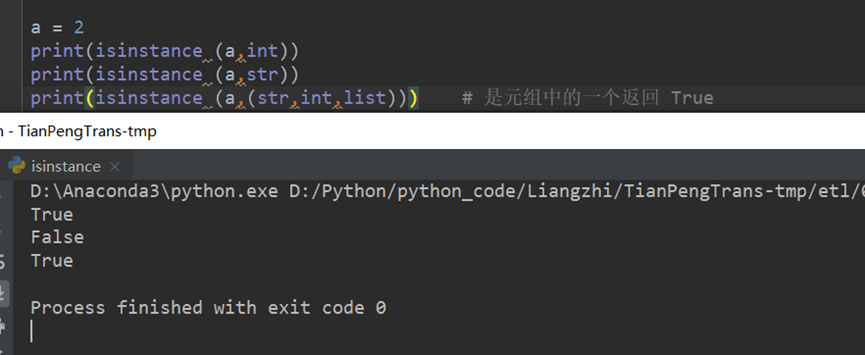
46.python判断一个变量是否存在
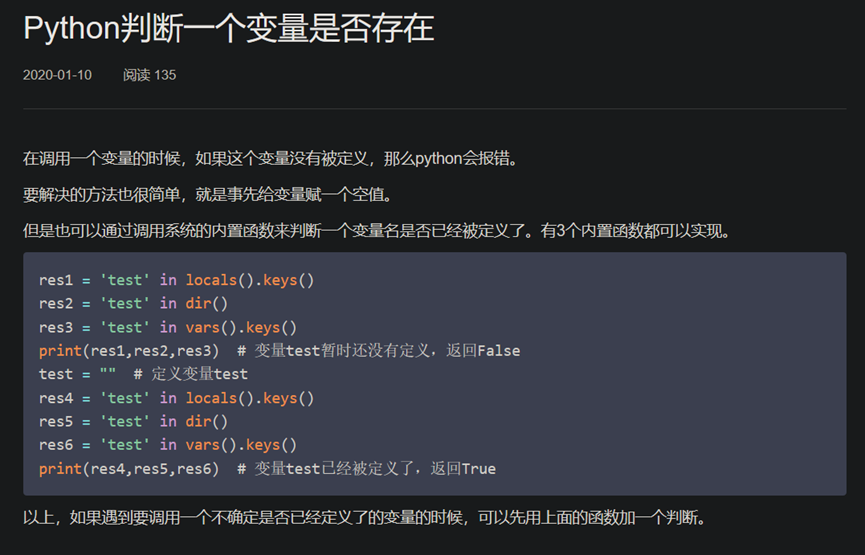
47.startJVM 和 jpype

48.获取dict的key值或者value值
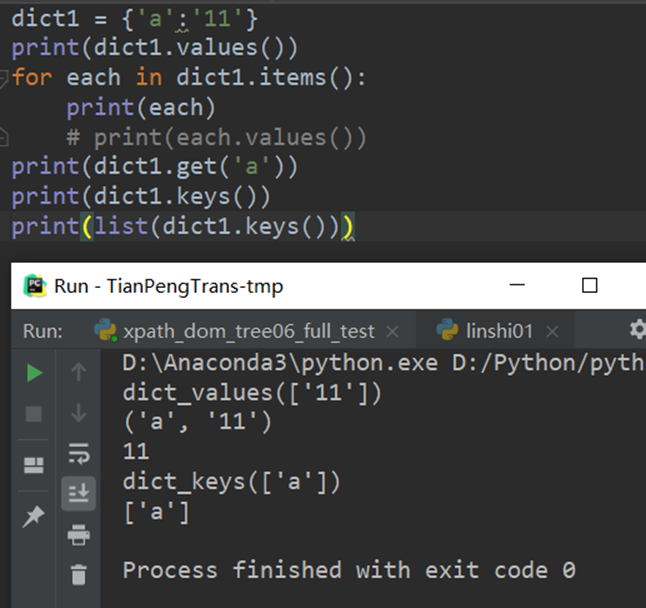
for key, value in dict_a.items():
print(key, value)
49.python override 重写
重写父类。
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法
什么是override
override字面理解是无效,消除的意思,在Python里两个同名的方法但执行不同程序,其中一个方法使得另外一个方法无效的,这就叫override(重写)。
通常情况下,父类中的方法,而子类中有同名方法,在执行该方法时,调用的是该方法对应的类。
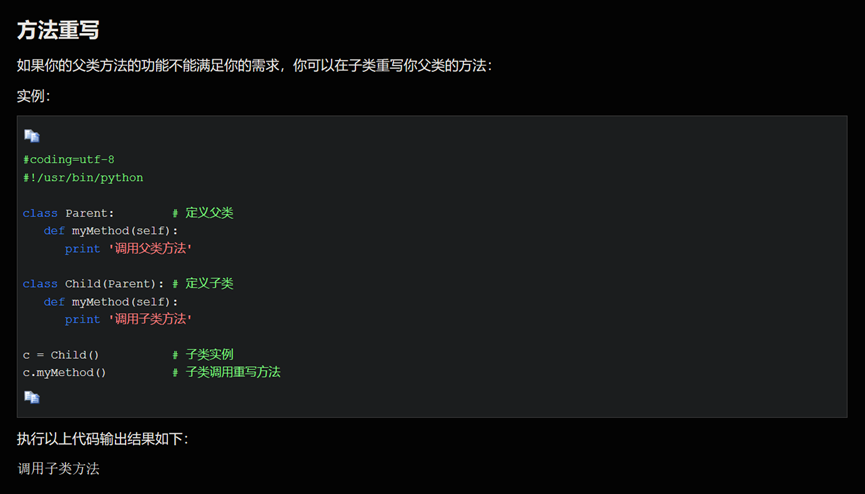
样例:
Pycharm中重写的样例: 重写后调用myMethod函数
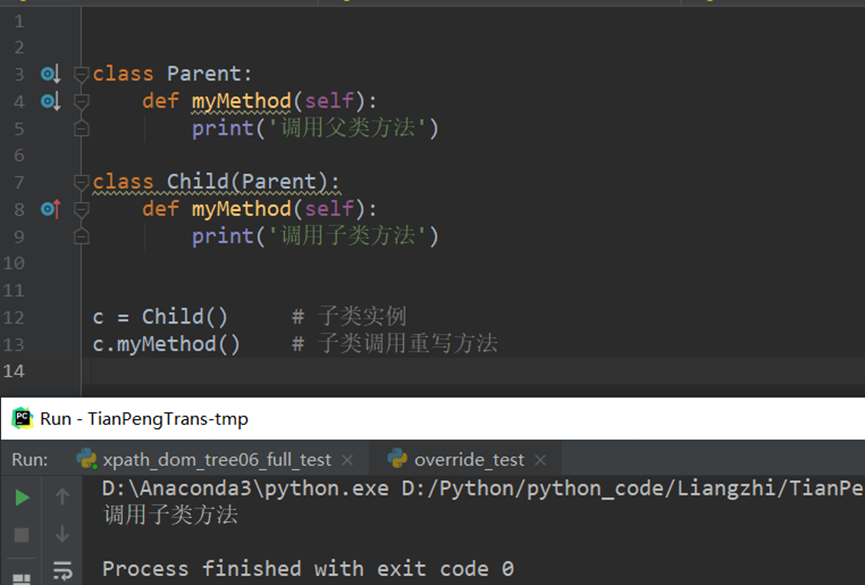
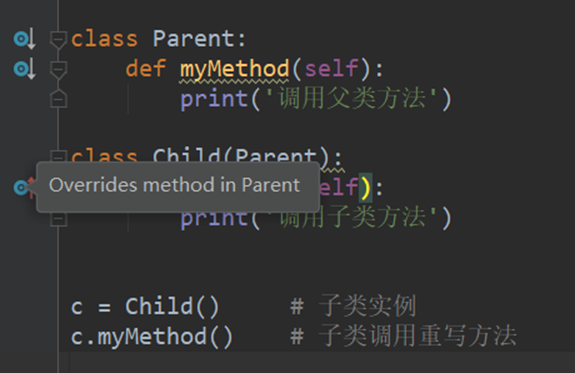
Pycharm中不重写的样例: 没有重写myMethod函数,而是直接调用myMethod函数
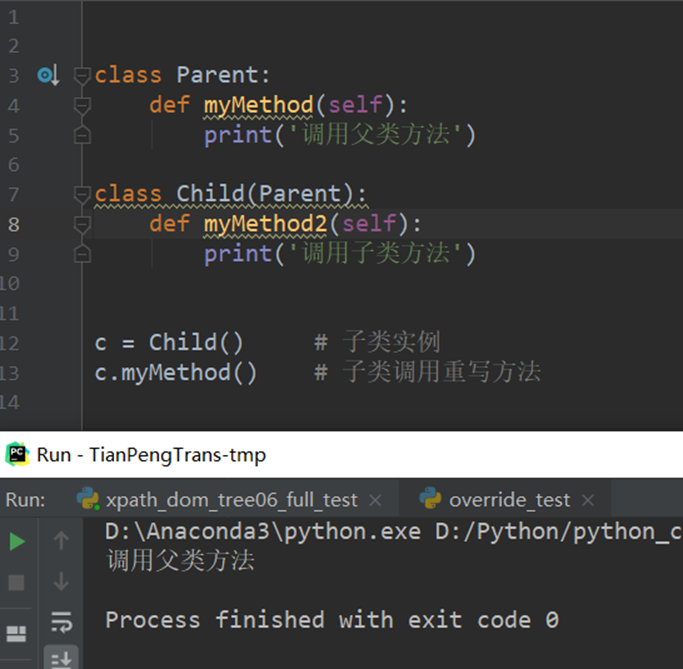
50.set() 函数 取交集,并集,差集
51.栈溢出问题 当递归太深的时候
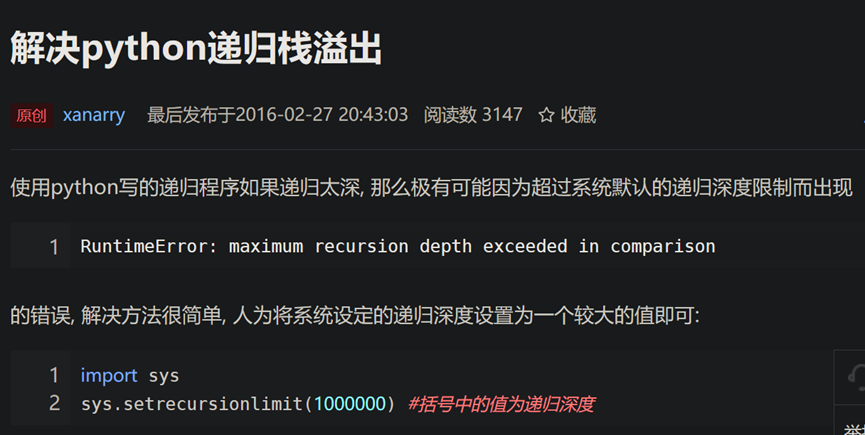
52.with open() 与 open 的区别
With open() 可以自动关闭文件
这样写太繁琐,所以,python引入了with语句来自动调用close()方法。
with创建临时运行环境:
作用:with用于创建一个临时的运行环境,运行环境中的代码执行完后自动安全退出环境。
文件操作:使用open进行文件操作时建议使用with创建运行环境,可以不用close()方法关闭文件,无论在文件使用中遇到什么问题都能安全的退出,即使发生错误退出运行环境时也可以安全退出文件并给出报错信息。
53.while True: 的用法
While True: 表示一直循环,需要有break,不然会一直循环下去。while后面的条件为真的时候就会进入循环。判断语句,可以按照字面意思理解:当为真。常用在无限循环情况,只有不满足所设条件时跳出循环。
#方法一:
name = input("请输入您的用户名:")
if '@'not in name:
print('您输入的用户名格式不正确,请重新输入')
#方法二:
while True:
name = input('请输入您的用户名:')
if '@'in name:
break
else:
print('您输入的用户名格式不正确,请重新输入')
')
continue
完整代码:
d = {'evanwang@alibaba.or':123456} #设置了字典。
while True:
name = input('请输入您的用户名:')
if '@'in name:
break
else:
print('您输入的用户名格式不正确,请重新输入')
continue
while True:
password = input('请输入您的密码:')
if d[name] == password:
print('进入系统')
break
else:
print('您输入的密码不正确,请重新输入')
continue
54.修改字典中dict中某个值不会影响顺序
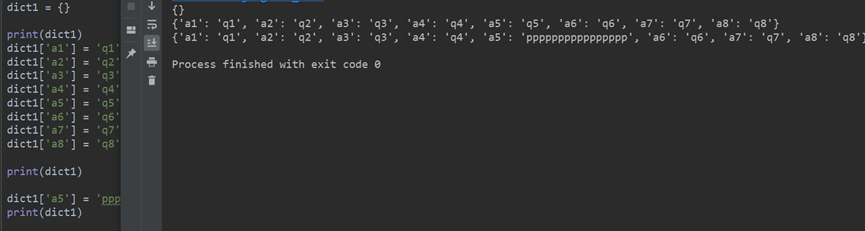
55.文件夹删除和创建
import os
url_filename = '01'
a = os.path.exists(url_filename)
if a:
print('文件夹存在')
os.rmdir(url_filename)
print('文件夹已经删除')
else:
os.mkdir(url_filename)
print('文件夹不存在')
删除非空文件夹 删除了 test 文件夹
import shutil
shutil.rmtree("c:/test")
56.random 生成随机浮点数
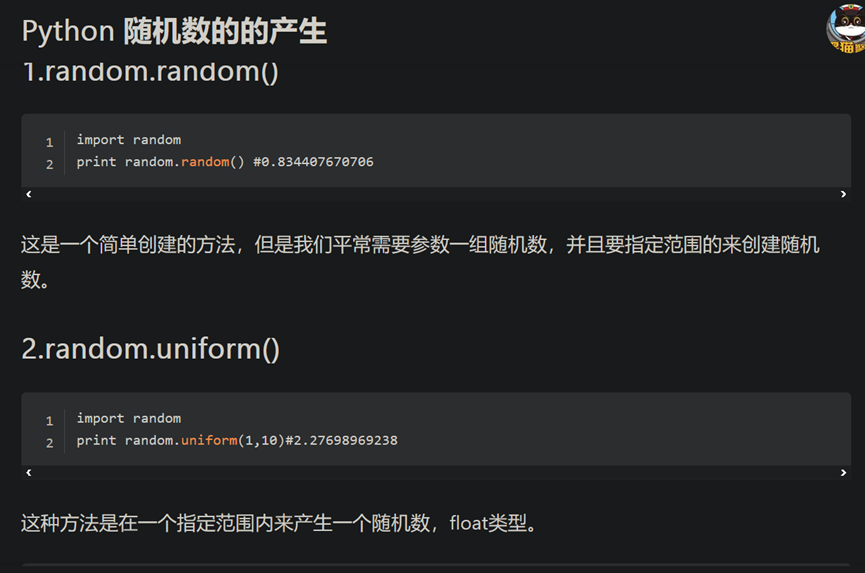

57.python操作txt,读取和删除某一行
with open(r"myfile.txt", "r", encoding="utf-8") as f:
for i in f.readlines():
def updateFile(file,old_str,new_str):
"""
替换文件中的字符串
:param file:文件名
:param old_str:就字符串
:param new_str:新字符串
:return:
"""
file_data = ""
with open(file, "r", encoding="utf-8") as f:
for line in f:
if old_str in line:
line = line.replace(old_str,new_str)
file_data += line
with open(file,"w",encoding="utf-8") as f:
f.write(file_data)
updateFile(r"myfile.txt", i, "")#将"D:\zdz\"路径的myfile.txt文件把所有的zdz改为daziran
58.找两个字符串里面相同的部分
#coding=utf-8
from collections import Counter
a = "黑龙江省首条N95型医用防护口罩生产线开工建设-正元地理信息-正元地理信息集团股份有限公司"
print(Counter(a))
# Counter({'d': 2, 'a': 1, 'b': 1, 'c': 1})
b = "法规速递第十九期 土地调查条例实施办法-正元地理信息-正元地理信息集团股份有限公司"
print(Counter(b))
# Counter({'a': 1, 'b': 1, 'd': 1})
c = Counter(a) & Counter(b)
#Counter({'a': 1, 'b': 1, 'd': 1})
print(c)
print("".join(c.keys()))
59.统计相同字段,数据 import collection
import collections
print(collections.Counter('asdfaa'))
60.print() 中忽略特殊字符 can’t encode
问题是这样的,网页的数据应该是’utf-8’编码,这个可以在网页的head上面看得到zd,然后你爬网页的时候会把它转化成Unicode,出问题的是在print()这儿,对于print()这个函数,他需要把内容转化为’gbk’编码才能显示出来. 然后解决办法是这样,你在转化后的Unicode编码的string后面,加上版 .encode(‘GBK’,’ignore’).decode(‘GBk’) 也就是先用gbk编码,忽略掉非法字符,然后再译码
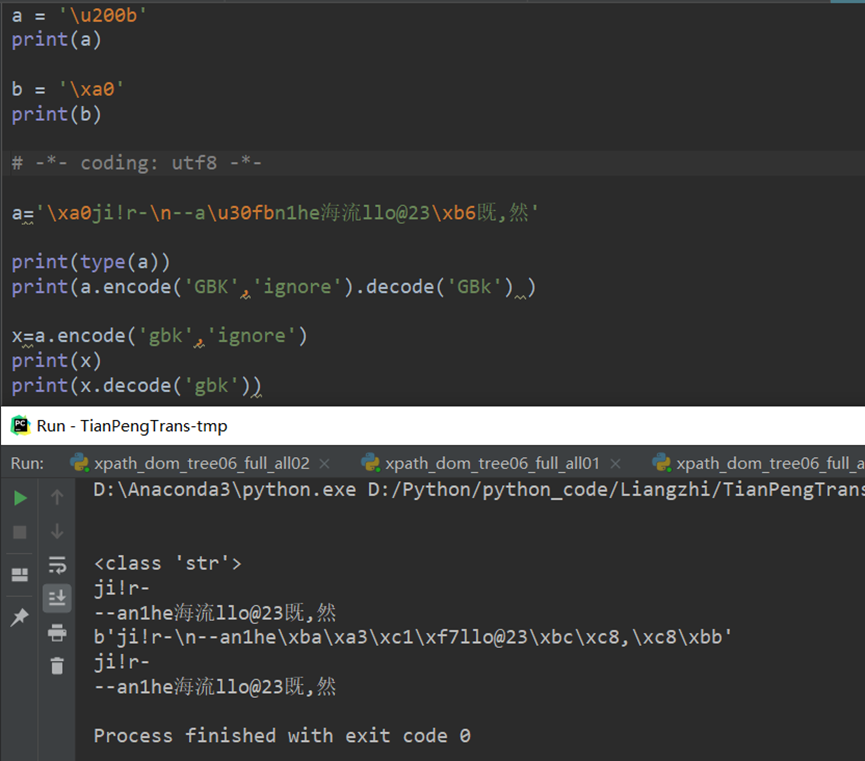
61.try…except…finally的用法
简单总结:
1.当执行try...except之间的语句序列没有发生异常时,则忽略异常处理部分(except)的语句。
2、Except括起来的语句,则只有在产生异常的情况下会被执行,其他情况一概不执行的。
3、Finally括起来的语句是铁定会被执行的,无论是否有异常产生;
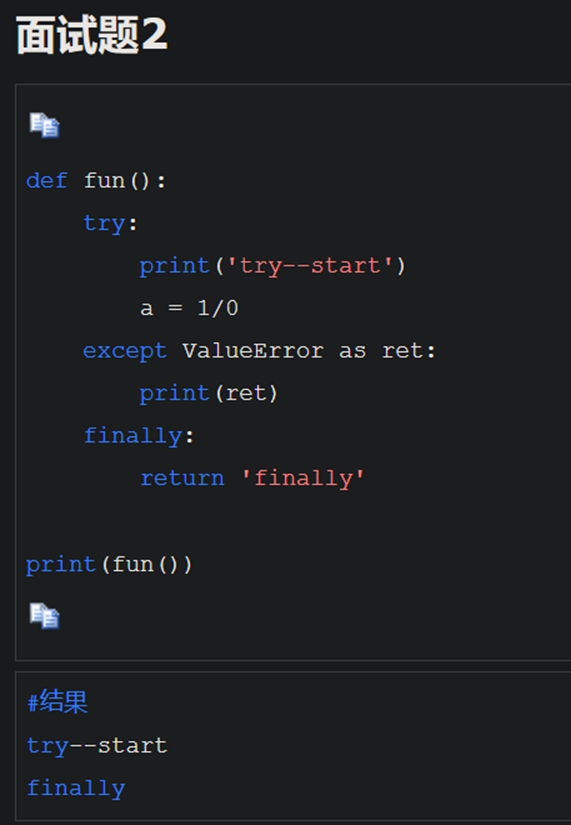
62.python 大小写转换 lower()、upper()、capitalize()、title()、swapcase()
https://www.cnblogs.com/leslie003/p/11390293.html
lower()、upper()、capitalize()、title()、swapcase()
这几个方法分别用来将字符串转换为小写、大写字符串、将字符串首字母变为大写、将每个首字母变为大写以及大小写互换
63.lambda规范日期
64.python .extend 用法 扩展列表,合并两个列表
aList = [123, 'xyz', 'zara', 'abc', 123];
bList = [2009, 'manni'];
aList.extend(bList)
print "Extended List : ", aList ;
65.dict.get() 获取dict的key值,没有key则返回空
66.traceback的用法

67.yield 的用法
https://pyzh.readthedocs.io/en/latest/the-python-yield-keyword-explained.html

68.python 中->的含义 表示函数返回类型
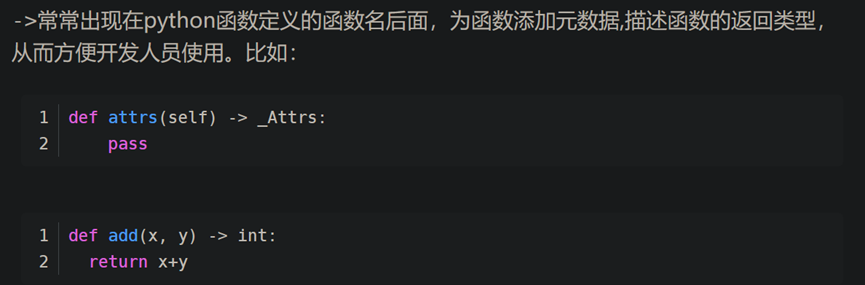
69.split 默认以 空格 切分
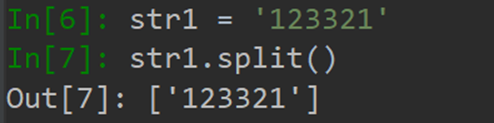
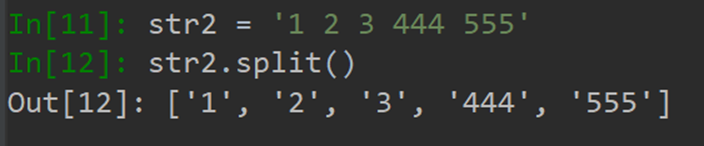
70.python 参数传入 *
前面加入*,会自动的将list或者tuple转化为可变参数传入
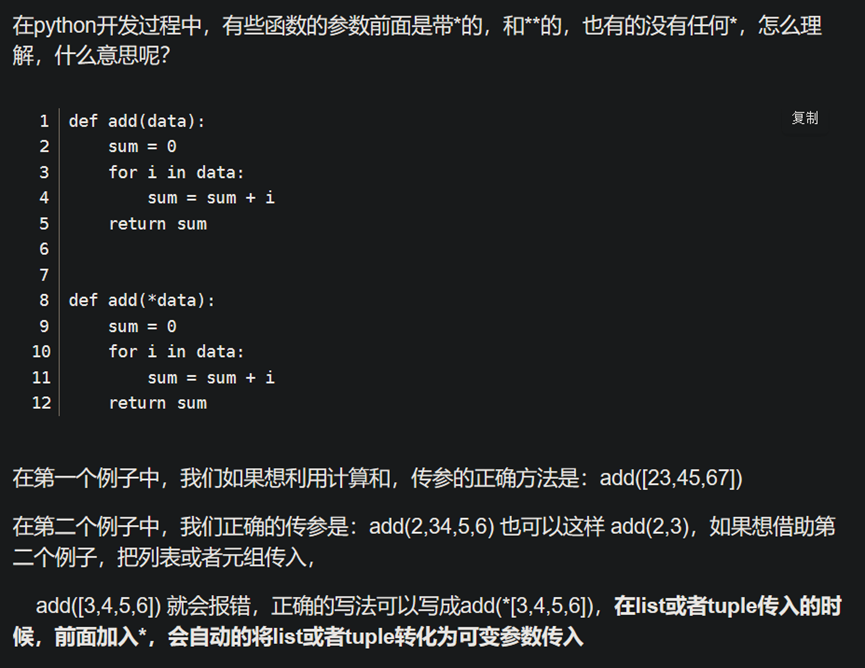
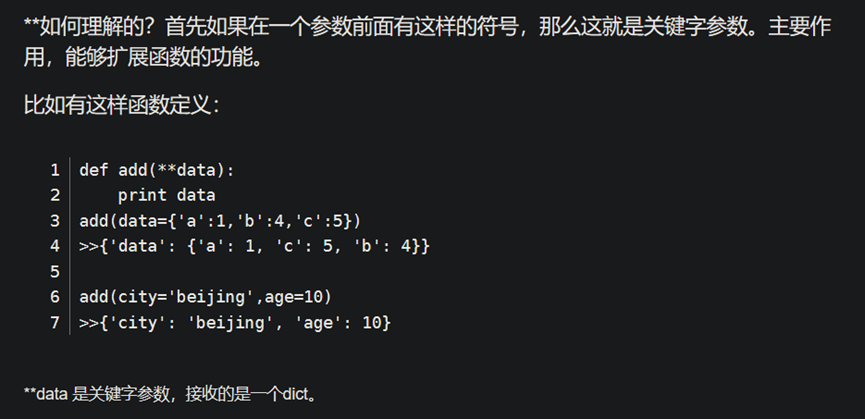
71. with…as语句是简化版的try except finally语句
72.import .abc这个表示导入当前文件夹下的一个包(而不是导入其他文件夹的包)
import ..abc 表示导入其他文件夹下的包
73.setup.py 安装模块的使用
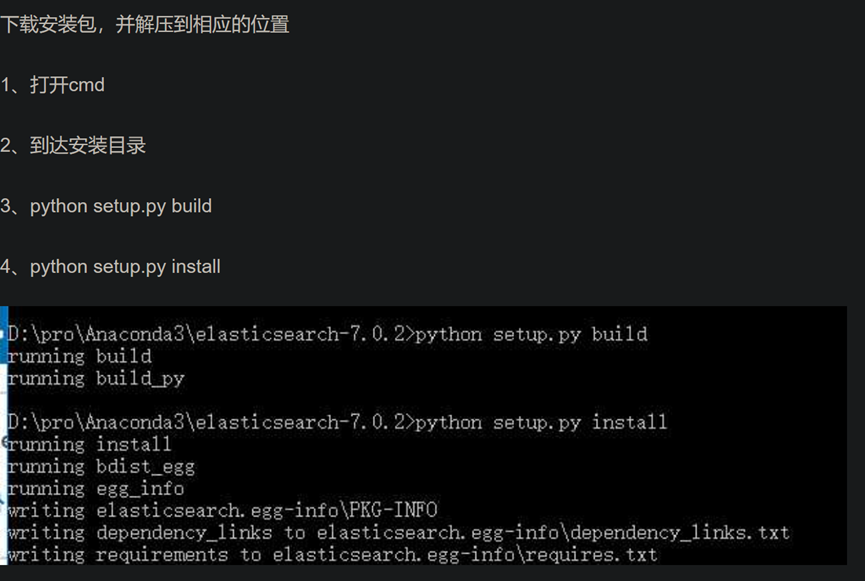
74.any() 函数
any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE。
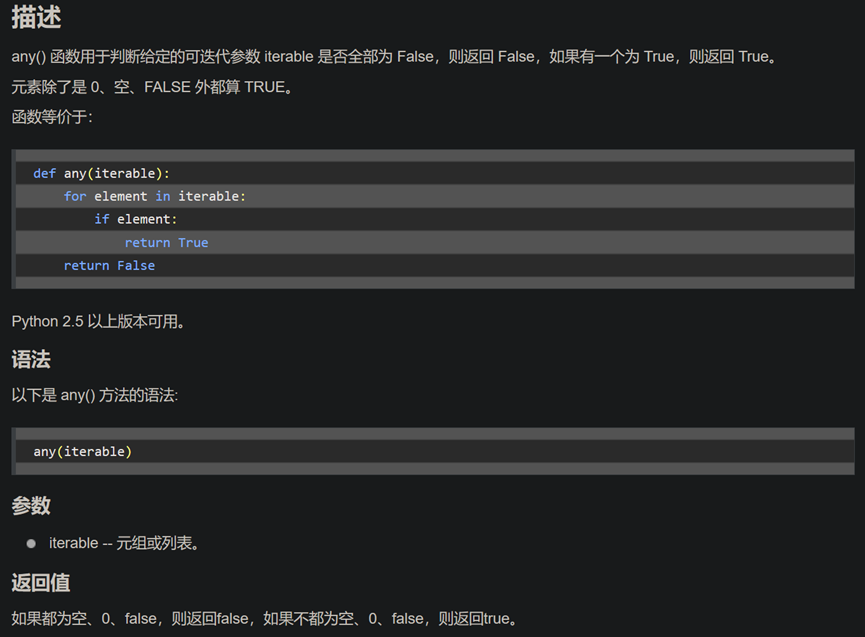
75.python raise 和 except 报错信息 抛出异常
当程序出现错误,python会自动引发异常,也可以通过raise显示地引发异常。一旦执行了raise语句,raise后面的语句将不能执行。
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
76.init.py 文件是如何工作的?
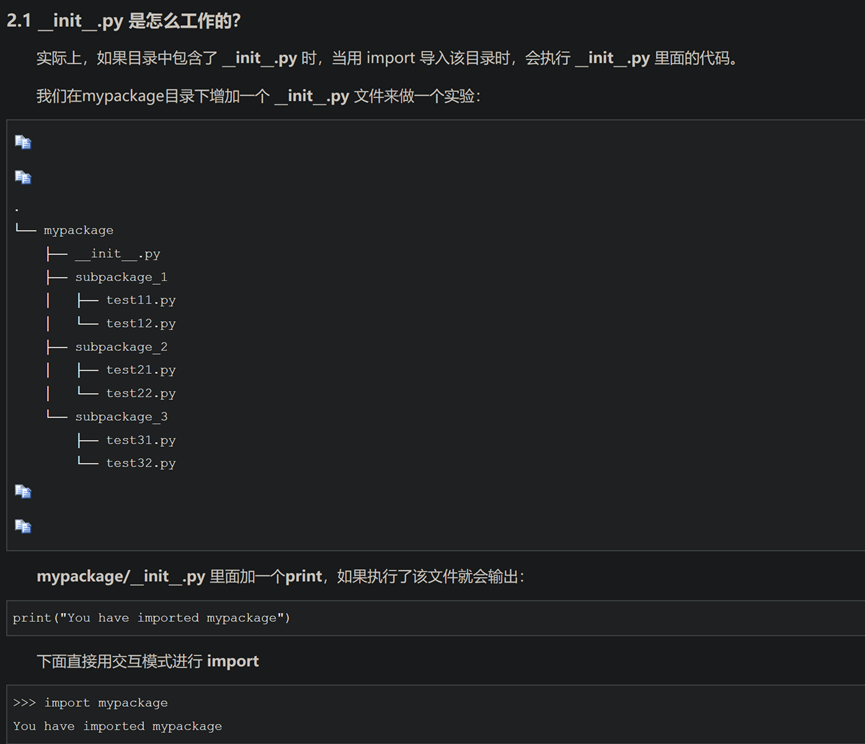
77.return self 的用法,链式调用
在Python中,return self的作用为:(英语原文,笔者水平有限,暂不翻译)
Returning self from a method simply means that your method returns a reference to the instance object on which it was called. This can sometimes be seen in use with object oriented APIs that are designed as a fluent interface that encourages method cascading.
通俗的说法是, allow chaining(这个是笔者自己的翻译: 链式调用).
78.[重要] 遍历dict的每一个value和子value
用递归方法:
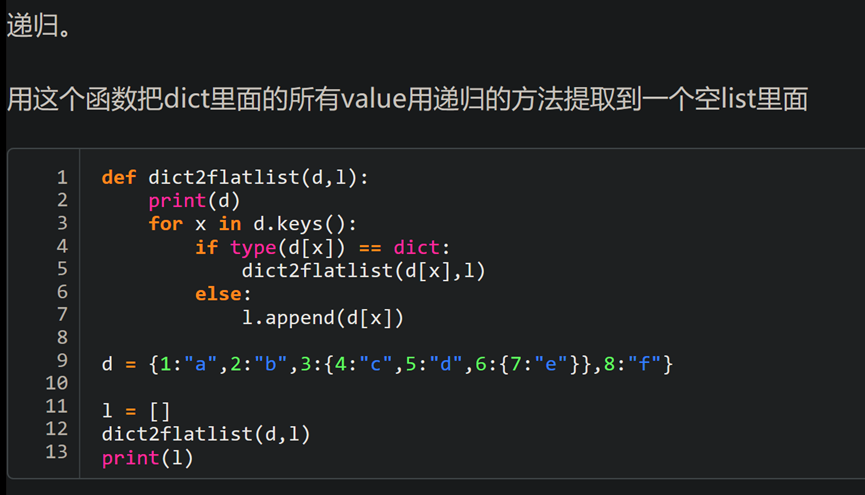
代码:
def dict2flatlist(d, l):
print(d)
for x in d.keys():
if type(d[x]) == dict:
dict2flatlist(d[x], l)
else:
l.append(d[x])
d = {1: "a", 2: "b", 3: {4: "c", 5: "d", 6: {7: "e"}}, 8: "f"}
l = []
dict2flatlist(d, l)
print(l)
79.python中 查看linux上的程序
import os
dict_name = {}
list_pid=os.popen('ps -ef | grep expert_cleaning').readlines()
flag_stop = 0
for key_name in dict_name.keys():
if key_name in str(list_pid):
flag_stop = 1
80.[重要] 给自己邮箱发信息 smtplib 模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
def em(message, send_email):
'''
:param message: 发送的信息
:param send_email: 接收人
:return:
'''
msg = MIMEText(message, 'plain', 'utf-8')
msg['From'] = Header("xxx@qq.com", 'utf-8') # 发送者
msg['To'] = Header("xxx@126.com", 'utf-8') # 接收者
# 标题
subject = 'Python SMTP 邮件测试'
msg['Subject'] = Header(subject, 'utf-8')
from_addr = "xxx@qq.com" # 发送人
password = "ppyghdwyyzjzecbj" # 发送人密码
smtp_server = "smtp.qq.com" # 邮箱的smtp服务器
# 网易邮箱SMTP smtp.163.com
# qq邮箱SMTP smtp.qq.com
to_addr = send_email # 接收人
server = smtplib.SMTP(smtp_server, 25)
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()
81.Python中可迭代对象是什么?
迭代:python中可以用for循环使用取值操作过程.
可迭代对象:可以使用for循环遍历的对象,我们称之为可迭代对象.
迭代器:提供数据和记录位置.
生成器:如果函数中有yield我们称之为生成器
常见的可迭代对象包括:
a) 集合数据类型,如list、tuple、dict、set、str等;
b) 生成器(generator),包括生成器和带yield的生成器函数(generator function)

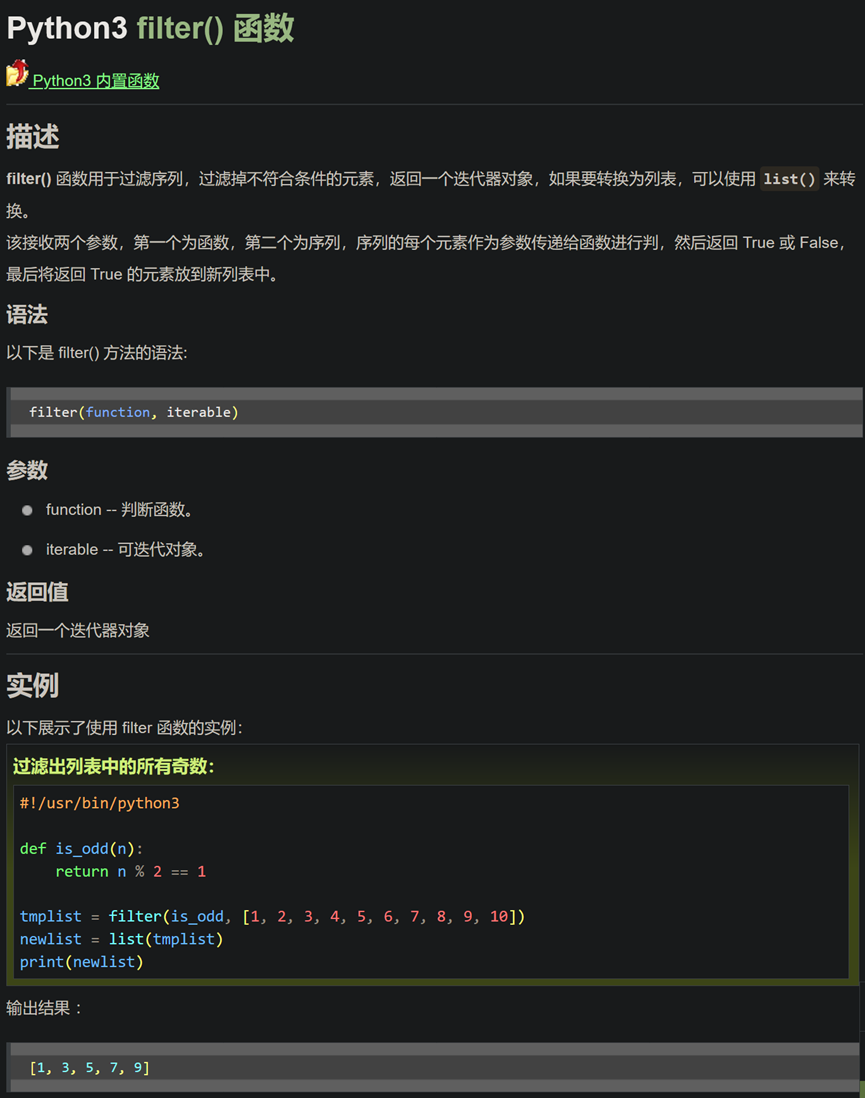
82.sys.argv[1] 的含义
argv[0]代表模块文件名、argv[1]代表传入的第一个命令行参数
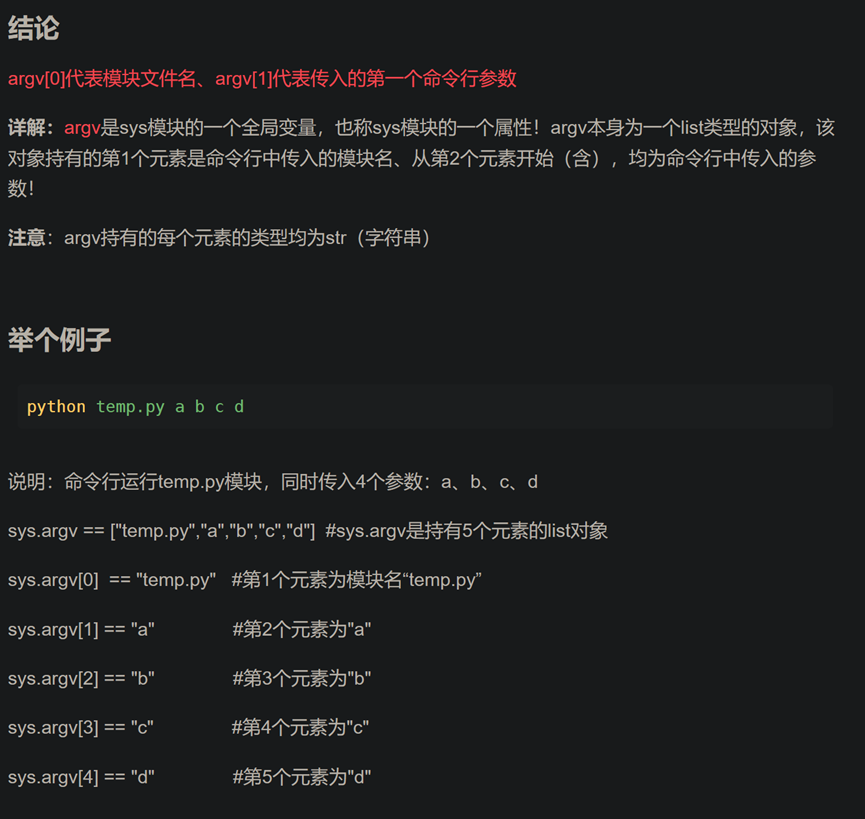
83.列表去重复 sorted(set(listA), key = listA.index)
两种不同方法:
不按照原来顺序去重
l1 = [1,4,4,2,3,4,5,6,1]
l2 = list(set(l1))
print(l2) # [1, 2, 3, 4, 5, 6]
按照原来顺序去重
listA = ['python','语','言','是','一','门','动','态','语','言']
print(sorted(set(listA), key = listA.index))
orgList = [1,0,3,7,7,5]
formatList = list(set(orgList))
formatList.sort(key=orgList.index)
print (formatList)
83.Python中的list和C中的数组有什么区别?
-
空间效率
C语言中,创建数组时,首先需要指定数组的容量大小,根据大小来分配内存,也就是说,即使要在数组中存储一个元素,也需要为所有的元素预先的分配内存。故,C语言中数组的空间效率不高。 Python中,列表list属于其的一个高级特性,是对源码中对象(PyListObject)的一个抽象,而因为不同的list存储元素的个数不同,故这里的PyListObject再创立之初就被设置为变长对象。并且,该对象中内置了像插入、删除等方法,可以在运行时动态的调整维护的内存和元素 总结:C语言数组相较Python List空间效率低,灵活性较差 -
长度
C语言中,除了动态数组以外,数组都是不可变的。 Python中,对象中封装了插入、删除等方法,所以List是可变的。 -
数据类型
C语言中,数组中的元素只能是同一种类型,在数组初始化时已经确定。 Python中,数组中的元素可以是不同的类型。 接下来回答第二个问题,相比于list,数组岂不是更像tuple? 数组中的元素可以改变,同时,list底层实现对象中也封装了插入删除等操作,而tuple中的元素一经创建,不可修改,和数组的特性不符。
84.tqdm的详细使用
84.1 第一次使用
https://www.jb51.net/article/166648.htm
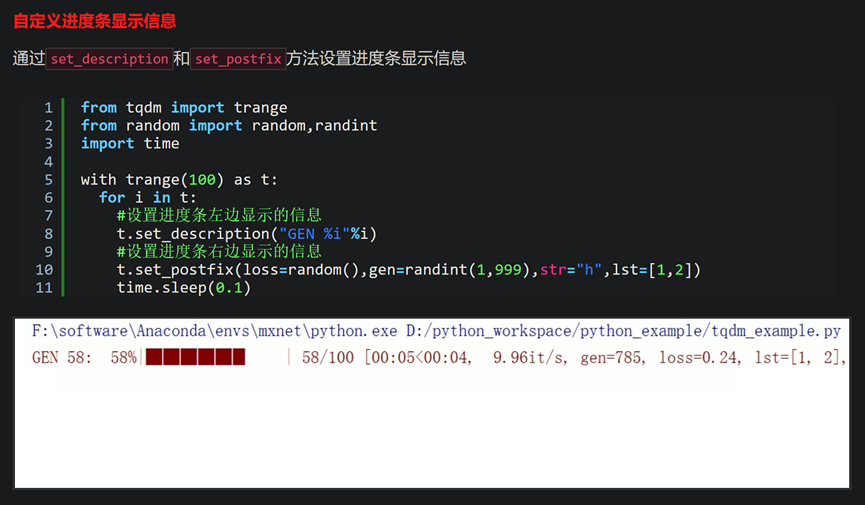
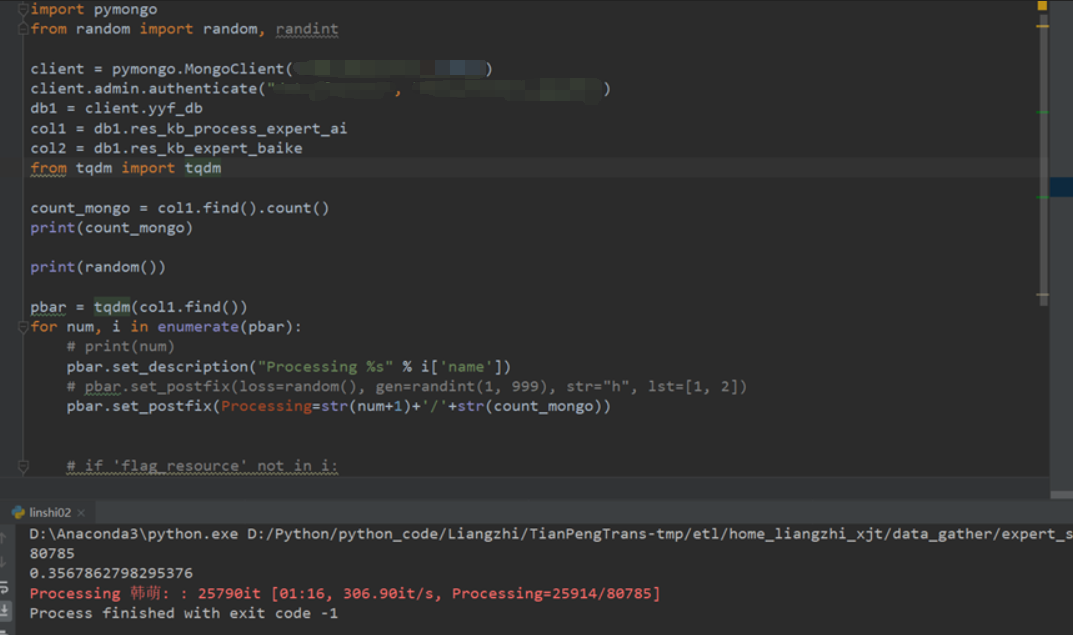
代码
import pymongo
from random import random, randint
client = pymongo.MongoClient('xxxx', 00000)
client.admin.authenticate("xxxx", "xxxx")
db1 = client.yyf_db
col1 = db1.res_kb_process_expert_ai
col2 = db1.res_kb_expert_baike
from tqdm import tqdm
count_mongo = col1.find().count()
print(count_mongo)
print(random())
pbar = tqdm(col1.find())
for num, i in enumerate(pbar):
# print(num)
pbar.set_description("Processing %s" % i['name'])
# pbar.set_postfix(loss=random(), gen=randint(1, 999), str="h", lst=[1, 2])
pbar.set_postfix(Processing=str(num+1)+'/'+str(count_mongo))
84.1 第二次使用
https://zhuanlan.zhihu.com/p/163613814
import time
from tqdm import tqdm, trange
#trange(i)是tqdm(range(i))的一种简单写法
for i in trange(100):
time.sleep(0.05)
for i in tqdm(range(100), desc='Processing'):
time.sleep(0.05)
dic = ['a', 'b', 'c', 'd', 'e']
pbar = tqdm(dic)
for i in pbar:
pbar.set_description('Processing '+i)
time.sleep(0.2)
'''
100%|██████████| 100/100 [00:06<00:00, 16.04it/s]
Processing: 100%|██████████| 100/100 [00:06<00:00, 16.05it/s]
Processing e: 100%|██████████| 5/5 [00:01<00:00, 4.69it/s]
'''
85.Python常用模块
https://zhuanlan.zhihu.com/p/166015298
86.每天定时运行某程序代码
import time
while True:
time_now = time.strftime("%H:%M:%S", time.localtime()) # 刷新
if time_now == "08:30:10": # 此处设置每天定时的时间

87.append 加入列表
1.深浅拷贝
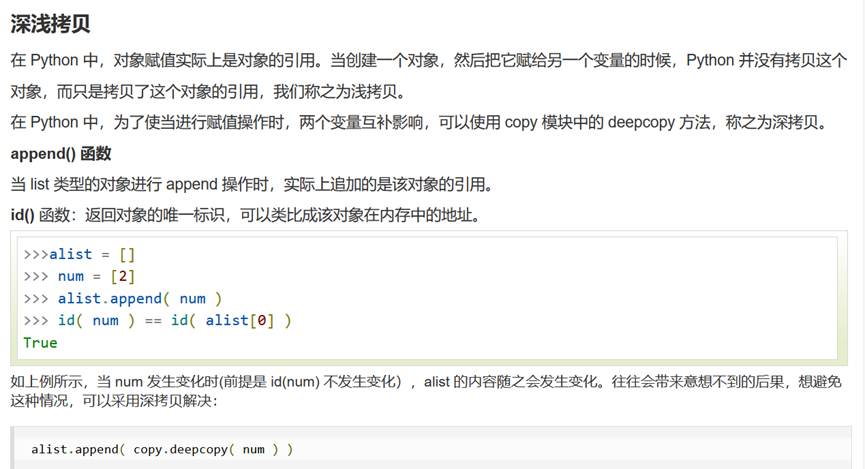
list.append( num )
删除字符串 s[:-3]
p.s. 取第几行的结果
start_time = str(title).split(‘\n’)[1].replace(‘ ‘, ‘’).replace(‘&’,’’).replace(‘举办时间:’,’’)
ls1 = [1,2,3,4,5,6]
ls2 = [1,2,3,4,5,6]
ls1.append(12)
可以添加列表,字典,元组,集合,字符串等
ls2.append([1,”a”]) #添加列表
ls2.append({2:”a”,3:”hj”}) #添加字典
ls2.append((1,”k”,3)) #添加元组
ls2.append({“1”,”2”,”h”}) #添加集合
ls2.append(“123abc”) #添加字符串
print(ls1.append(12)) #无返回值
print(ls1) #append()函数的操作对象是原列表。
print(ls2)
结果:
None
[1, 2, 3, 4, 5, 6, 12, 12]
[1, 2, 3, 4, 5, 6, [1, ‘a’], {2: ‘a’, 3: ‘hj’}, (1, ‘k’, 3), {‘2’, ‘1’, ‘h’}, ‘123abc’]
88.python list 4种添加元素的方式
第一种:
>>> list1=['a','b']
>>> list1.append('c')
>>> list1
['a', 'b', 'c']
第二种:
>>> list1
['a', 'b', 'c']
>>> list1.extend('d')
>>> list1
['a', 'b', 'c', 'd']
第三种:
>>> list1
['a', 'b', 'c', 'd']
>>> list1.insert(1,'x')
>>> list1
['a', 'x', 'b', 'c', 'd']
第四种:
>>> list1
['a', 'x', 'b', 'c', 'd']
>>> list2=['y','z']
>>> list3=list1+list2
>>> list3
['a', 'x', 'b', 'c', 'd', 'y', 'z']
89.dict 的 items 的使用 https://www.runoob.com/python/att-dictionary-items.html
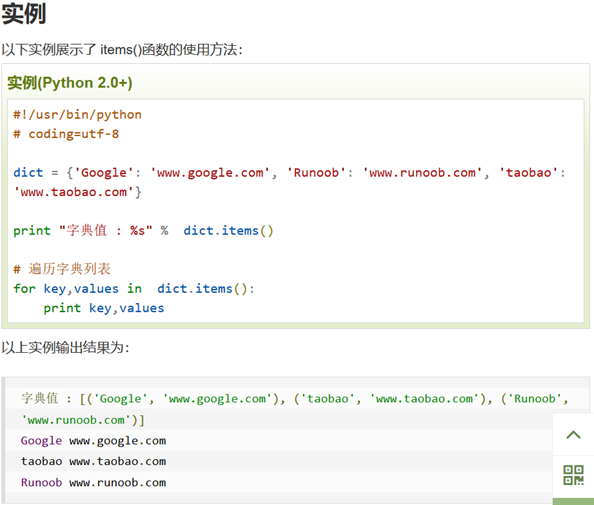
(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组
for key, values in dict.items():
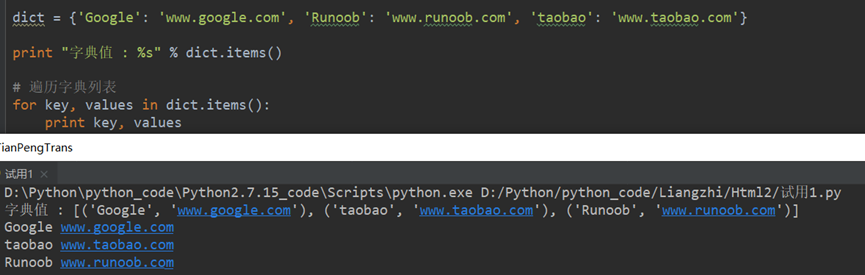
“字典值 : %s” % dict.items()
90.flag 的使用 跳过已经抓取过的栏目
e.g.
91.获取某个字符串后的部分

92.字符串—固定长度分割字符串
https://www.cnblogs.com/JIM-FAN/p/12904777.html
import re
import math
string = '123456789abcdefg'
# 方法一:递归实现
text_list = []
def split_text(text, length):
tmp = text[:int(length)]
# print(tmp)
# 将固定长度的字符串添加到列表中
text_list.append(tmp)
# 将原串替换
text = text.replace(tmp, '')
if len(text) < length + 1:
# 直接添加或者舍弃
text_list.append(text)
else:
split_text(text, length)
return text_list
print(split_text(string, 3)) # ['123', '456', '789', 'abc', 'def', 'g']
# 方法二
def split_text2(text, length):
text_arr = re.findall(r'.{ %d}' % int(length), text)
print(text_arr) # ['123', '456', '789', 'abc', 'def']
split_text2(string, 3)
# 方法三
def split_text3(text, length):
text_list = []
group_num = len(text) / int(length)
print(group_num) # 5.333333333333333
group_num = math.ceil(group_num) # 向上取整
for i in range(group_num):
tmp = text[i * int(length):i * int(length) + int(length)]
# print(tmp)
text_list.append(tmp)
return text_list
print(split_text3(string, 3)) # ['123', '456', '789', 'abc', 'def', 'g']
93.高性能处理标点符号,快速删除标点符号
http://www.cocoachina.com/articles/46102
只能去除英文标点
代码:
import string
import re
abstract = ''
stringIn = abstract
out = stringIn.translate(stringIn.maketrans("", ""), string.punctuation)
def pd_replace(df):
return df.assign(text=df['text'].str.replace(r'[^\w\s]+', ''))
def re_sub(df):
p = re.compile(r'[^\w\s]+')
return df.assign(text=[p.sub('', x) for x in df['text'].tolist()])
def translate(df):
punct = string.punctuation.replace('|', '')
transtab = str.maketrans(dict.fromkeys(punct, ''))
return df.assign(
text='|'.join(df['text'].tolist()).translate(transtab).split('|')
)
# MaxU's version (https://stackoverflow.com/a/50444659/4909087)
def pd_translate(df):
punct = string.punctuation.replace('|', '')
transtab = str.maketrans(dict.fromkeys(punct, ''))
return df.assign(text=df['text'].str.translate(transtab))
from timeit import timeit
import pandas as pd
import matplotlib.pyplot as plt
res = pd.DataFrame(
index=['pd_replace', 're_sub', 'translate', 'pd_translate'],
columns=[10, 50, 100, 500, 1000, 5000, 10000, 50000],
dtype=float
)
for f in res.index:
for c in res.columns:
l = ['a..b?!??', '%hgh&12','abc123!!!', '$$$1234'] * c
df = pd.DataFrame({'text' : l})
stmt = '{}(df)'.format(f)
setp = 'from __main__ import df, {}'.format(f)
res.at[f, c] = timeit(stmt, setp, number=30)
ax = res.div(res.min()).T.plot(loglog=True)
ax.set_xlabel("N");
ax.set_ylabel("time (relative)");
plt.show()
94.复杂list排序
https://www.cnblogs.com/wind-wang/p/5804489.html
# 复杂的dict,按照dict对象中某一个属性进行排序
lst = [{'level': 19, 'star': 36, 'time': 1},
{'level': 20, 'star': 40, 'time': 2},
{'level': 20, 'star': 40, 'time': 3},
{'level': 20, 'star': 40, 'time': 4},
{'level': 20, 'star': 40, 'time': 5},
{'level': 18, 'star': 40, 'time': 1}]
# 需求:
# level越大越靠前;
# level相同, star越大越靠前;
# level和star相同, time越小越靠前;
# 先按time排序
lst.sort(key=lambda k: (k.get('time', 0)))
# 再按照level和star顺序
# reverse=True表示反序排列,默认正序排列
lst.sort(key=lambda k: (k.get('level', 0), k.get('star', 0)), reverse=True)
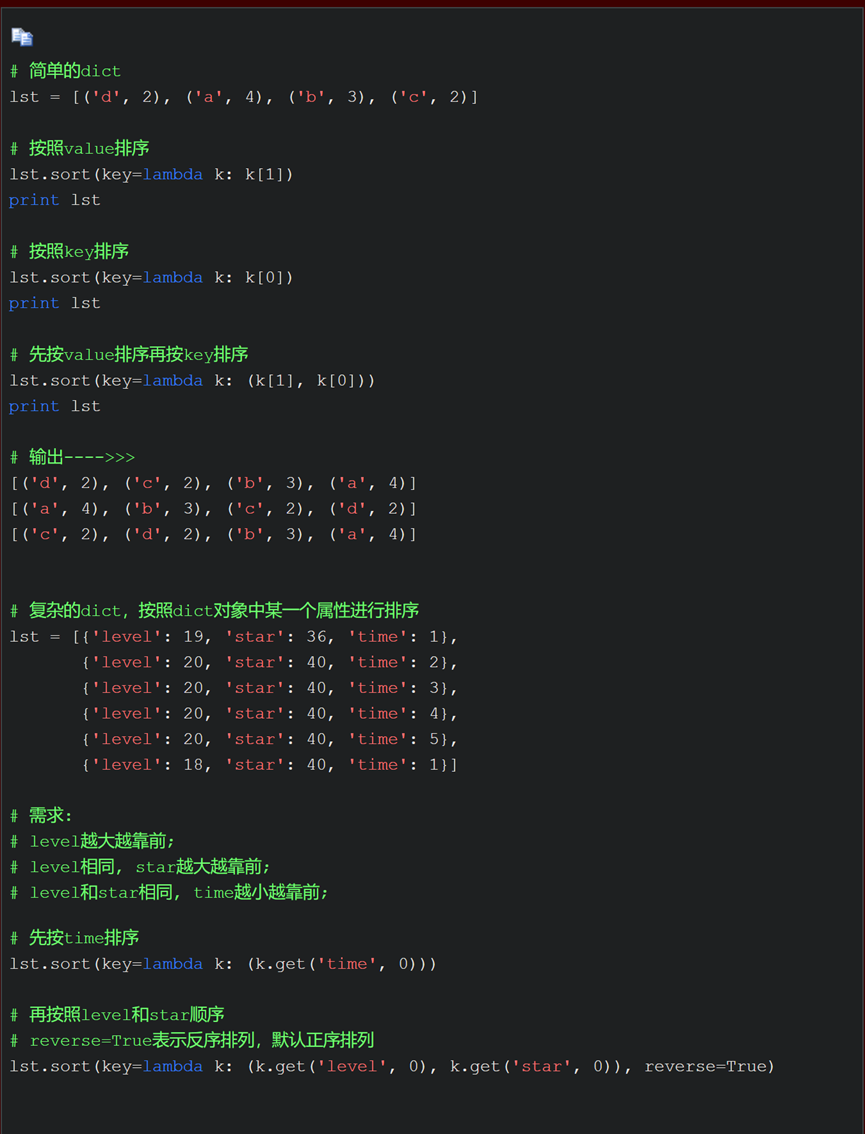
95.python 获取当前文件名字
import os
import sys
print(__file__)
print(sys.argv[0])
print(os.path.dirname(__file__))
print(os.path.split(__file__))
print(os.path.split(__file__)[-1])
print(os.path.split(__file__)[-1].split(".")[0])
96.python str 函数 魔法函数
总结:
• 在python中方法名如果是__xxxx__()的,那么就有特殊的功能,因此叫做“魔法”方法
• 当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
• __str__方法需要返回一个字符串,当做这个对象的描写
定义 __str__() 方法:
class Cat:
"""定义一个猫类"""
def __init__(self, new_name, new_age):
"""在创建完对象之后 会自动调用, 它完成对象的初始化的功能"""
# self.name = "汤姆"
# self.age = 20
self.name = new_name
self.age = new_age # 它是一个对象中的属性,在对象中存储,即只要这个对象还存在,那么这个变量就可以使用
# num = 100 # 它是一个局部变量,当这个函数执行完之后,这个变量的空间就没有了,因此其他方法不能使用这个变量
def __str__(self):
"""返回一个对象的描述信息"""
# print(num)
return "名字是:%s , 年龄是:%d" % (self.name, self.age)
def eat(self):
print("%s在吃鱼...." % self.name)
def drink(self):
print("%s在喝可乐..." % self.name)
def introduce(self):
# print("名字是:%s, 年龄是:%d" % (汤姆的名字, 汤姆的年龄))
# print("名字是:%s, 年龄是:%d" % (tom.name, tom.age))
print("名字是:%s, 年龄是:%d" % (self.name, self.age))
# 创建了一个对象
tom = Cat("汤姆", 30)
print(tom)
97.python 虚拟环境
https://www.cnblogs.com/quietCorner/p/11044382.html
什么是python虚拟环境?
通俗的来讲,虚拟环境就是从电脑独立开辟出来的环境,相当于一个副本或备份,在这个环境你可以安装私有包,而且不会影响系统中安装的全局Python解释器。
安装步骤
Pip install virtualenv
创建虚拟环境
选择创建虚拟环境的目录
virtualenv webUI 虚拟环境名
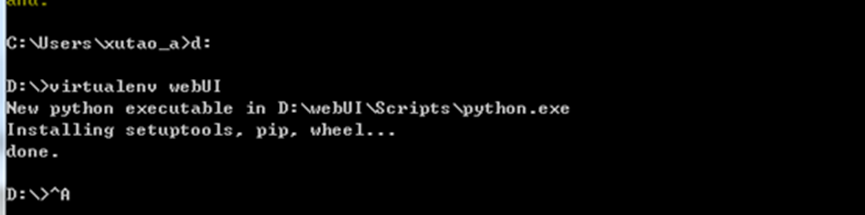
进入虚拟环境
进入到新建的虚拟环境目录,查看并运行activate.bat
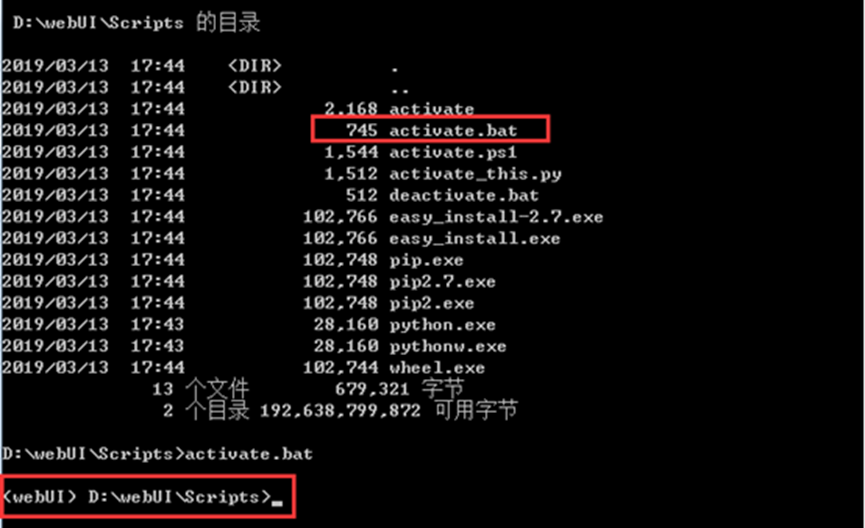
退出虚拟环境
运行deactivate.bat
导出已安装模块包信息
pip freeze >requirements.txt
复制python环境
1、创建python虚拟环境 virtualenv dicmp
2、进入虚拟环境dicmp
3、安装必备的测试库 pip install -r E:requirements.txt
98.os._exit() 和 sys.exit()
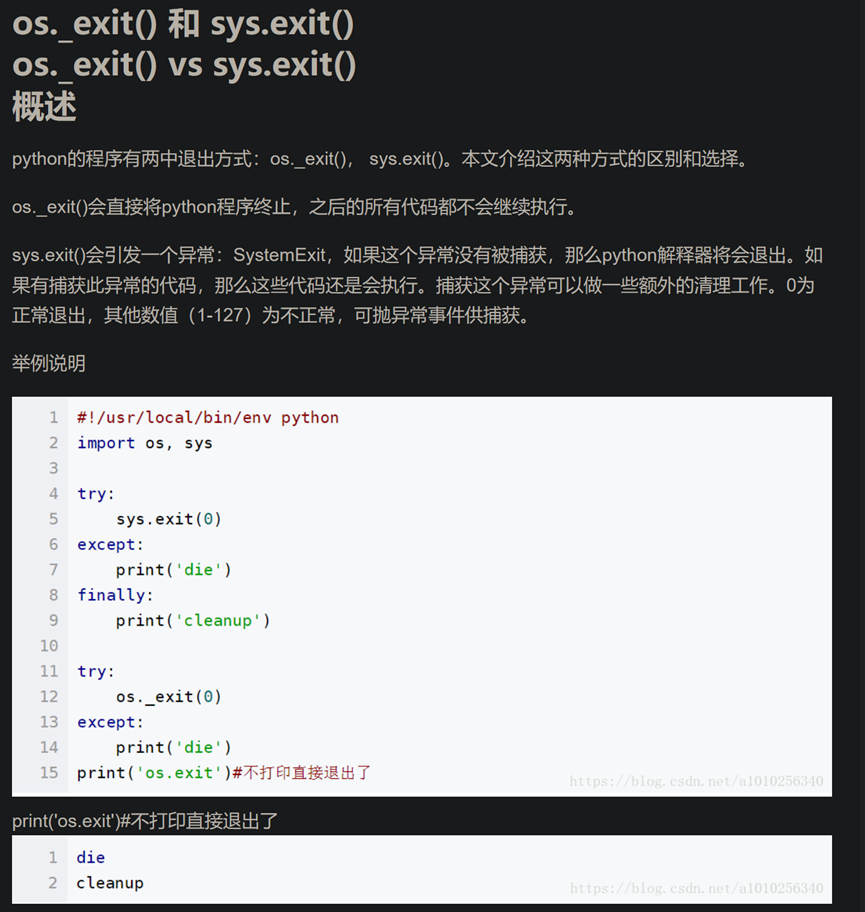
99.signal模块 信号块 ctrl+c 退出脚本
https://blog.csdn.net/ashe_1994/article/details/104389318

import signal
import sys
import time
def quit(signum, frame):
sys.exit(0)
if __name__ == "__main__":
## SIGINT 终止进程 中断进程
signal.signal(signal.SIGINT, quit)
## signal.signal(signal.SIGTERM, quit)
while True:
time.sleep(1)
100.[重要] Python 配置文件
100.1 常用配置文件格式比较
配置文件:properties josn yaml hocon ini hocon
HOCON(Human-Optimized Config Object Notation)是一个易于使用的配置文件格式。它被用于 Sponge 以及利用 Sponge API 的独立插件以储存重要的数据,比如配置或者玩家数据。HOCON 文件通常以 .conf 作为后缀名。
100.2 python读取 ini配置文件
https://www.cnblogs.com/hanmk/p/9843136.html
# 读取配置文件
import configparser
cf = configparser.ConfigParser()
cf.read("E:\Crawler\config.ini") # 读取配置文件,如果写文件的绝对路径,就可以不用os模块
secs = cf.sections() # 获取文件中所有的section(一个配置文件中可以有多个配置,如数据库相关的配置,邮箱相关的配置, 每个section由[]包裹,即[section]),并以列表的形式返回
print(secs)
options = cf.options("Mysql-Database") # 获取某个section名为Mysql-Database所对应的键
print(options)
items = cf.items("Mysql-Database") # 获取section名为Mysql-Database所对应的全部键值对
print(items)
host = cf.get("Mysql-Database", "host") # 获取[Mysql-Database]中host对应的值
print(host)
# 写入配置文件
from configparser import ConfigParser
config = ConfigParser.ConfigParser()
# set a number of parameters
config.add_section("CoarseAdjust")
config.set("CoarseAdjust", "xperangle", "1000")
config.set("CoarseAdjust", "yperangle", "500")
101.引用上级目录下的文件
上级引用
import sys
sys.path.append("..")
上上级引用
import sys
sys.path.append("...")
102.python 读取excel文件
import xlrd
# 打开文件
data = xlrd.open_workbook('excel_file/seniorManager_neo.xlsx')
# 查看工作表
data.sheet_names()
print("sheets:" + str(data.sheet_names()))
# 通过文件名获得工作表,获取工作表1
table = data.sheet_by_name('Sheet1')
# 打印data.sheet_names()可发现,返回的值为一个列表,通过对列表索引操作获得工作表1
# table = data.sheet_by_index(0)
# 获取行数和列数
# 行数:table.nrows
# 列数:table.ncols
print("总行数:" + str(table.nrows))
print("总列数:" + str(table.ncols))
# 获取整行的值 和整列的值,返回的结果为数组
# 整行值:table.row_values(start,end)
# 整列值:table.col_values(start,end)
# 参数 start 为从第几个开始打印,
# end为打印到那个位置结束,默认为none
print("整行值:" + str(table.row_values(0)))
print("整列值:" + str(table.col_values(3)))
print(type(table.col_values(3)))
# 获取某个单元格的值,例如获取B3单元格值
cel_B3 = table.cell(3,2).value
print("第三行第二列的值:" + cel_B3)
list_a = table.col_values(3)
list_b = table.col_values(4)
with open('manager.txt', 'a+', encoding='utf-8') as f:
for num, i1 in enumerate(list_a):
f.write(i1+'\t' +list_b[num] + '\n')
103. python platform模块
https://blog.csdn.net/bbwangj/article/details/93652876
import platform
import subprocess
from functools import partial
# 此行代码用于windows执行,放到linux上后需要注释掉
if platform.system().lower() == 'windows':
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
elif platform.system().lower() == 'linux':
pass
import platform
print(platform.platform()) #获取操作系统名称及版本号,'Windows-7-6.1.7601-SP1'
print(platform.version()) #获取操作系统版本号,'6.1.7601'
print(platform.architecture()) #获取操作系统的位数,('32bit', 'WindowsPE')
print(platform.machine()) #计算机类型,'x86'
print(platform.node()) #计算机的网络名称,'hongjie-PC'
print(platform.processor()) #计算机处理器信息,'x86 Family 16 Model 6 Stepping 3, AuthenticAMD'
print(platform.uname()) #包含上面所有的信息汇总,uname_result(system='Windows', node='hongjie-PC',release='7', version='6.1.7601', machine='x86', processor='x86 Family
104.python partial 偏函数
https://zhuanlan.zhihu.com/p/47124891
from functools import partial
def add(*args):
return sum(args)
add_100 = partial(add, 100)
print(add_100(1, 2, 3)) # 106
add_101 = partial(add, 101)
print(add_101(1, 2, 3)) # 107
105.python if - else写在一行
在python代码中,经常会出现if - else出现在一行,且格式非正常的条件语句。 好处:简约,节省行数 但初次接触可能会有一些不习惯,不能很快理解。。 例如:
num = 1 if param > 10 else 0
等同于:
if param > 10 :
num = 1
else:
num = 0
例如:
num = 1 if param > 10 else 2 if param == 10 else 0
等同于:
if param > 10 :
num = 1
elif param == 10:
num = 2
else:
num = 0
106.python os 复制文件
#文件复制
import os
src_path=r'E:\Pycharm\python100题\代码'
target_path=r'E:\Pycharm\python100题\123'
#封装成函数
def copy_function(src,target):
if os.path.isdir(src) and os.path.isdir(target):
filelist=os.listdir(src)
for file in filelist:
path=os.path.join(src,file)
if os.path.isdir(path):
copy_function(path,target)
with open(path,'rb') as rstream:
container=rstream.read()
path1=os.path.join(target,file)
with open(path1,'wb') as wstream:
wstream.write(container)
else:
print('复制完毕!')
copy_function(src_path,target_path)
#改进后的文件复制,可以递归复制文件,之前的文件复制不能复制文件夹
import os
src_path=r'E:\Pycharm\python100题\代码'
target_path=r'E:\Pycharm\python100题\123'
def copy_function(src,target):
if os.path.isdir(src) and os.path.isdir(target):
filelist=os.listdir(src)
for file in filelist:
path=os.path.join(src,file)
if os.path.isdir(path): #判断是否为文件夹
target1=os.path.join(target,file)
os.mkdir(target1) #在目标文件下在创建一个文件夹
copy_function(path,target1)
else:
with open(path, 'rb') as rstream:
container = rstream.read()
path1 = os.path.join(target, file)
with open(path1, 'wb') as wstream:
wstream.write(container)
else:
print('复制完毕!')
copy_function(src_path, target_path)
107.python 备份文件 完整版
完整版,其他为学习版本
# -*-coding:utf-8-*-
# ===============================================================================
# 目录对比工具(包含子目录 ),并列出
# 1、A比B多了哪些文件
# 2、B比A多了哪些文件
# 3、二者相同的文件:文件大小相同 VS 文件大小不同 (Size相同文件不打印:与Size不同文件显示未排序)
# 完整版
# ===============================================================================
# import sys
# sys.path.append('D:\TianPengTrans-tmp\etl')
import os, time, difflib
import shutil # shutil全称是shell utilities
import datetime
import hashlib
from etl.basic.backup_test.get_file_size_and_num import GetFileSizeAndNum # 写完整路径
AFILES = [] # EE
BFILES = [] # SVN
COMMON = [] # EE & SVN
def getPrettyTime(state):
return time.strftime('%y-%m-%d %H:%M:%S', time.localtime(state.st_mtime))
# def getpathsize(dir): #获取文件大小的函数,未用上,仅供学习.故注释掉
# size=0
# for root, dirs, files in os.walk(dir):
# #root:目录:str 如: C:\CopySVN\SystemObject\TopoProcedure\Built-in\
# #dirs:目录名称:列表: 如 ['Parsers']
# #files:名称:列表: 如 ['011D0961FB42416AA49D5E82945DE7E9.og',...]
# #file:目录:str, 如 011D0961FB42416AA49D5E82945DE7E9.og
# for file in files:
# path = os.path.join(root,file)
# size = os.path.getsize(path)
# return size
def dirCompare(apath, bpath):
afiles = []
bfiles = []
for root, dirs, files in os.walk(apath):
for f in files:
afiles.append(root + "\\" + f)
for root, dirs, files in os.walk(bpath):
for f in files:
bfiles.append(root + "\\" + f)
# sizeB = os.path.getsize(root + "\\" + f) 此处定义的size无法在commonfiles进行比较. (A,B在各自的循环里面)
# 去掉afiles中文件名的apath (拿A,B相同的路径\文件名,做成集合,去找交集)
apathlen = len(apath)
aafiles = []
for f in afiles:
aafiles.append(f[apathlen:])
# 去掉bfiles中文件名的bpath
bpathlen = len(bpath)
bbfiles = []
for f in bfiles:
bbfiles.append(f[bpathlen:])
afiles = aafiles
bfiles = bbfiles
setA = set(afiles)
setB = set(bfiles)
# print('%$%'+str(len(setA)))
# print('%%'+str(len(setB)))
commonfiles = setA & setB # 处理共有文件
# print ("===============File with different size in '", apath, "' and '", bpath, "'===============")
# 将结果输出到本地
with open(os.getcwd()+'\\diff.txt','w') as di:
now_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
di.write("now_time:" + now_time + " "+"===============File with different size in '" + apath + "' and '" + bpath + "'===============")
for f in sorted(commonfiles):
sA = os.path.getsize(apath + "\\" + f)
sB = os.path.getsize(bpath + "\\" + f)
if sA == sB: # 共有文件的大小比较
# pass #print (f + "\t\t" + getPrettyTime(os.stat(apath + "\\" + f)) + "\t\t" + getPrettyTime(os.stat(bpath + "\\" + f)))
# TODO 以下代码是处理大小一致,但是内容可能不一致的情况,则把A的覆盖B的
hashlibA = readfile(apath + "\\" + f)
hashlibB = readfile(bpath + "\\" + f)
if hashlibA != hashlibB:
shutil.copyfile(apath + "\\" + f, bpath + "\\" + f)
# TODO 如果两个文件夹下的同名文件大小不同,则把A的覆盖B的
else:
with open(os.getcwd() + '\\diff.txt', 'a') as di:
di.write("now_time:" + now_time + " "+"File Name=%s EEresource file size:%d != SVN file size:%d" % (f, sA, sB) + '\n')
print("File Name=%s EEresource file size:%d != SVN file size:%d" %(apath + "\\" + f,sA,sB))
shutil.copyfile(apath + "\\" + f, bpath + "\\" + f)
# TODO 处理仅出现在一个目录中的文件,A中多的拷贝到B,B中多的删除,与A同步
onlyFiles = setA ^ setB
aonlyFiles = []
bonlyFiles = []
for of in onlyFiles:
if of in afiles:
aonlyFiles.append(of)
elif of in bfiles:
bonlyFiles.append(of)
# print ("###################### EE resource ONLY ###########################")
# print ("#only files in ", apath)
for of in sorted(aonlyFiles):
with open(os.getcwd() + '\\EEonly.txt', 'a') as ee:
ee.write("now_time:" + now_time + " "+of + '\n')
# print('add: %s' % of)
shutil.copyfile(apath + of, bpath + of)
# print ("*"*20+"SVN ONLY+"+"*"*20)
# print ("#only files in ", bpath)
for of in sorted(bonlyFiles):
with open(os.getcwd() + '\\svnonly.txt', 'a') as svn:
svn.write("now_time:" + now_time + " "+of + '\n')
print('delete: %s' % of)
os.remove(bpath + of)
def readfile(path):
with open(path, 'rb') as f:
content = f.read()
return hashlib.md5(content).hexdigest()
# 同步文件夹目录
def catalogueCompare(f_path_c, f_path_d):
f_list_c = []
f_list_d = []
f_list_c = read_dirs(f_path_c, f_list_c) # 调用函数
f_list_d = read_dirs(f_path_d, f_list_d) # 调用函数
setC = set(f_list_c)
setD = set(f_list_d)
commonfilesCD = setC & setD # 处理共有文件夹
# onlyFiles = setC ^ setD
onlyFilesC = setC ^ commonfilesCD # c中需要拷贝到d的文件夹
onlyFilesD = setD ^ commonfilesCD # d中需要删除的文件夹
disk_c = f_path_c[:2]
disk_d = f_path_d[:2]
for each_only_c in onlyFilesC:
each_only_c_real = disk_c+each_only_c
each_only_d_real = disk_d+each_only_c
copyfiles(each_only_c_real, each_only_d_real)
# print('拷贝文件成功: %s' % each_only_c_real)
for each_only_d in onlyFilesD:
each_only_d_real = disk_d + each_only_d
deletefiles(each_only_d_real)
print('删除文件成功: %s' % each_only_d_real)
common_list_c = []
common_list_d = []
for common in commonfilesCD:
common_list_c.append(disk_c + common)
common_list_d.append(disk_d + common)
return common_list_c, common_list_d
def is_file(f_path):
# 判断是否存在
judge_isfile = os.path.exists(f_path)
if judge_isfile:
pass
else:
try:
os.mkdir(f_path)
print('创建目录:%s' % f_path)
except Exception as E_is_file:
# print('Error E_is_file: %s' % E_is_file)
os.makedirs(f_path)
print('创建多层目录:%s' % f_path)
# 遍历函数
def read_dirs(f_path, f_list):
# 获取f_path路径下的所有文件及文件夹
paths = os.listdir(f_path)
# 判断
for f_name in paths:
com_path = f_path + "\\" + f_name
if os.path.isdir(com_path): # 如果是一个文件夹
# print(com_path)
# print(f_list)
f_list.append(com_path[2:])
f_list = read_dirs(com_path, f_list) # 递归调用
# if os.path.isfile: # 如果是一个文件
# try:
# suffix = com_path.split(".")[1] # suffix=后缀(获取文件的后缀)
# except Exception as e:
# continue # 对于没有后缀的文件省略跳过
return f_list
def copyfiles(src, dst):
try:
shutil.copytree(src, dst)
except OSError as e_copy: # python >2.5
# print("Error_e_cpoy: %s - %s." % (e_copy.filename, e_copy.strerror))
pass
def deletefiles(mydir):
try:
shutil.rmtree(mydir)
except OSError as e:
print("Error_e: %s - %s." % (e.filename, e.strerror))
def is_dir(path):
list_c = []
for lists in os.listdir(path):
sub_path = os.path.join(path, lists)
# print(sub_path)
if os.path.isfile(sub_path):
pass
elif os.path.isdir(sub_path):
list_c.append(sub_path)
return list_c
def quick_compare(f_path_c, f_path_d):
# 判断备份文件夹是否存在,不存在就创建
is_file(f_path_c)
is_file(f_path_d)
# 直接比较 两个二级目录是否大小一样,文件数量一样,文件夹数量一样。如果一样就跳过
gfc = GetFileSizeAndNum() # 获取目录大小 文件数量
gfd = GetFileSizeAndNum() # 获取目录大小 文件数量
totalSizeC, fileNumC, dirNumC, totalSizeConversionC = gfc.main_start(f_path_c)
totalSizeD, fileNumD, dirNumD, totalSizeConversionD = gfd.main_start(f_path_d)
return totalSizeC, fileNumC, dirNumC, totalSizeConversionC, totalSizeD, fileNumD, dirNumD, totalSizeConversionD
def for_one_in_common_list_c_sorted(common_list_c_sorted, common_list_d_sorted):
FolderEE_sorted = common_list_c_sorted[0]
FolderSVN_sorted = common_list_d_sorted[0]
print('NOT SAME -- %s' % FolderEE_sorted)
dirCompare(FolderEE_sorted, FolderSVN_sorted)
common_list_c_sorted.pop(0)
common_list_d_sorted.pop(0)
return common_list_c_sorted, common_list_d_sorted
def traversal_common_c(common_list_c, common_list_d):
# 遍历每个共同目录
common_list_in_C = []
common_list_in_D = []
for num_c, FolderEE in enumerate(common_list_c):
# if FolderEE != r'D:\00_Backup\00Programs1': # 用于调试,单独备份某个文件夹
# continue
FolderSVN = common_list_d[num_c]
totalSizeC, fileNumC, dirNumC, totalSizeConversionC, totalSizeD, fileNumD, dirNumD, totalSizeConversionD = quick_compare(FolderEE, FolderSVN)
if totalSizeC == totalSizeD and fileNumC == fileNumD and dirNumC == dirNumD:
continue
else:
# 获取每个文件夹目录下的文件总大小,不包含子文件夹
file_num_c, file_size_c = visitDir(FolderEE)
file_num_d, file_size_d = visitDir(FolderSVN)
if file_num_c == file_num_d and file_size_c == file_size_d:
print('SAME TOTAL FILES -- %s' % FolderEE)
else:
common_list_in_C.append(FolderEE)
common_list_in_D.append(FolderSVN)
return common_list_in_C, common_list_in_D
def visitDir(path):
totalSize = 0
fileNum = 0
for lists in os.listdir(path):
sub_path = os.path.join(path, lists)
# print(sub_path)
if os.path.isfile(sub_path):
fileNum = fileNum+1 # 统计文件数量
totalSize = totalSize+os.path.getsize(sub_path) # 文件总大小
elif os.path.isdir(sub_path):
# dirNum = dirNum+1 # 统计文件夹数量
# visitDir(sub_path) # 递归遍历子文件夹
pass
return fileNum, totalSize
def run(path):
# 先统一目录
list_c = is_dir(path)
for f_path_c in list_c: # 需要遍历的文件路径
# print('开始比较: %s' % f_path_c)
f_path_d = f_path_c.replace('D', 'F')
totalSizeC, fileNumC, dirNumC, totalSizeConversionC, totalSizeD, fileNumD, dirNumD, totalSizeConversionD = quick_compare(f_path_c, f_path_d)
if totalSizeC == totalSizeD and fileNumC == fileNumD and dirNumC == dirNumD:
print("SAME -- %s totalSizeC: %s, fileNumC: %s, dirNumC: %s" % (f_path_c, totalSizeConversionC, fileNumC, dirNumC))
continue
else:
print('开始同步: %s' % f_path_c)
common_list_c, common_list_d = catalogueCompare(f_path_c, f_path_d) # 调用函数 同步文件夹目录 返回共同目录
common_list_c.append(f_path_c) # 把根目录加进去,同步根目录下的文件
common_list_d.append(f_path_d)
# 相同文件夹过滤,返回子文件总和不同的文件夹list
common_list_c_processing, common_list_d_processing = traversal_common_c(common_list_c, common_list_d)
for num_c, FolderEE_sorted in enumerate(common_list_c_processing):
# if FolderEE != r'D:\00_Backup\00Programs1': # 用于调试,单独备份某个文件夹
# continue
FolderSVN_sorted = common_list_d_processing[num_c]
print('NOT SAME -- %s' % FolderEE_sorted)
dirCompare(FolderEE_sorted, FolderSVN_sorted)
if __name__ == '__main__':
print("Start Run!")
old_time = datetime.datetime.now()
print(old_time.strftime('%Y-%m-%d %H:%M:%S',))
path = r"D:\00_Backup"
run(path)
new_time = datetime.datetime.now()
print(new_time.strftime('%Y-%m-%d %H:%M:%S',))
time = (new_time - old_time).seconds
print(time, '秒')
print("Finish Run!")
# -*-coding:utf-8-*-
# ===============================================================================
# 目录对比工具(包含子目录 ),并列出
# 1、A比B多了哪些文件
# 2、B比A多了哪些文件
# 3、二者相同的文件:文件大小相同 VS 文件大小不同 (Size相同文件不打印:与Size不同文件显示未排序)
# ===============================================================================
import os, time, difflib
import shutil # shutil全称是shell utilities
import errno
AFILES = [] # EE
BFILES = [] # SVN
COMMON = [] # EE & SVN
def getPrettyTime(state):
return time.strftime('%y-%m-%d %H:%M:%S', time.localtime(state.st_mtime))
# def getpathsize(dir): #获取文件大小的函数,未用上,仅供学习.故注释掉
# size=0
# for root, dirs, files in os.walk(dir):
# #root:目录:str 如: C:\CopySVN\SystemObject\TopoProcedure\Built-in\
# #dirs:目录名称:列表: 如 ['Parsers']
# #files:名称:列表: 如 ['011D0961FB42416AA49D5E82945DE7E9.og',...]
# #file:目录:str, 如 011D0961FB42416AA49D5E82945DE7E9.og
# for file in files:
# path = os.path.join(root,file)
# size = os.path.getsize(path)
# return size
def dirCompare(apath, bpath):
afiles = []
bfiles = []
for root, dirs, files in os.walk(apath):
for f in files:
afiles.append(root + "\\" + f)
for root, dirs, files in os.walk(bpath):
for f in files:
bfiles.append(root + "\\" + f)
# sizeB = os.path.getsize(root + "\\" + f) 此处定义的size无法在commonfiles进行比较. (A,B在各自的循环里面)
# 去掉afiles中文件名的apath (拿A,B相同的路径\文件名,做成集合,去找交集)
apathlen = len(apath)
aafiles = []
for f in afiles:
aafiles.append(f[apathlen:])
# 去掉bfiles中文件名的bpath
bpathlen = len(bpath)
bbfiles = []
for f in bfiles:
bbfiles.append(f[bpathlen:])
afiles = aafiles
bfiles = bbfiles
setA = set(afiles)
setB = set(bfiles)
# print('%$%'+str(len(setA)))
# print('%%'+str(len(setB)))
commonfiles = setA & setB # 处理共有文件
print ("===============File with different size in '", apath, "' and '", bpath, "'===============")
# 将结果输出到本地
with open(os.getcwd()+'diff.txt','w') as di:
now_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
di.write("now_time:" + now_time + " "+"===============File with different size in '" + apath + "' and '" + bpath + "'===============")
for f in sorted(commonfiles):
sA = os.path.getsize(apath + "\\" + f)
sB = os.path.getsize(bpath + "\\" + f)
if sA == sB: # 共有文件的大小比较
# pass #print (f + "\t\t" + getPrettyTime(os.stat(apath + "\\" + f)) + "\t\t" + getPrettyTime(os.stat(bpath + "\\" + f)))
# TODO 以下代码是处理大小一致,但是内容可能不一致的情况,则把A的覆盖B的
# print("in sa=sb")
# print(os.getcwd())
saf = []
sbf = []
sAfile = open(apath + "\\" + f, encoding='utf-8')
iter_f = iter(sAfile)
for line in iter_f:
saf.append(line)
sAfile.close()
sBfile = open(bpath + "\\" + f, encoding='utf-8')
iter_fb = iter(sBfile)
for line in iter_fb:
sbf.append(line)
sBfile.close()
saf1 = sorted(saf)
sbf1 = sorted(sbf)
if (len(saf1) != len(sbf1)):
with open(os.getcwd() + '\\comment_diff.txt', 'a') as fp:
print(os.getcwd())
now_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
fp.write("now_time:" + now_time + " "+ apath + "\\" + f + " lines size not equal " + bpath + "\\" + f + '\n')
else:
for i in range(len(saf1)):
# print("into pre")
if (saf1[i] != sbf1[i]):
print('into commont')
with open(os.getcwd() + '\\comment_diff.txt', 'a') as fp1:
fp1.write("now_time:" + now_time + " "+apath + "\\" + f + " content not equal " + bpath + "\\" + f + '\n')
break
shutil.copyfile(apath + "\\" + f, bpath + "\\" + f)
# TODO 如果两个文件夹下的同名文件大小不同,则把A的覆盖B的
else:
with open(os.getcwd() + '\\diff.txt', 'a') as di:
di.write("now_time:" + now_time + " "+"File Name=%s EEresource file size:%d != SVN file size:%d" % (f, sA, sB) + '\n')
print ("File Name=%s EEresource file size:%d != SVN file size:%d" %(f,sA,sB))
shutil.copyfile(apath + "\\" + f, bpath + "\\" + f)
# TODO 处理仅出现在一个目录中的文件,A中多的拷贝到B,B中多的删除,与A同步
onlyFiles = setA ^ setB
aonlyFiles = []
bonlyFiles = []
for of in onlyFiles:
if of in afiles:
aonlyFiles.append(of)
elif of in bfiles:
bonlyFiles.append(of)
print ("###################### EE resource ONLY ###########################")
print ("#only files in ", apath)
for of in sorted(aonlyFiles):
with open(os.getcwd() + '\\EEonly.txt', 'a') as ee:
ee.write("now_time:" + now_time + " "+of + '\n')
print('add: %s' % of)
shutil.copyfile(apath + of, bpath + of)
print ("*"*20+"SVN ONLY+"+"*"*20)
print ("#only files in ", bpath)
for of in sorted(bonlyFiles):
with open(os.getcwd() + '\\svnonly.txt', 'a') as svn:
svn.write("now_time:" + now_time + " "+of + '\n')
print('delete: %s' % of)
os.remove(bpath + of)
# 同步文件夹目录
def catalogueCompare(f_path_c, f_path_d):
f_list_c = []
f_list_d = []
f_list_c = read_dirs(f_path_c, f_list_c) # 调用函数
f_list_d = read_dirs(f_path_d, f_list_d) # 调用函数
setC = set(f_list_c)
setD = set(f_list_d)
commonfilesCD = setC & setD # 处理共有文件夹
# onlyFiles = setC ^ setD
onlyFilesC = setC ^ commonfilesCD # c中需要拷贝到d的文件夹
onlyFilesD = setD ^ commonfilesCD # d中需要删除的文件夹
disk_c = f_path_c[:2]
disk_d = f_path_d[:2]
for each_only_c in onlyFilesC:
each_only_c_real = disk_c+each_only_c
each_only_d_real = disk_d+each_only_c
copyfiles(each_only_c_real, each_only_d_real)
print('拷贝文件成功: %s' % each_only_c_real)
for each_only_d in onlyFilesD:
each_only_d_real = disk_d + each_only_d
deletefiles(each_only_d_real)
print('删除文件成功: %s' % each_only_d_real)
common_list_c = []
common_list_d = []
for common in commonfilesCD:
common_list_c.append(disk_c + common)
common_list_d.append(disk_d + common)
return common_list_c, common_list_d
# 遍历函数
def read_dirs(f_path, f_list):
# 获取f_path路径下的所有文件及文件夹
paths = os.listdir(f_path)
# 判断
for f_name in paths:
com_path = f_path + "\\" + f_name
if os.path.isdir(com_path): # 如果是一个文件夹
print(com_path)
print(f_list)
f_list.append(com_path[2:])
f_list = read_dirs(com_path, f_list) # 递归调用
# if os.path.isfile: # 如果是一个文件
# try:
# suffix = com_path.split(".")[1] # suffix=后缀(获取文件的后缀)
# except Exception as e:
# continue # 对于没有后缀的文件省略跳过
return f_list
def copyfiles(src, dst):
try:
shutil.copytree(src, dst)
except OSError as e_delete: # python >2.5
print(e_delete)
if e_delete.errno == errno.ENOTDIR:
shutil.copy(src, dst)
else:
raise
def deletefiles(mydir):
try:
shutil.rmtree(mydir)
except OSError as e:
print("Error: %s - %s." % (e.filename, e.strerror))
if __name__ == '__main__':
print("Start!")
# 先统一目录
f_path_c = r"D:\00Shell" # 需要遍历的文件路径
f_path_d = r"E:\00Shell" # 需要遍历的文件路径
common_list_c, common_list_d = catalogueCompare(f_path_c, f_path_d) # 调用函数 同步文件夹目录 返回共同目录
# 遍历每个共同目录
for num_c, FolderEE in enumerate(common_list_c):
FolderSVN = common_list_d[num_c]
dirCompare(FolderEE, FolderSVN)
print("Finish!")
参考:
https://blog.csdn.net/ycy0706/article/details/119171209
https://www.cnblogs.com/luo-mao/p/5872532.html
https://www.10qianwan.com/articledetail/36451.html
108.os.path.getsize() 获取文件夹大小函数 获取文件大小 获取文件夹数量
方法一:
import os
def get_size(start_path = '.'):
total_size = 0
for dirpath, dirnames, filenames in os.walk(start_path):
for f in filenames:
fp = os.path.join(dirpath, f)
# skip if it is symbolic link
if not os.path.islink(fp):
total_size += os.path.getsize(fp)
return total_size
print(get_size('D:\\00Shell'), 'bytes')
print(get_size('D:\\1'), 'bytes')
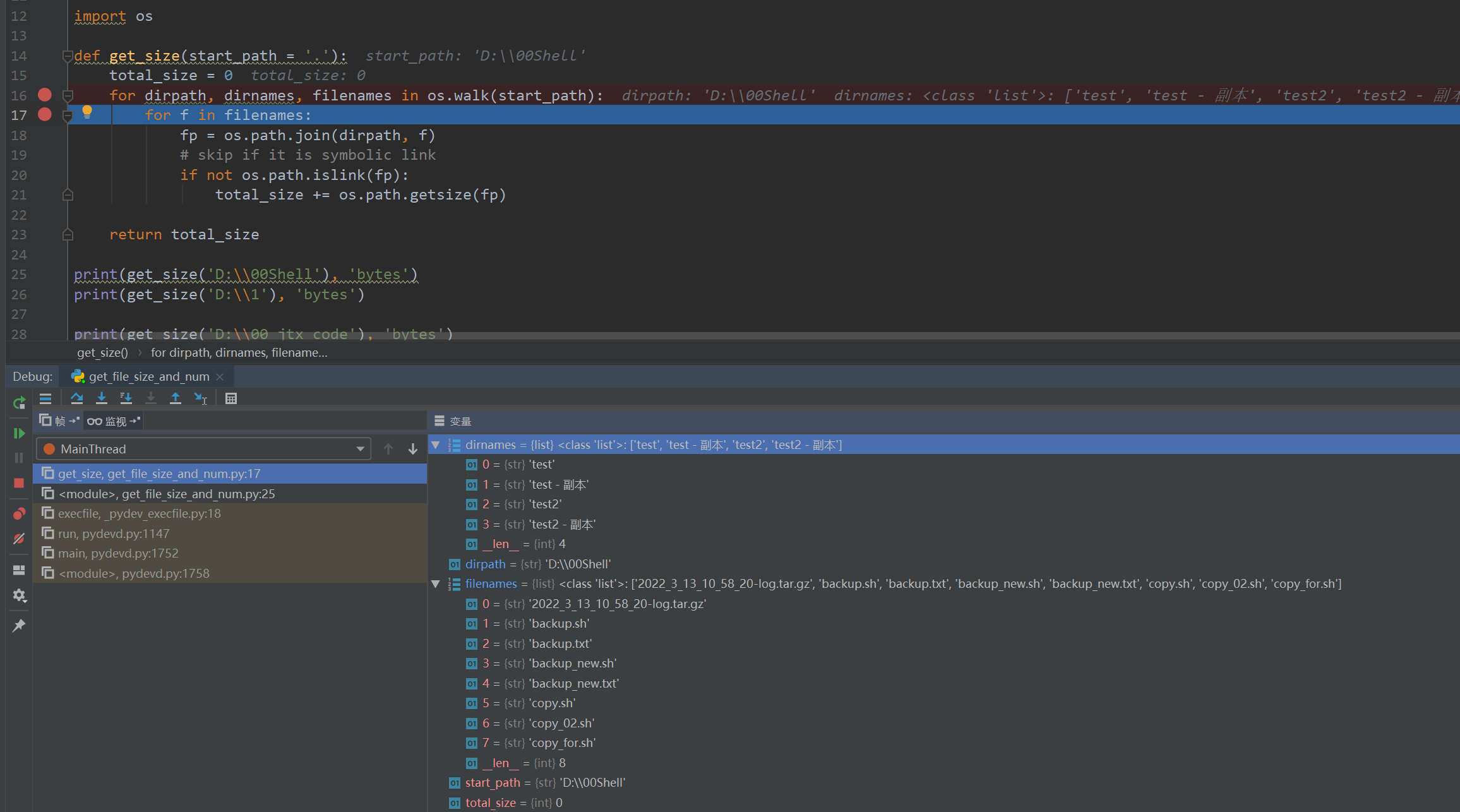
方法二:
import os
totalSize = 0
fileNum = 0
dirNum = 0
def visitDir(path):
global totalSize
global fileNum
global dirNum
for lists in os.listdir(path):
sub_path = os.path.join(path, lists)
print(sub_path)
if os.path.isfile(sub_path):
fileNum = fileNum+1 # 统计文件数量
totalSize = totalSize+os.path.getsize(sub_path) # 文件总大小
elif os.path.isdir(sub_path):
dirNum = dirNum+1 # 统计文件夹数量
visitDir(sub_path) # 递归遍历子文件夹
def sizeConvert(size, n): # 单位换算
K, M, G = 1024, 1024**2, 1024**3
if size >= G:
return str(round(size/G, n))+' G Bytes'
elif size >= M:
return str(round(size/M, n))+' M Bytes'
elif size >= K:
return str(round(size/K, n))+' K Bytes'
else:
return str(size)+' Bytes'
def main(path):
if not os.path.isdir(path):
print('Error:"', path, '" is not a directory or does not exist.')
return
visitDir(path)
def output(path):
print('The total size of '+path+' is:'+sizeConvert(totalSize, 2))
print('The total number of files in '+path+' is:',fileNum)
print('The total number of directories in '+path+' is:',dirNum)
if __name__ == '__main__':
path = r'D:\1'
main(path)
output(path)
109.datetime 计算时间差
https://blog.csdn.net/WBST5/article/details/109911035
(new_time - old_time).seconds
(new_time - old_time).days
from datetime import datetime
def calc_hours(old):
old_time = datetime.strptime(old, "%Y-%m-%d %H:%M:%S,%f")
new_time = datetime.now()
sec = (new_time - old_time).seconds
return round(sec/3600, 3)
t = '2020-11-19 15:04:47,397'
print(calc_hours(t))
# 计算结果
# old_time: 2020-11-19 15:04:47.397000
# new_time: 2020-11-21 22:48:12.076836
# 7.723
110.python 创建多级目录
# 多级目录
import os
path_dir = 'D:\\12'
if not os.path.exists(path_dir):
os.makedirs(path_dir)
# 单个目录
judge_isfile = os.path.exists(path_dir)
if judge_isfile:
pass
else:
os.mkdir(path_dir)
111.python 连续空格变成一个空格
rf_clean = re.sub(‘、+’, ‘、’, rf)
rf_clean = re.sub(‘ +’, ‘ ‘, rf)
112.pyautogui 模拟鼠标点击 模拟键盘
https://blog.csdn.net/weixin_42322206/article/details/117378726
安装
pip3 install pyautogui
PyAutoGUI是一个纯Python的GUI自动化工具,其目的是可以用程序自动控制鼠标和键盘操作,多平台支持(Windows,OS X,Linux)。
import os,time
import pyautogui as pag
from pymouse import PyMouse
from pykeyboard import PyKeyboard
try:
print("Press Ctrl-C to end")
x,y = pag.position() #返回鼠标的坐标
posStr="Position(x,y):"+str(x).rjust(4)+','+str(y).rjust(4)
print(posStr) #打印坐标
time.sleep(0.2)
os.system('cls') # 清楚屏幕
except Exception as e:
print ('end....%s' % e)
finally:
pass
_mouse = PyMouse()
k_board = PyKeyboard()
_mouse.click(500,500,1) # 移动并且在xy位置点击
time.sleep(1)
_mouse.click(300,400,1) # 移动并且在xy位置点击
time.sleep(1)
_mouse.click(1093,565,1) # 移动并且在xy位置点击
k_board.tap_key(k_board.function_keys[5]) # 点击功能键F5
pyautogui鼠标操作
import pyautogui
# 获取当前屏幕分辨率
screenWidth, screenHeight = pyautogui.size()
# 获取当前鼠标位置
currentMouseX, currentMouseY = pyautogui.position()
# 2秒钟鼠标移动坐标为100,100位置 绝对移动
#pyautogui.moveTo(100, 100, 2)
pyautogui.moveTo(x=100, y=100,duration=2, tween=pyautogui.linear)
#鼠标移到屏幕中央。
pyautogui.moveTo(screenWidth / 2, screenHeight / 2)
# 鼠标左击一次
pyautogui.click()
# x y
# clicks 点击次数
# interval点击之间的间隔
# button 'left', 'middle', 'right' 对应鼠标 左 中 右或者取值(1, 2, or 3)
# tween 渐变函数
#
pyautogui.click(x=None, y=None, clicks=1, interval=0.0, button='left', duration=0.0, tween=pyautogui.linear)
# 鼠标相对移动 ,向下移动
#pyautogui.moveRel(None, 10)
pyautogui.moveRel(xOffset=None, yOffset=10,duration=0.0, tween=pyautogui.linear)
# 鼠标当前位置0间隔双击
#pyautogui.doubleClick()
pyautogui.doubleClick(x=None, y=None, interval=0.0, button='left', duration=0.0, tween=pyautogui.linear)
# 鼠标当前位置3击
#pyautogui.tripleClick()
pyautogui.tripleClick(x=None, y=None, interval=0.0, button='left', duration=0.0, tween=pyautogui.linear)
#右击
pyautogui.rightClick()
#中击
pyautogui.middleClick()
# 用缓动/渐变函数让鼠标2秒后移动到(500,500)位置
# use tweening/easing function to move mouse over 2 seconds.
pyautogui.moveTo(x=500, y=500, duration=2, tween=pyautogui.easeInOutQuad)
#鼠标拖拽
pyautogui.dragTo(x=427, y=535, duration=3,button='left')
#鼠标相对拖拽
pyautogui.dragRel(xOffset=100,yOffset=100,duration=,button='left',mouseDownUp=False)
#鼠标移动到x=1796, y=778位置按下
pyautogui.mouseDown(x=1796, y=778, button='left')
#鼠标移动到x=2745, y=778位置松开(与mouseDown组合使用选中)
pyautogui.mouseUp(x=2745, y=778, button='left',duration=5)
#鼠标当前位置滚轮滚动
pyautogui.scroll()
#鼠标水平滚动(Linux)
pyautogui.hscroll()
#鼠标左右滚动(Linux)
pyautogui.vscroll()
# pyautogui键盘操作样例
#模拟输入信息
pyautogui.typewrite(message='Hello world!',interval=0.5)
#点击ESC
pyautogui.press('esc')
# 按住shift键
pyautogui.keyDown('shift')
# 放开shift键
pyautogui.keyUp('shift')
# 模拟组合热键
pyautogui.hotkey('ctrl', 'c')
提示信息
alert
#pyautogui.alert('This is an alert box.','Test')
pyautogui.alert(text='This is an alert box.', title='Test')
prompt
a = pyautogui.prompt('input message')
print(a)
截屏
整个屏幕截图并保存
im1 = pyautogui.screenshot()
im1.save('my_screenshot.png')
im2 = pyautogui.screenshot('my_screenshot2.png')
屏幕查找图片位置并获取中间点
#在当前屏幕中查找指定图片(图片需要由系统截图功能截取的图)
coords = pyautogui.locateOnScreen('folder.png')
#获取定位到的图中间点坐标
x,y=pyautogui.center(coords)
#右击该坐标点
pyautogui.rightClick(x,y)
安全设置
import pyautogui
#保护措施,避免失控
pyautogui.FAILSAFE = True
#为所有的PyAutoGUI函数增加延迟。默认延迟时间是0.1秒。
pyautogui.PAUSE = 0.5
Math 数学基础
1.时间衰减函数
时间近的相关度和权重大,随着时间的增加相关度减少
2.高斯函数
先缓慢后快后缓慢
3.激活函数
4.线性回归 linear regression
性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w’x+e,e为误差服从均值为0的正态分布
5.准确率和召回率
两个最常见的衡量指标是“准确率(precision)”(你给出的结果有多少是正确的)和“召回率(recall)”(正确的结果有多少被你给出了)
6.西格玛 ∑
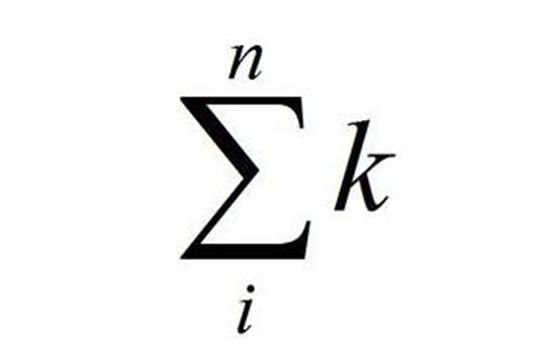
∑(i=1,n=5)k=1+2+3+4+5=15
7.梯度下降 Gradient Descent
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。


步长要合理
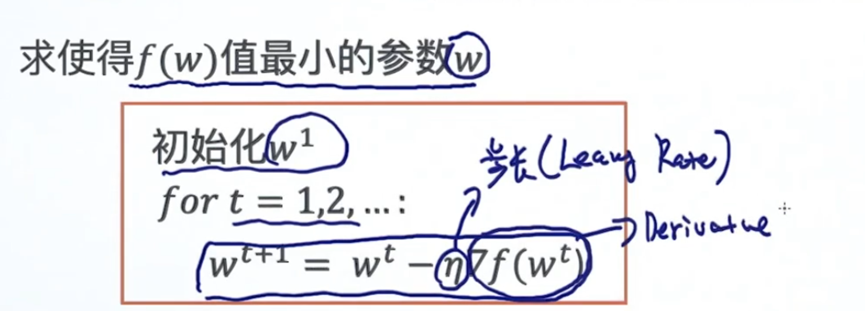




Java 基础操作
1.Java 基础语法
https://www.runoob.com/java/java-basic-syntax.html

public class HelloWorld {
/* 第一个Java程序
* 它将输出字符串 Hello World
*/
public static void main(String[] args) {
System.out.println("Hello World"); // 输出 Hello World
}
}
2.Java 数据类型
https://www.cnblogs.com/schiller-hu/p/10662429.html
①:基本数据类型:byte、short、int、long、float、double、char、boolean
②:引用数据类型: 数组、类、接口。
级别从低到高为:byte,char,short(这三个平级)——>int——>float——>long——>double
自动类型转换:从低级别到高级别,系统自动转的;
强制类型转换:什么情况下使用?把一个高级别的数赋给一个别该数的级别低的变量;
3.Java 函数
java中的函数的定义格式:
修饰符 返回值类型 函数名(参数类型 形式参数1,参数类型 形式参数1,…){
执行语句;
return 返回值;
}
4.java c 编译java文件编程class 文件
原理 https://www.cnblogs.com/pengx/p/10330455.html
实现:
5.java printf 和 printIn的区别
https://www.cnblogs.com/jiangsheng3/p/4949887.html


6.Java字符串数组:String[ ] string[]和List区别
string[]数组里面是存放string型的值,List<string>是存放string类型的对象
数组的容量是固定的,您只能一次获取或设置一个元素的值,而List<T>的容量可根据需要自动扩充、修改、删除或插入数据。
数组可以具有多个维度,而 List< T> 始终只具有一个维度。但是,您可以轻松创建数组列表或列表的列表。特定类型(Object 除外)的数组 的性能优于List的性能。 这是因为 List的元素属于 Object 类型;所以在存储或检索值类型时通常发生装箱和取消装箱操作。不过,在不需要重新分配时(即最初的容量十分接近列表的最大容量),List< T> 的性能与同类型的数组十分相近。
string 就是String...
string[]是 数组,定长,不可变
List<string> 是泛型 ,非定长,可变
7.Java 去除重复数据
public class quchongfu {
/**
* 去掉重复值
*/
public static void main(String[] args) {
String test = "100,120,166,1555,120,150,100";
String[] test1 = test.split(",");
List list = Arrays.asList(test1);
Set set = new HashSet(list);
String [] rid=(String [])set.toArray(new String[0]);
for (int i = 0; i < rid.length; i++) {
System.out.println(rid[i]);
}
}
8.Java hashset 去重复
Set<String> social_work = new HashSet<String>();
遍历set
for (String str : social_work) {
}
9.Java &&和||
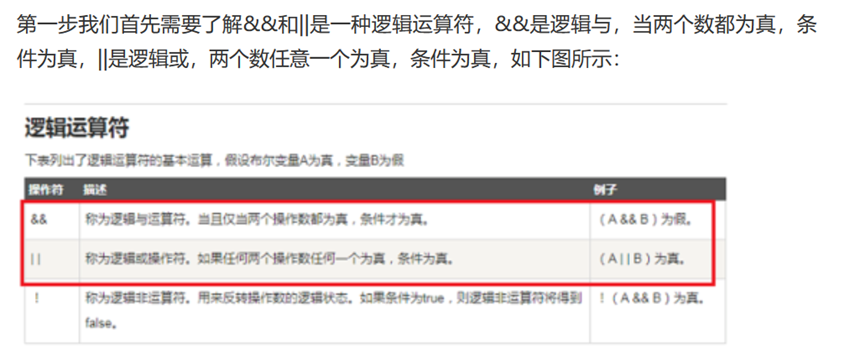
10.Java 判断是否为空值
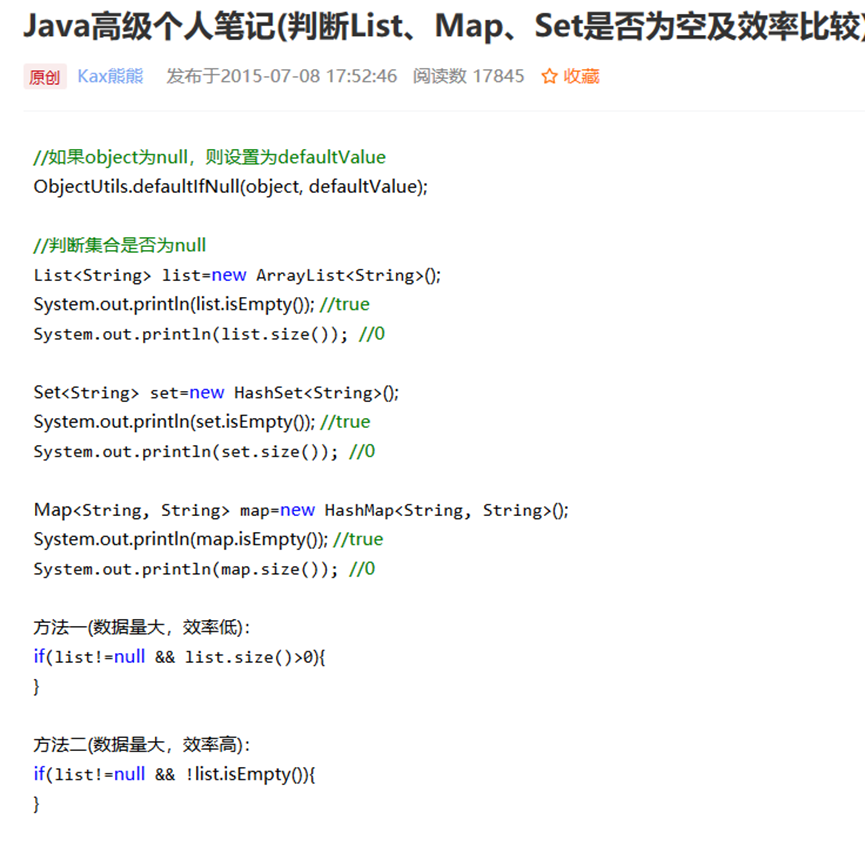
11.Java对象和类

12.创建项目,创建project
maven加载的jar包 pom配置
15.Java题目
i++和++i
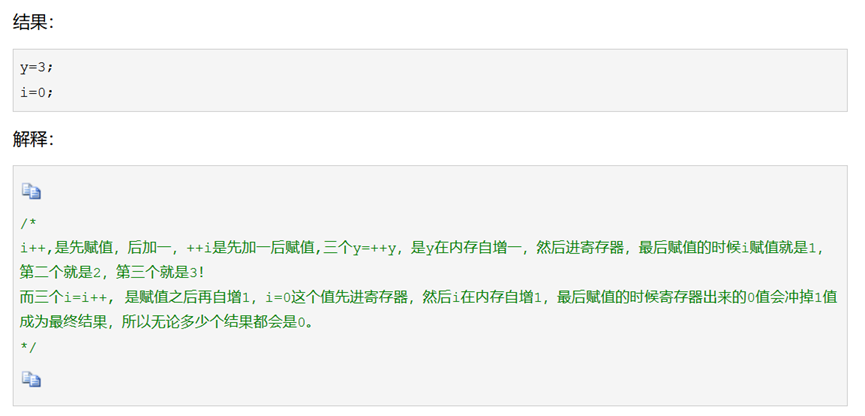
C++ 基础操作
1.基本语法
1.1 for循环
for (表达式1;表达式2;表达式3) {
// 循环体语句
}
#include <iostream>
using namespace std;
int main ()
{
// for 循环执行
for( int a = 10; a < 20; a = a + 1 )
{
cout << "a 的值:" << a << endl;
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
a 的值: 10
a 的值: 11
a 的值: 12
a 的值: 13
a 的值: 14
a 的值: 15
a 的值: 16
a 的值: 17
a 的值: 18
a 的值: 19
Golang 语言应用场景
• 服务器编程,以前你如果使用C或者C++做的那些事情,用Go来做很合适,例如处理日志、数据打包、虚拟机处理、文件系统等。
• 分布式系统,数据库代理器等
• 网络编程,这一块目前应用最广,包括Web应用、API应用、下载应用、
• 内存数据库,前一段时间google开发的groupcache,couchbase的部分组建
• 云平台,目前国外很多云平台在采用Go开发,CloudFoundy的部分组建,前VMare的技术总监自己出来搞的apcera云平台。
JavaScript 语言
1.js 语法
2.网页js源码
3.js前端加密代码解析 中国会展网
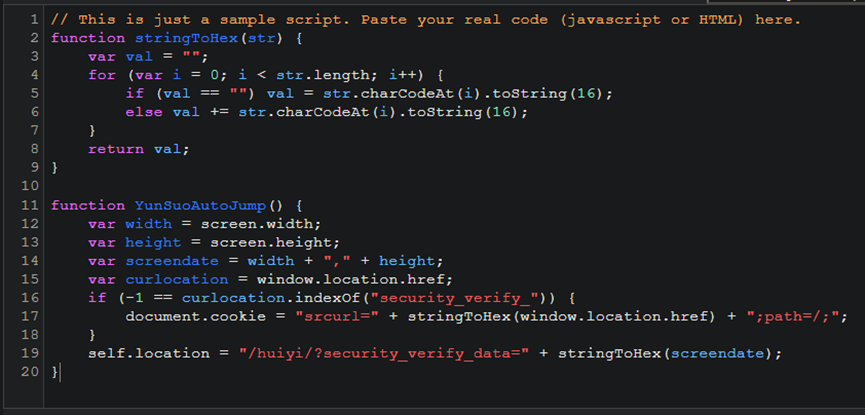
Stringtohex 是将字符串变成16进制
Window.location.href是当前网页的网址url

修改前:

修改后:

Var--------js语法
声明(创建) JavaScript 变量 在 JavaScript 中创建变量经常被称为“声明”变量。您可以通过 var 语句来声明 JavaScript 变量:var x; var carname; 在以上声明之后,变量并没有值,不过您可以在声明它们时向变量赋值:var x=5; var carname="Volvo"; 注释:在为变量赋文本值时,请为该值加引号。
console.log(message)--------js语法
console.log() 方法用于在控制台输出信息。
该方法对于开发过程进行测试很有帮助。
然后执行 控制台执行 YunSuoAutoJump() 函数 得到313038382c363132
按照js代码请求拼接网址
http://www.cnena.com/huiyi/?security_verify_data=313038382c363132
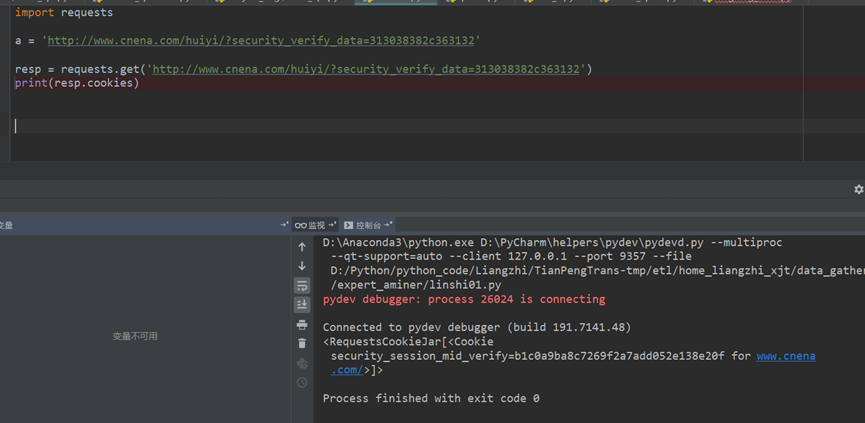
得到新的response的cookie用于中国会展网的请求
Matlab 基础操作
1.Matlab 语法
MATLAB 是一种解释型的环境。也就是说,只要你给MATLAB一个命令,它就会马上开始执行。
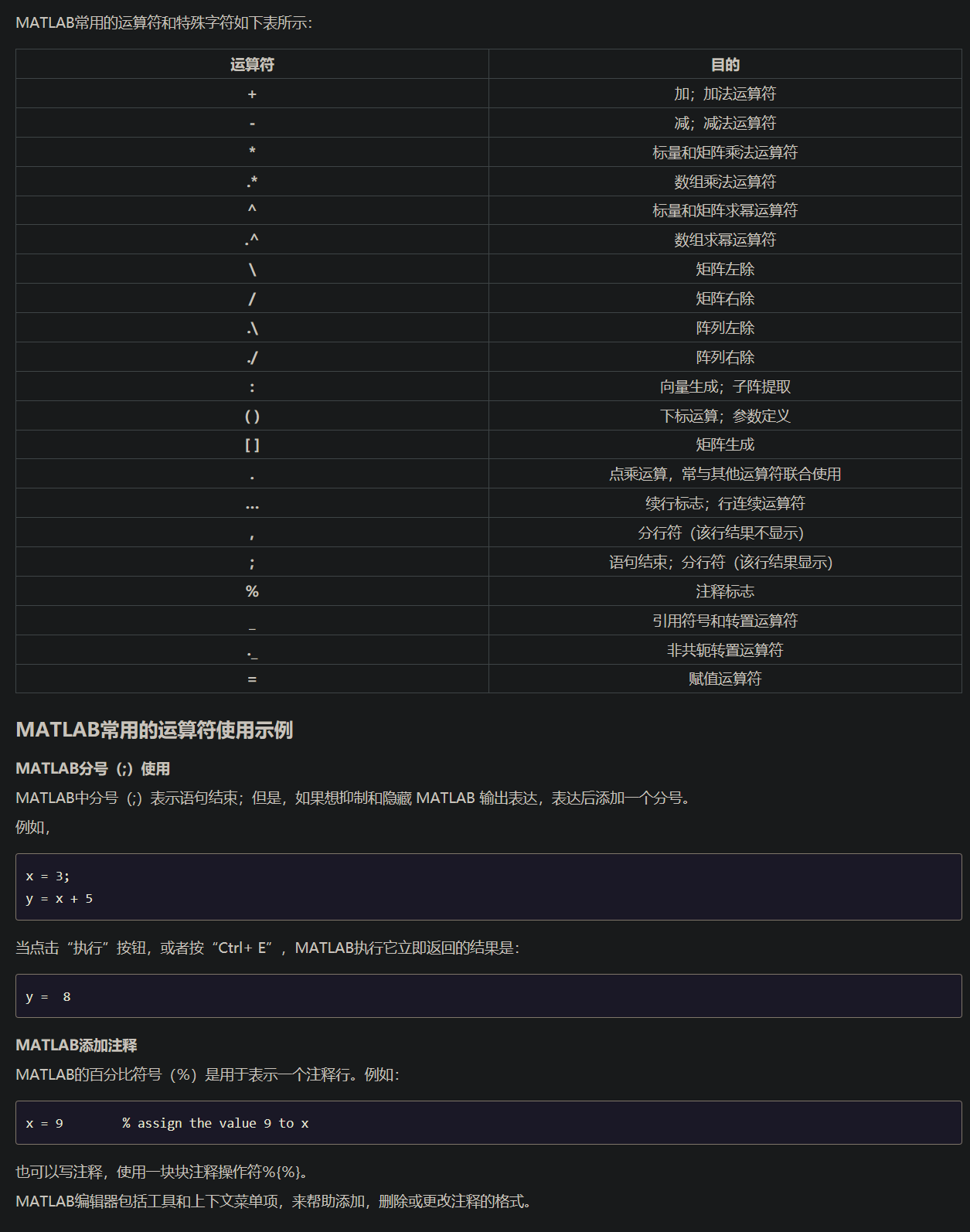
R语言 基础操作
MySQL 数据库
1.python mysql 创建表
'''创建数据库'''
import pymysql
#打开数据库连接,不需要指定数据库,因为需要创建数据库
conn = pymysql.connect('localhost',user = "root",passwd = "123456")
#获取游标
cursor=conn.cursor()
#创建pythonBD数据库
cursor.execute('CREATE DATABASE IF NOT EXISTS pythonDB DEFAULT CHARSET utf8 COLLATE utf8_general_ci;')
cursor.close()#先关闭游标
conn.close()#再关闭数据库连接
print('创建pythonBD数据库成功')
2.python mysql 插入数据
'''插入单条数据'''
import pymysql
#打开数据库连接,不指定数据库
conn=pymysql.connect('localhost','root','123456')
conn.select_db('pythondb')
cur=conn.cursor()#获取游标
#创建user表
cur.execute('drop table if exists user')
sql="""CREATE TABLE IF NOT EXISTS `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=0"""
cur.execute(sql)
insert=cur.execute("insert into user values(1,'tom',18)")
print('添加语句受影响的行数:',insert)
#另一种插入数据的方式,通过字符串传入值
sql="insert into user values(%s,%s,%s)"
cur.execute(sql,(3,'kongsh',20))
cur.close()
conn.commit()
conn.close()
print('sql执行成功')
3.mysql 查询数据
'''fetchone'''
import pymysql
#打开数据库连接
conn=pymysql.connect('localhost','root','123456')
conn.select_db('pythondb')
#获取游标
cur=conn.cursor()
cur.execute("select * from user;")
while 1:
res=cur.fetchone()
if res is None:
#表示已经取完结果集
break
print (res)
cur.close()
conn.commit()
conn.close()
print('sql执行成功')
4.mysql 更新数据
'''更新多条数据'''
import pymysql
#打开数据库连接
conn=pymysql.connect('localhost','root','123456')
conn.select_db('pythondb')
#获取游标
cur=conn.cursor()
#更新前查询所有数据
cur.execute("select * from user where name in ('kongsh','wen');")
print('更新前的数据为:')
for res in cur.fetchall():
print (res)
print ('*'*40)
#更新2条数据
sql="update user set age=%s where name=%s"
update=cur.executemany(sql,[(15,'kongsh'),(18,'wen')])
#更新2条数据后查询所有数据
cur.execute("select * from user where name in ('kongsh','wen');")
print('更新后的数据为:')
for res in cur.fetchall():
print (res)
cur.close()
conn.commit()
conn.close()
print('sql执行成功')
5.MySQL安装教程
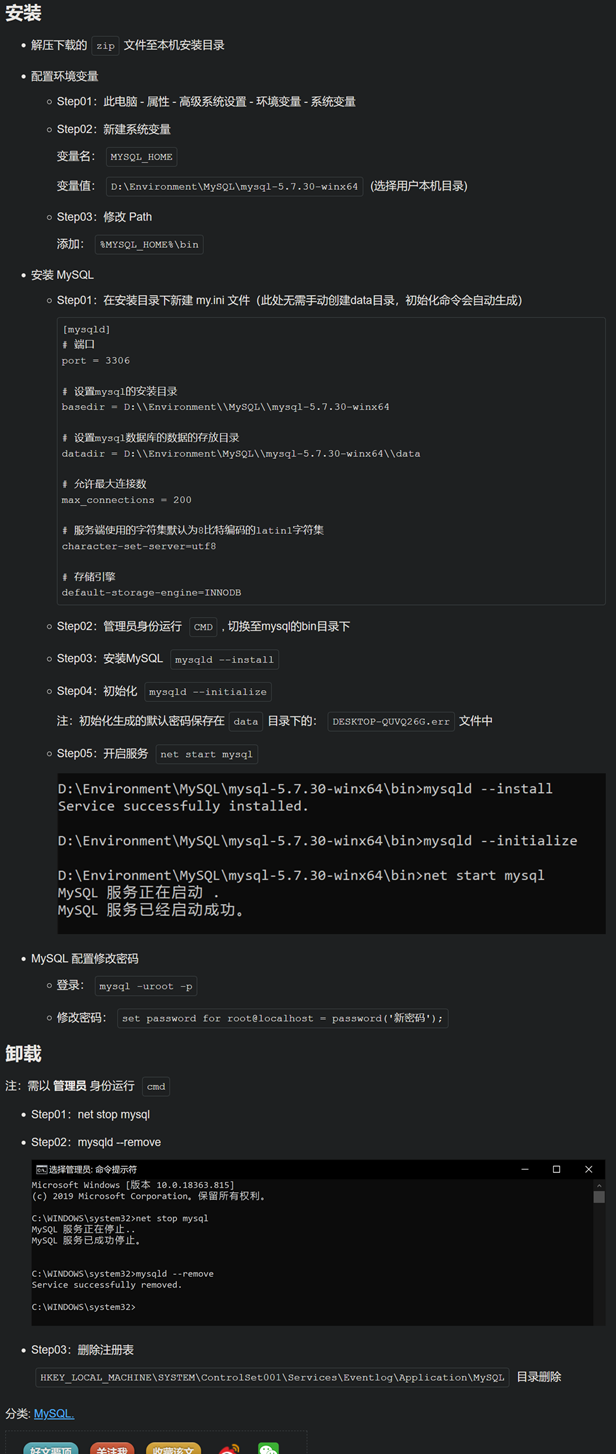
6.mysql 可视化工具安装
https://www.jianshu.com/p/4113cd5ef139
ElasticSearch 数据库
1.ES基本命令
1.es集群搜索
2.拆分索引(几十个)
3.自定义分词
2.ES弹性搜索
https://blog.csdn.net/qq_29718979/article/details/91356420
弹性搜索基本概念
Elasticsearch是一个基于Apache Lucene的搜索服务器。它由Shay Banon开发,于2010年发布。现在由Elasticsearch BV维护。其最新版本为2.1.0。
Elasticsearch是一个实时的分布式和开源的全文搜索和分析引擎。它可以从RESTful Web服务界面访问,并使用模式较少的JSON(JavaScript对象符号)文档来存储数据。它基于Java编程语言,它使Elasticsearch能够在不同的平台上运行。它使用户能够以非常高的速度探索非常大量的数据。
弹性搜索 - 一般特征
弹性搜索的一般特点如下 -
• Elasticsearch可扩展到高达PB级的结构化和非结构化数据。
• Elasticsearch可以用来替代诸如MongoDB和RavenDB之类的文档存储。
• Elasticsearch使用非规范化来提高搜索性能。
• Elasticsearch是受欢迎的企业搜索引擎之一,目前被许多大型组织(如维基百科,The Guardian,StackOverflow,GitHub等)使用。
• Elasticsearch是开源的,可以在Apache许可证版本2.0下使用。
弹性搜索 - 关键概念
弹性搜索的关键概念如下 -
• 节点 - 它指的是单个运行的Elasticsearch实例。单个物理和虚拟服务器可以根据物理资源的能力(如RAM,存储和处理能力)来容纳多个节点。
• 集群 - 它是一个或多个节点的集合。群集为整个数据提供了跨所有节点的集体索引和搜索功能。
• 索引 - 它是不同类型的文档和文档属性的集合。索引还使用分片的概念来提高性能。例如,一组文档包含社交网络应用程序的数据。
• 类型/映射 - 它是共享一组在同一索引中的公共字段的文档的集合。例如,索引包含社交网络应用的数据,然后可以具有用于用户简档数据的特定类型,消息数据的另一种类型,以及用于注释数据的另一种类型。
• 文档 - 它是以JSON格式定义的特定方式的字段集合。每个文档都属于一个类型,并且位于索引中。每个文档都与唯一的标识符相关联,称为UID。
• 碎片 - 索引水平细分为碎片。这意味着每个分片都包含文档的所有属性,但包含比索引少的JSON对象数。水平分离使碎片成为独立节点,可以存储在任何节点中。主碎片是索引的原始水平部分,然后将这些主分片复制到复本分片中。
• 复制 - 弹性搜索允许用户创建其索引和碎片的副本。复制不仅有助于在发生故障时增加数据的可用性,而且还可以通过在这些副本中执行并行搜索操作来提高搜索的性能。
弹性搜索 - 优点
• Elasticsearch是在Java上开发的,它几乎可以在每个平台上兼容。
• 弹性搜索是实时的,换句话说,一秒钟后,可以在此引擎中搜索添加的文档。
• 弹性搜索是分布式的,它可以轻松地扩展和集成到任何大型组织中。
• 通过使用Elasticsearch中存在的网关概念,创建完整备份非常简单。
• 与Apache Solr相比,Elasticsearch处理多租户很容易。
• Elasticsearch使用JSON对象作为响应,这使得可以使用大量不同的编程语言来调用Elasticsearch服务器。
• Elasticsearch支持几乎所有文档类型,但不支持文本呈现的文档类型。
弹性搜索 - 缺点
• Elasticsearch在处理请求和响应数据方面没有多语言支持(只能在JSON中使用),与Apache Solr不同,可以使用CSV,XML和JSON格式。
• 弹性搜索也有分裂大脑情况的问题,但在极少数情况下。
弹性搜索和RDBMS之间的比较
在Elasticsearch中,索引是类型的集合,就像数据库是RDBMS(关系数据库管理系统)中的表的集合一样。每个表都是一组行,就像每个映射都是JSON对象Elasticsearch的集合一样。
Elasticsearch RDBMS
指数 数据库
碎片 碎片
制图 表
范围 范围
JSON对象 元组
3.es head 插件查询
{"query":{"match":{"industrys.name":"人工智能"}}}
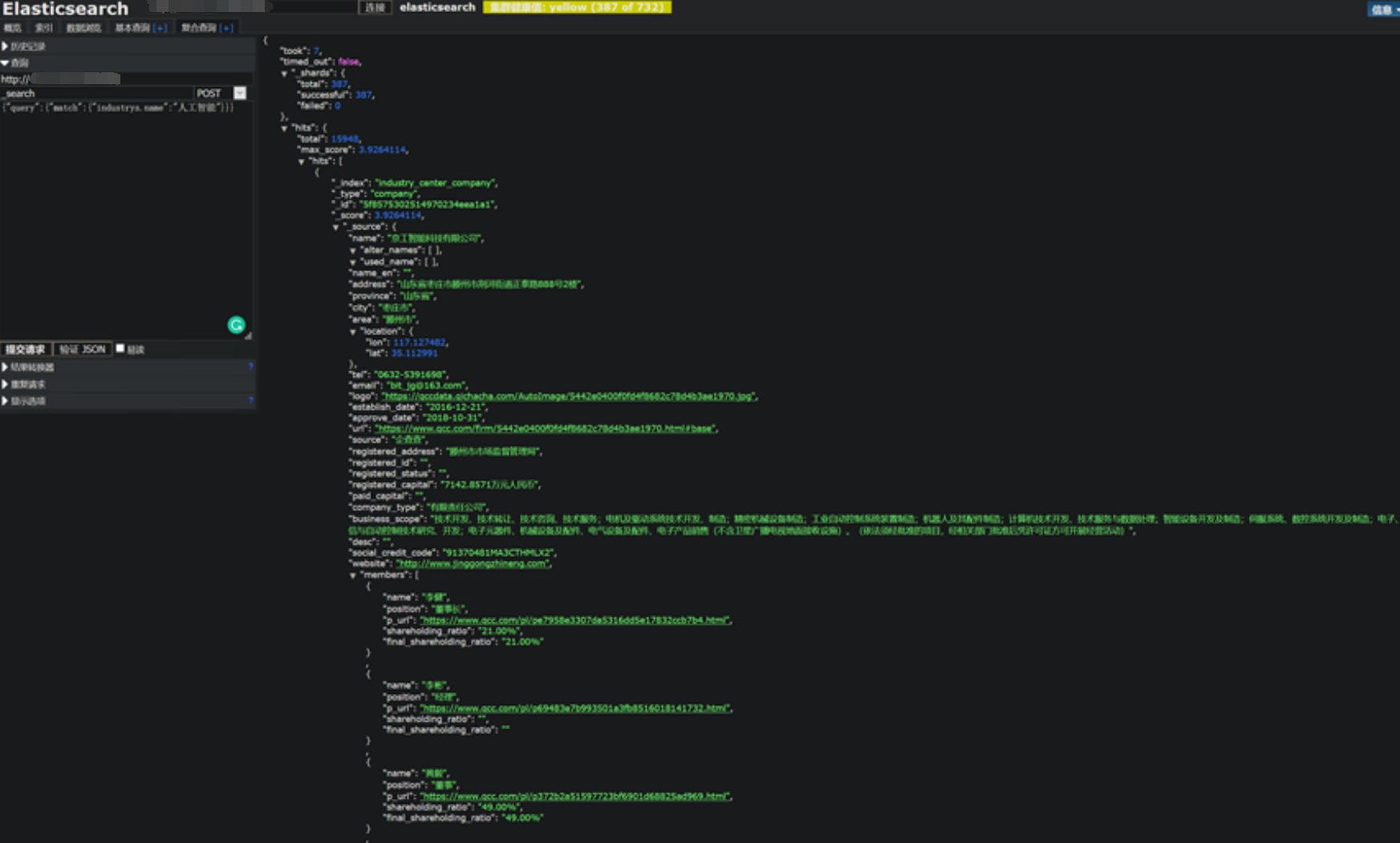
4.python ES 基础操作
https://www.cnblogs.com/siye1989/p/11561972.html
https://www.cnblogs.com/oklizz/p/11448389.html
https://cloud.tencent.com/developer/news/259683
代码:
from elasticsearch import Elasticsearch
# elasticsearch集群服务器的地址
ES = [
'xxx'
]
# 创建elasticsearch客户端
es = Elasticsearch(
ES
# 启动前嗅探es集群服务器
#sniff_on_start=True,
# es集群服务器结点连接异常时是否刷新es节点信息
#sniff_on_connection_fail=True
# 每60秒刷新节点信息
#sniffer_timeout=60
)
print(es)
# ret = es.search(index='industry_center_company')
# print(ret)
res = es.get(index='industry_center_company', doc_type='company', id='5f853bac2514970234ee9a46')
print(res)
5.ES修改最大翻页数 industry_center_company/_settings
put是修改 get是查看
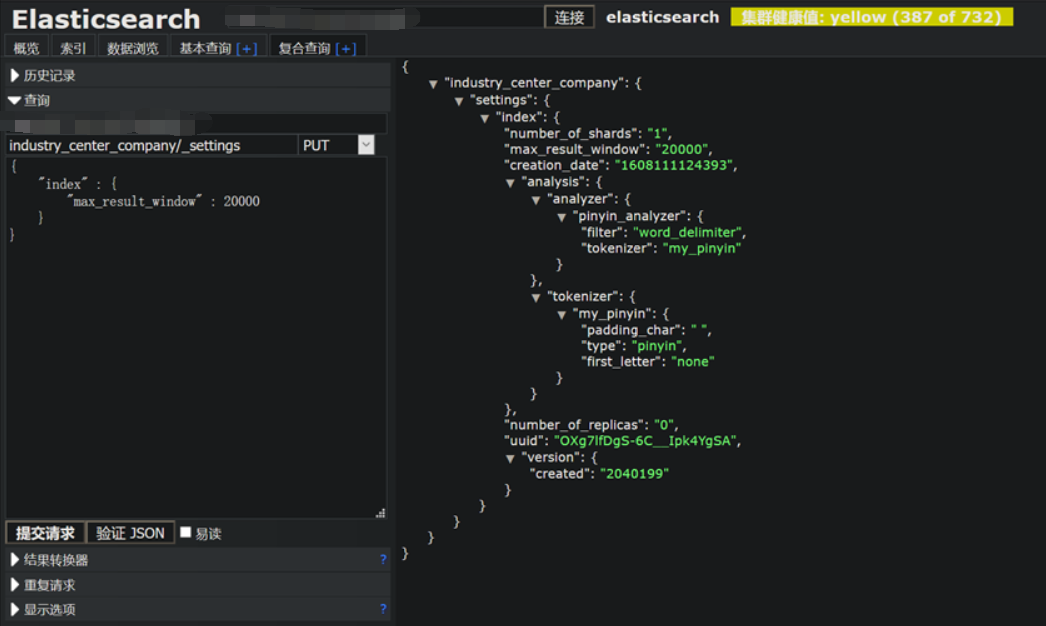
ArangoDb
1.本地安装 测试
https://www.cnblogs.com/minglex/p/9399866.html
本地运行需要先运行arangod.exe,作为服务运行
如果在Windows下将ArangoDB安装为服务,则会自动启动服务器。否则,需要以管理员身份运行运行安装文件夹bin目录中的arangod.exe位于位置。
默认安装包含一个数据库_system和一个名为root的用户
基于Debian的软件包和Windows安装程序将在安装过程中要求输入密码。
基于Red-Hat的软件包将设置随机密码。
对于其他安装包,需要运行以下命令设置root密码
定位到bin目录下,cmd,输入 arango-secure-installation
2.python连接 arangodb
https://www.cnblogs.com/minglex/p/9480516.html
from pyArango.connection import *
conn = Connection(arangoURL="http://xxxxxxxxxx", username="xxxxxx", password="xxxxxxx")
db = conn["xxxx"]
print(db)
3.ArangoDB 一个简单的 AQL 实现三级复杂关联检索
https://www.oschina.net/question/12_2268028
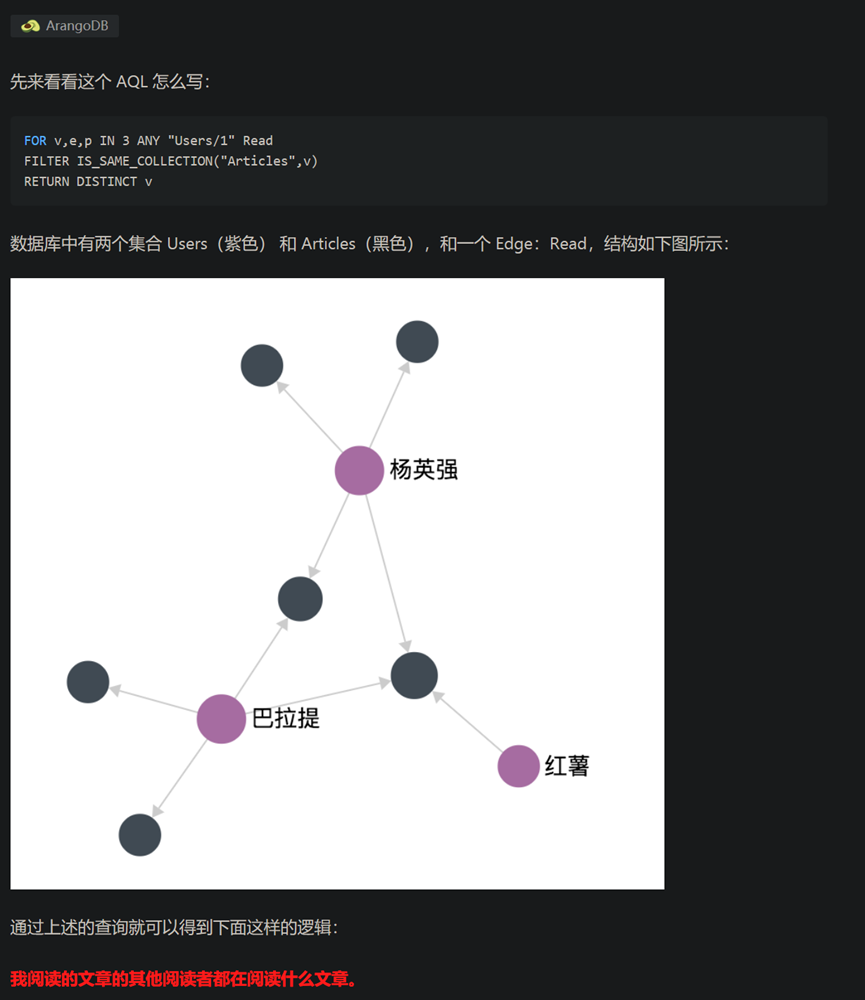
HBase
图数据库及应用场景
https://zhuanlan.zhihu.com/p/46895128

Azkaban
FireFox 插件
1.键盘代替鼠标插件 vimiun
j:向下滚动一点
k:向上滚动一点
gg:到页面最底部
G:到页面最底部
d:向下翻一屏
u:向上翻一屏
H:后退
L: 前进
x:关闭当前页面
X:恢复刚刚关闭的页面
Notepad++ 插件
https://www.cnblogs.com/Kubility123/p/5709116.html
https://www.jianshu.com/p/6d7fb99c71dc
插件
安装方法
把插件(.dll文件)放到notepad++/plugins目录里,重启Notepad++后,即可提示安装,安装成功后,在菜单栏的插件里能找到。
需要注意的是,Notepad的ANSI版和Unicode版本,有的插件只支持其中某个版本。
notepad++ 版本用32位, 不然插件安装会很麻烦
说明
具体插件的使用待整理, 也可自行百度
TextFX
超级插件: 删除空行, 增加行号, 删除首字, xml格式化, 大小写转换, html元素去除, 转换.....
JSON Viewer
使用这个可以快速将json格式化,快捷键是Ctrl+Alt+Shift+M。使用Ctrl+Alt+Shift+J可以展示JSON结构
Light Explorer
可以在左侧展示文件管理器。打开文件很方便
XBracket Lite
对于一些括号类的字符,比如单引号',双引号",圆括号(,大括号{,反括号[等,自动帮你实现自动补全
NppAstyle
支持c、c++、c#和java,可以将代码按照几种格式化
Function List
用于显示出函数的列表。支持很多种语言,包括C, C++, Resource File, Java, Assembler, MS INI File, HTML,
Javascript, PHP, ASP, Pascal, Python, Perl, Objective C, LUA, Fortran, NSIS, VHDL, SQL, VB and BATCH
AutoSave
自动保存
CCompletion
代码自动完成
code alignment
代码自动对齐
Doc Updater
每三秒自动更新你Notepad++中打开的文档。
QuickText
一个非常出色的代码片段管理器,支持Notepad++所支持的所有语言类型。
SearchInFiles
一个友好的Notepad++文件搜索工具。
NppExec
使用NppExec插件,你可以不需要离开Notepad++即可执行你的命令行或保存脚本,大大提高你的效率。
Spell-checker
拼写检查工具. 需要先安装Aspell。
Compare Plugin
一个非常实用的工具,可以用来比较两个文件不同之处.
FTP_synchronize
一个集成于Notepad++的FTP客户端。
NppFtp
FTP客户端
MultiClipboard
Notepad的剪贴板功能增强插件。
jsTool
查看js结构, 格式化js
Gmod 10 Lua Syntax Highlighter
Notepad++的一个语法高亮插件。
Task List
自动扫描当前文档,将所有"TODO:"开头的注释都找出来,列在右边的面板中,双击可以跳转该行
JSLint
JSLint一个Java语法检查工具,可以检查你的代码是否优秀
RegEx Helper
在文档的中匹配正则表达式,可以用来测试正则表达式
File Switcher
一个快速切换窗口的工具,支持通过输入文件名,路径或者tab index来查找切换,可以用来替换默认的Ctrl + Tab
TagsView
档的Class, 属性, 方法列表。比另一个叫做FunctionList的插件更好用
NppAutoIndent
自动缩进
Translate
翻译工具
Colour Picker
拾色器
SecurePad
加密工具
HTMLTag
Simple script
其他插件
XML Tools
这个插件是包含了很多XML编辑方面的实用工具。比如XML语法规则检查,XML Schema和DTD确认,XML标签自动关闭,当前XML路径,XML和Text转换,注释和非注释切换等等。
Insertion
这是一个主要用于演示的插件,适合初次开发者用于实例学习。它的功能是插入当前文档的名称和日期时间,以及自动关闭HTML/XML标签。
SpeechPlugin
文本转语音朗诵插件。
DBGP plugin
你可以使用这个插件把你的 Notepad++ 变成一个php IDE.
Log plugin
这个插件可以让Notepad++实现Windows内置记本事的一个功能 : 当文件为.log,每次打开后可以附加日期和时间。
Zen Coding
一个神器,前端开发神器,特有一套简易Coding规则,让书写Html和CSS的前端开发人员爱不释手
Tidy2
将HTML文件格式化为工整的缩进格式,特别好用
JSMinNpp
可以将js代码压缩,可以将js代码格式化,JSON代码查看器
NppExport
导出已着色代码为其他格式,将彩色代码,导出为RTF或者HTML格式的文件
Converter
可以方便的在ASCAII和HEX之间进行转换
MIME Tools
文件编码转换的工具
ConyEdit
跨编辑器的文本编辑器插件,在Notepad++上也可以用,数据提取(特别是列提取),代码重复生成,非常实用
Combine
将 Notepad++ 当前打开的全部文档合并到一个新的文档中
Python Script
Python Script 将 IDLE(Python 2.7)集成到 Notepad++。3.x需要离线安装
插件列表
以下博客有超多: https://blog.csdn.net/moqiang02/article/details/84607349
flask框架和django框架 写接口
1.Flask 介绍
Flask是一个使用 Python 编写的轻量级 Web 应用框架。
https://segmentfault.com/a/1190000017330435?utm_source=tag-newest
例子:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ =="__main__":
app.run(debug=True,port=8080)
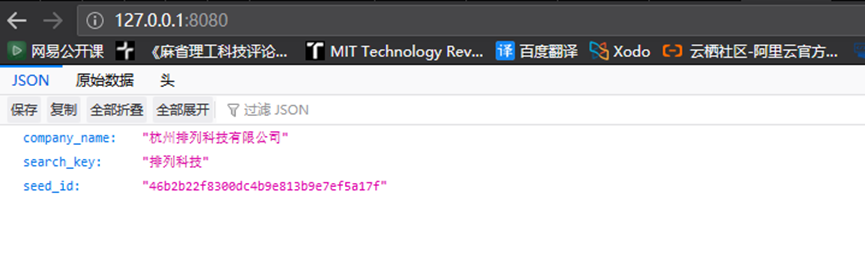
传入参数:
# 创建一个flask对象,名字随意但一定要和下面的app对应
app = Flask(__name__)
# request
@app.route('/getfullname', methods=['GET', 'POST'])
def get_search_result():
"""
根据关键词从查询接口中获取需要采集的数据详情链接和必要的数据,类似资讯采集中的parse_list方法处理列表页
默认获取第一条结果认为是查询匹配的结果
:param keyword:
:return:
"""
params = request.args.to_dict()
keyword = params['keyword']
# 执行py文件时,运行flask对象
if __name__ == '__main__':
app.run(debug=True,port=8080)
通过浏览器url访问:
127.0.0.1:8080/getfullname?keyword=排列科技
结果:
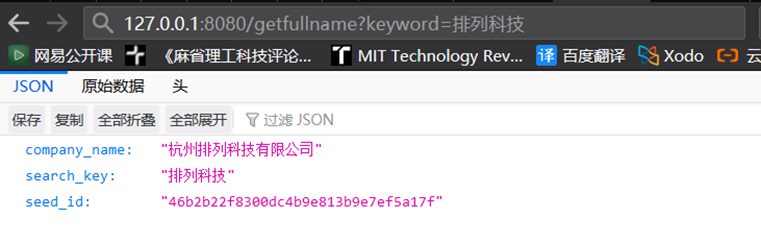
2.Flask 百度企业名称全称 简称转换接口
调用包:

传入参数:<string:str>
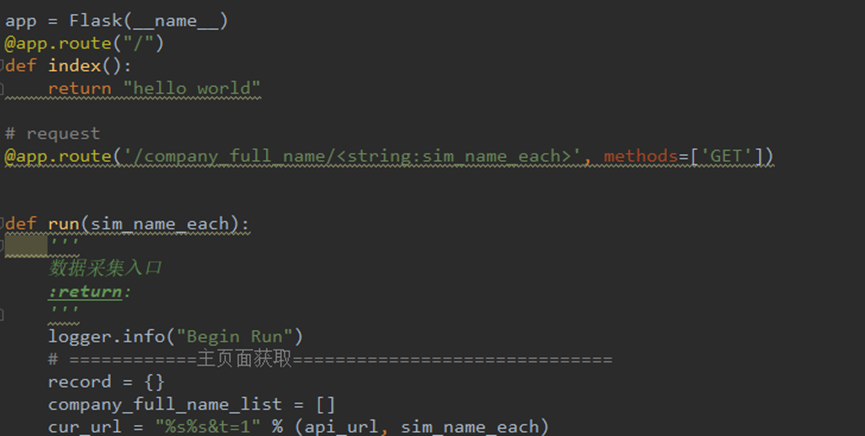
main函数:
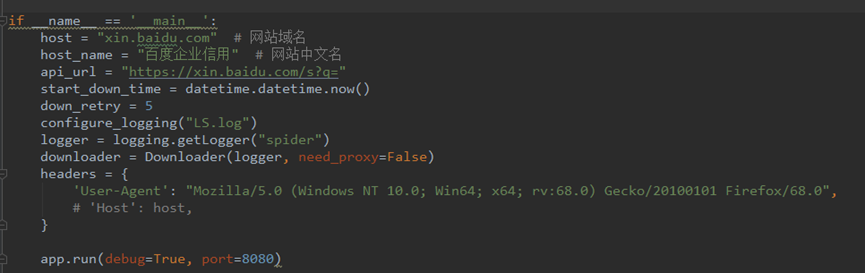
return 返回值:
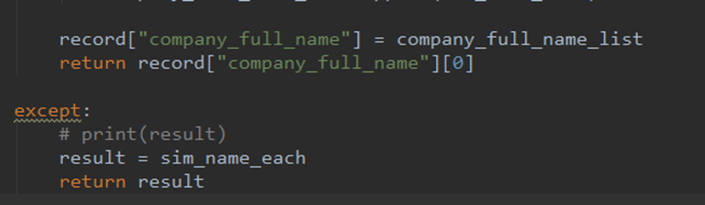
完整代码:
#coding=utf8
"""
url:https://xin.baidu.com/
百度企业信用
"""
from flask import abort, jsonify, Flask, request, Response
from bs4 import BeautifulSoup
import logging
import pymongo
import base64
import time, requests
import datetime, random
from etl.utils.log_conf import configure_logging
import traceback
from etl.data_gather.settings import SAVE_MONGO_CONFIG, RESOURCE_DIR
from etl.common_spider.donwloader import Downloader
import json
app = Flask(__name__)
@app.route("/")
def index():
return "hello world"
# request
@app.route('/company_full_name/<string:sim_name_each>', methods=['GET'])
def run(sim_name_each):
'''
数据采集入口
:return:
'''
logger.info("Begin Run")
# ============主页面获取==============================
record = {}
company_full_name_list = []
cur_url = "%s%s&t=1" % (api_url, sim_name_each)
print(cur_url)
print(sim_name_each)
resp = downloader.crawl_data(cur_url, None, headers, "get", ) # 使用downloader文件的ip代理请求
if not resp:
# print(result)
result = '搜索失败'
return result
else:
resp.encoding = 'utf-8'
content = resp.content
try:
soup = BeautifulSoup(content, "lxml")
# TODO company_full_name
content_name_tag = soup.find(name='div', attrs={'class': 'zx-ent-items'})
if content_name_tag:
content_name = content_name_tag.find('a')
if content_name:
company_full_name = content_name.get_text().strip().replace('点击阅读全文', '')
print(company_full_name)
company_full_name_list.append(company_full_name)
else:
print('没有company_full_name')
company_full_name_list.append(sim_name_each)
record["company_full_name"] = company_full_name_list
return record["company_full_name"][0]
except:
# print(result)
result = sim_name_each
return result
if __name__ == '__main__':
host = "xin.baidu.com" # 网站域名
host_name = "百度企业信用" # 网站中文名
api_url = "https://xin.baidu.com/s?q="
start_down_time = datetime.datetime.now()
down_retry = 5
configure_logging("LS.log")
logger = logging.getLogger("spider")
downloader = Downloader(logger, need_proxy=False)
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0",
# 'Host': host,
}
app.run(debug=True, port=8080)
3.flask 报错信息 [Errno 99] Cannot assign requested address
https://blog.csdn.net/x0000009/article/details/96398840
4.flask 异步接口
from threading import Thread
from functools import wraps
from flask import Flask, jsonify
app = Flask(__name__)
def asyncz(f):
wraps(f)
def wrapper(*args, **kwargs):
thr = Thread(target=f, args=args, kwargs=kwargs)
thr.start()
return wrapper
@asyncz
def long_task():
"""耗时处理逻辑
:return:
"""
import time
time.sleep(10)
print('长时间处理')
print('更新状态')
print('OK')
print('---------------------------------------------')
def insert_data():
print('插入记录')
return '插入成功'
@app.route('/test')
def index():
# 同步执行插入
res = insert_data()
print('插入:', res)
# 耗时处理逻辑
long_task()
# 同步返回结果
result = {'code': '000000', 'message': 'message', 'data': {}}
return jsonify(result)
if __name__ == '__main__':
app.run(debug=True)
Python 练习题
1.非润年数字相加的题目练习:
#这里 % 是取模的意思
#" / "就表示 浮点数除法,返回浮点结果;" // "表示整数除法。
print(-123%10) 输出 7:
-123%10 = -123 - 10 * (-123 // 10) = -123 - 10 * (-13) = 7
print(123%-10) 输出 -7
在"a//n"这一步,当a是负数的时候,会向下取整,是正数时也向下取余。
在Python中,取余的计算公式与别的语言并没有什么区别:r=a-n*[a//n]
这里r是余数,a是被除数,n是除数。
初步版本:
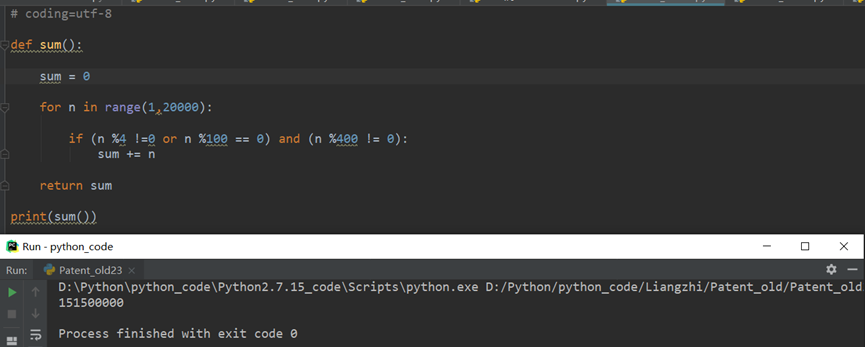
改进版本:
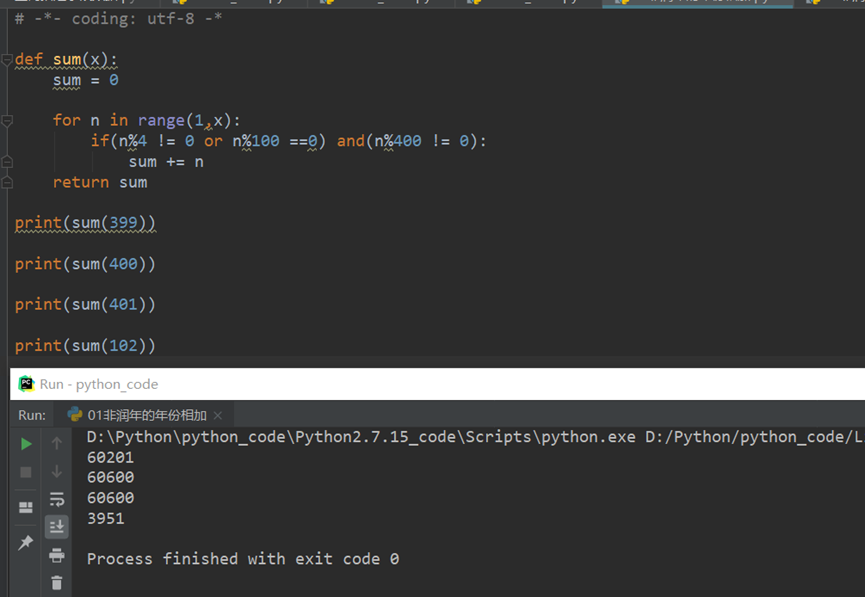
2.
方案1:
a=raw_input()
sum=0
k=0
result=''
for chr in a:
sum=sum+int(chr)
str_sum=str(sum)
for chr1 in str_sum:
if(chr1=='1'):
result+='yi'
if(chr1=='2'):
result+='er'
if(chr1=='3'):
result+='san'
if(chr1=='4'):
result+='si'
if(chr1=='5'):
result+='wu'
if(chr1=='6'):
result+='liu'
if(chr1=='7'):
result+='qi'
if(chr1=='8'):
result+='ba'
if(chr1=='9'):
result+='jiu'
if(chr1=='0'):
result+='ling'
k=k+1
if k!=len(str_sum):
result+=' '
print(result)
方案2:
number = {
'1': 'yi',
'2': 'er',
'3': 'san',
'4': 'si',
'5': 'wu',
'6': 'liu',
'7': 'qi',
'8': 'ba',
'9': 'jiu',
'0': 'ling'
}
def add_n():
n = raw_input()
sum_n = 0
for i in range(len(n)):
sum_n += int(n[i])
return sum_n
c = add_n()
d = str(c)
e = []
k = 0
for i in range(len(d)):
f = e.append(number[d[i]])
k = k + 1
if k != len(d):
e += ' '
print("".join(e))
main函数写法
http://www.360doc.com/content/16/0424/16/31913486_553405472.shtml
Html 基础
1.html介绍
HTML 是用来描述网页的一种语言。
HTML 指的是超文本标记语言: HyperText Markup Language
HTML 不是一种编程语言,而是一种标记语言
标记语言是一套标记标签 (markup tag)
HTML 使用标记标签来描述网页
HTML 文档包含了HTML 标签及文本内容
HTML文档也叫做 web 页面
<!DOCTYPE html> 声明为 HTML5 文档
<html> 元素是 HTML 页面的根元素
<head> 元素包含了文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。
<title> 元素描述了文档的标题
<body> 元素包含了可见的页面内容
<h1> 元素定义一个大标题
<p> 元素定义一个段落
html元素
<!DOCTYPE html> 声明为 HTML5 文档
<html> 元素是 HTML 页面的根元素
<head> 元素包含了文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。
<title> 元素描述了文档的标题
<body> 元素包含了可见的页面内容
<h1> 元素定义一个大标题
<p> 元素定义一个段落
<a> HTML 链接由 <a> 标签定义。链接的地址在 href 属性中指定
<a href="http://www.runoob.com">这是一个链接</a>
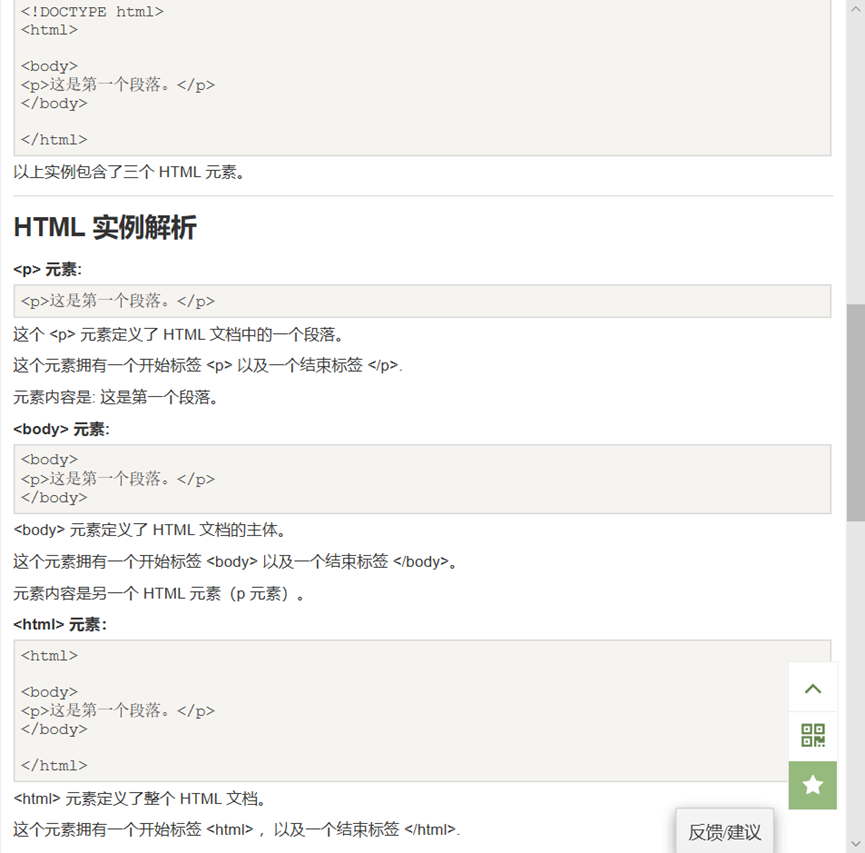
2.html5
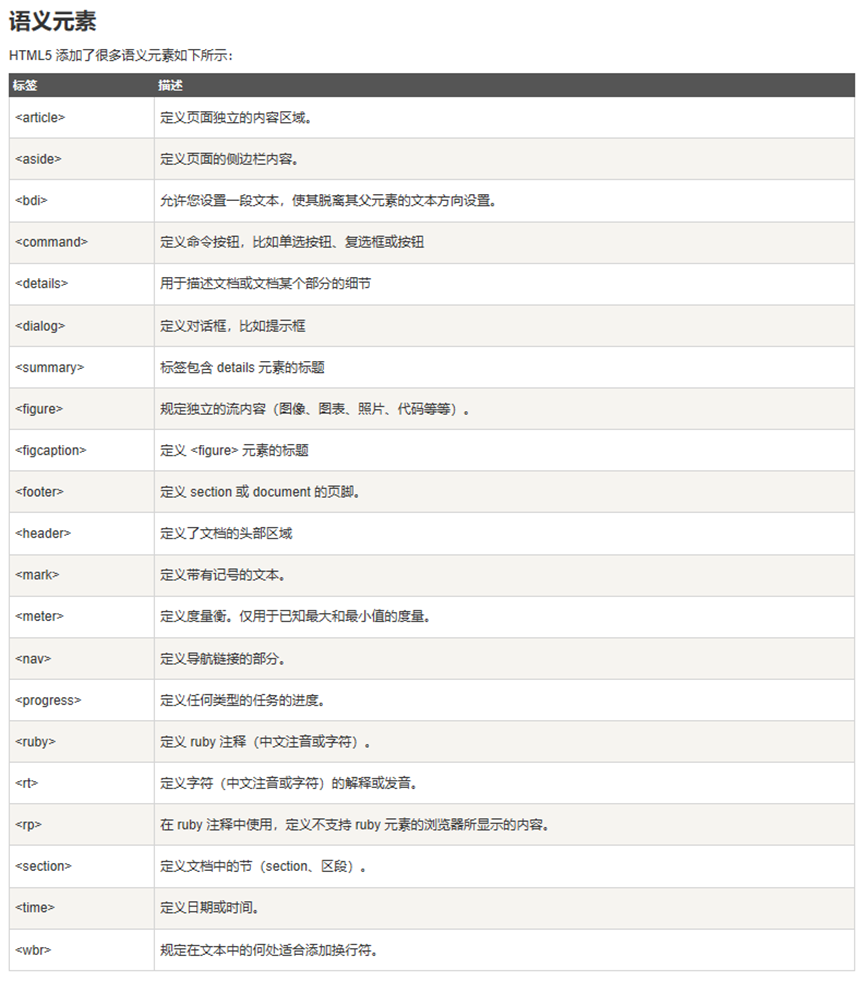
超文本标记语言(或超文本标签语言)的结构包括"头"部分、和"主体"部分,其中"头"部提供关于网页的信息,"主体"部分提供网页的具体内容。
<html> 与 </html> 之间的文本描述网页
<body> 与 </body> 之间的文本是可见的页面内容
<h1> 与 </h1> 之间的文本被显示为标题
<h1> 定义最大的标题。<h6> 定义最小的标题。
<p> 与 </p> 之间的文本被显示为段落
<hr> 标签在 HTML 页面中创建一条水平线。
(horizontal rule)水平分隔线,可以在视觉上将文档分隔成各个部分。
<b>bold 呈现粗体文本效果。
<br> 可插入一个简单的换行符。blank rule ,<br> 标签是空标签(意味着它没有结束标签,因此这是错误的:<br></br>)。在 XHTML 中,把结束标签放在开始标签中,也就是 <br />。
请注意,<br> 标签只是简单地开始新的一行。
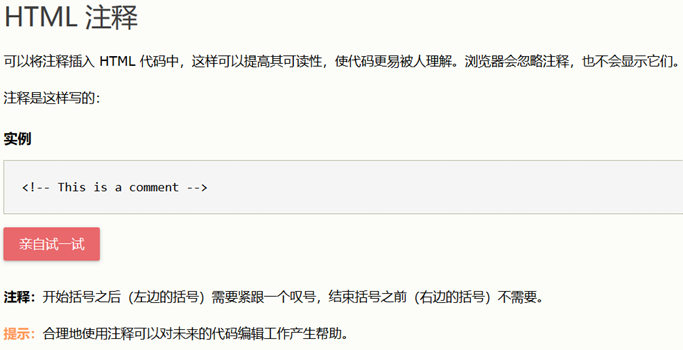




3.DOM节点 html节点

4.Headers 参数含义
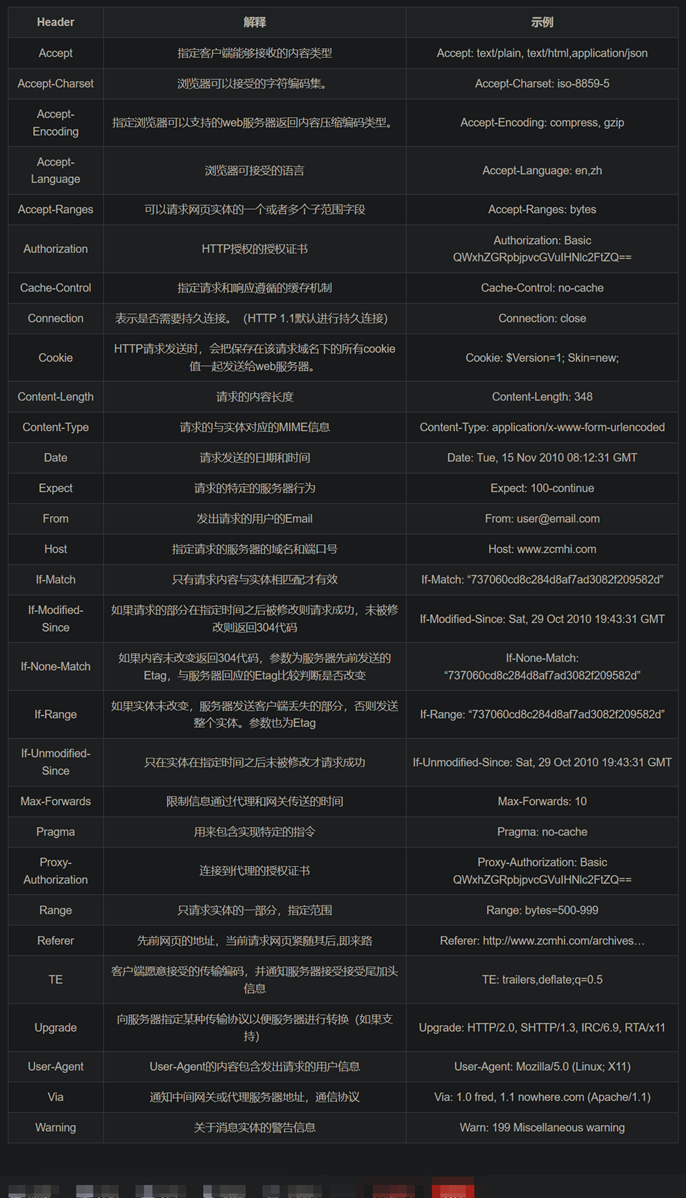
5.html概念
URL的定义和组成
Uniform Resource Locator 统一资源定位符
URL的组成部分:http://www.mbalib.com/china/index.htm
http://:代表超文本传输协议
www:代表一个万维网服务器
mbalib.com/:服务器的域名,或服务器名称
China/:子目录,类似于我们的文件夹
Index.htm:是文件夹中的一个文件
/china/index.htm统称为URL路径
6.XHR 是什么
在XHR诞生前,网页要获取客户端和服务器的任何状态更新,都需要刷新一次,在XHR诞生后就可以完全通过JS代码异步实现这一过程。XHR的诞生也使最初的网页制作转换为开发交互应用,拉开了WEB2.0的序幕。
XHR是一种浏览器API,极大简化了异步通信的过程,开发者并不需要关注底层的实现,因为浏览器会为我们完成这些工作,如连接管理、协议协商、HTTP请求格式化等等。最初版本的XHR能力非常有限,只支持文本传输,处理上传能力也不足,对于跨域请求也不支持。为解决这些问题,W3C于2008年发布了“XMLHttpRequest Level2”草案,新增了如下功能:
• 支持请求超时;
• 支持传输二进制和文本数据;
• 支持重写媒体类型和编码响应;
• 支持监控每个请求的进度事件;
• 支持有效的文件上传;
• 支持安全的跨来源请求。
2011年,W3C将“XMLHttpRequest Level2”规范与最初的“XMLHttpRequest”规范合并,所有XHR2新增的功能也都并入了原来的XHR API中,接口不变,功能增强。
JavaScript JS基础语法
https://www.runoob.com/js/js-functions.html
实例网站加解密 解析:
// 默认参数 e=8, t=ture, 产生n
function tra (e, t) {
var n = ""
, n = Math.ceil(1e14 * Math.random()).toString().substr(0, e || 4);
return t && (n += Date.now()),
n
}
1.crypto-js 加密、解密使用方法
https://blog.csdn.net/qq_34707272/article/details/121857485
npm install crypto-js
npm install crypto-js -g
2.npm和pip
pip
pip,全称是:package installer for Python,它是一个现代的,通用的 Python 包管理工具,是 easy_install 的替代品。提供了对 Python 包的查找、下载、安装、卸载的功能。只要有人把某个代码模块打包放在一个叫做 PiPI 的地方,其他人就可以从这个 PiPI 中下载安装包。只要包存在于 PiPI,都能使用 pip 命令来安装下载。
如果不指定下载源,默认从官方的 PyPI 下载,也可以通过指定下载源来让 pip 从指定的 pypi 找包然后安装,比如有些公司可能有自己的源,如果想下载公司内部的工具包,就得在使用 pip 命令时加上源参数。
PyPI,全称是:Python Package Index,它是Python官方的第三方库的仓库,所有人都可以下载第三方库或上传自己开发的库到 PyPI。
Python 内置了 pip,Python 使用 pip 来安装包。pip 运行在 Python 上。
npm
npm 全称是 Node Package(包) Manager(管理器),连起来就是 Node.js 的包管理器,提供了对 Node.js 包的查找、下载、安装、卸载的功能。只要有人把某个代码模块打包放在一个叫做「npm Registry」的地方,其他人就可以从这个「npm Registry」中下载安装包,只要包存在于「npm registry」,都能使用 npm 命令来安装下载。
如果不指定下载源,默认从官方的 「npm Registry」下载,也可以通过指定下载源来让 npm 从指定的 Registry 找包然后安装,比如有些公司可能有自己的源,如果想下载公司内部的工具包,就得在使用 npm 命令时加上源参数。
Node.js 内置了 npm,Node.js 使用 npm 来安装 module 包,npm 是用 Javascript 写的,运行在 Node.js 上。
Python 多线程 threading模块
https://www.cnblogs.com/OliverQin/p/12631844.html
1.多线程加入参数 threading中加入参数
https://blog.csdn.net/wei18791957243/article/details/83995823
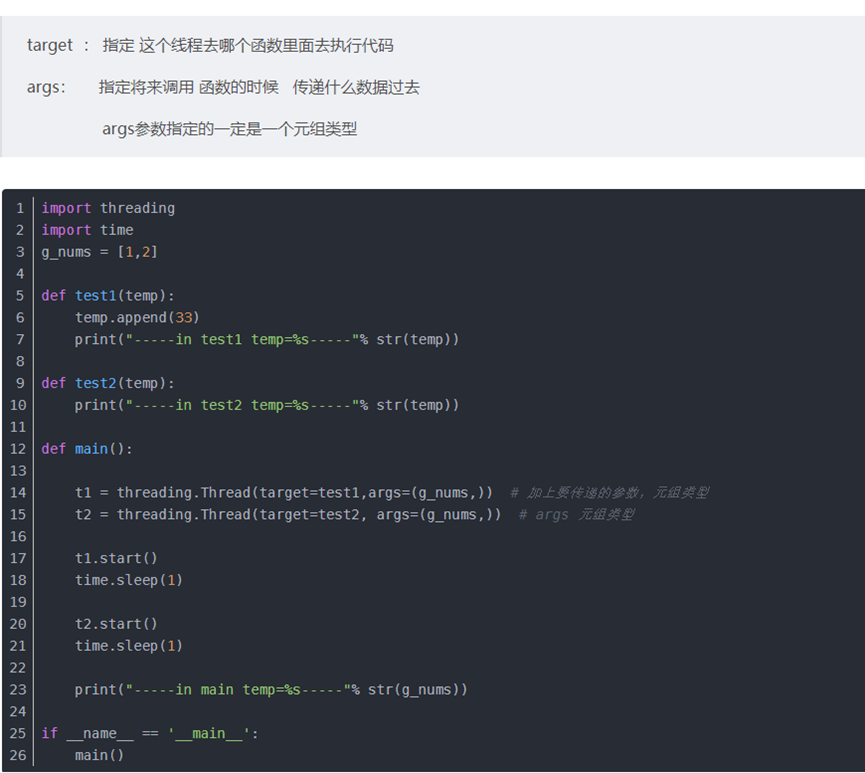
代码:
if __name__ == '__main__':
t1 = threading.Thread(name='threading01', target=spider01,args=('lz_data_combine_company_name001.txt',))
t2 = threading.Thread(name='threading02', target=spider01,args=('lz_data_combine_company_name002.txt',))
t3 = threading.Thread(name='threading03', target=spider01, args=('lz_data_combine_company_name003.txt',))
t4 = threading.Thread(name='threading04', target=spider01, args=('lz_data_combine_company_name004.txt',))
t5 = threading.Thread(name='threading05', target=spider01, args=('lz_data_combine_company_name005.txt',))
t6 = threading.Thread(name='threading06', target=spider01, args=('lz_data_combine_company_name006.txt',))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
python requests库的使用
requests.get(url, params=params,headers=headers)
最基本的get方法:response = requests.get(“http://www.baidu.com/”)
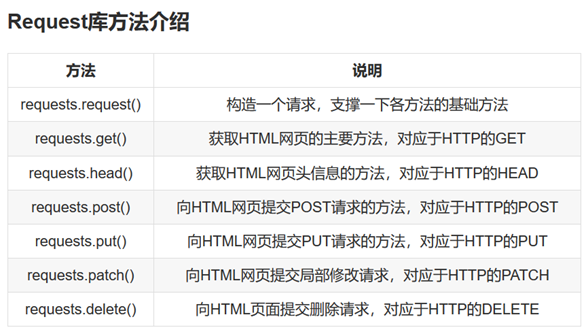
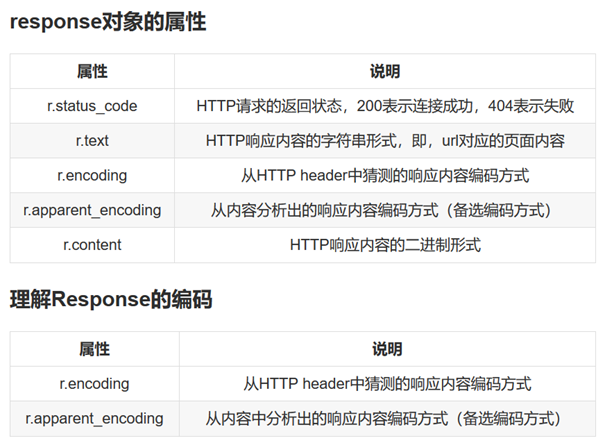

1.requests概念 https://www.cnblogs.com/ranxf/p/7808537.html
GET是从服务器上获取数据,POST是向服务器传送数据。
r.text:
以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。
r.content:
以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。
2.带参数的请求
https://blog.csdn.net/xiaochendefendoushi/article/details/81124894
如果发送GET请求需要指定参数怎么办
方式1: 拼接URL(推荐)
方式2: 通过params参数指定
原则: 使用哪种方式简单就用哪种方式
3.requests模块获取cookie

cookies = requests.utils.dict_from_cookiejar(response.cookies)
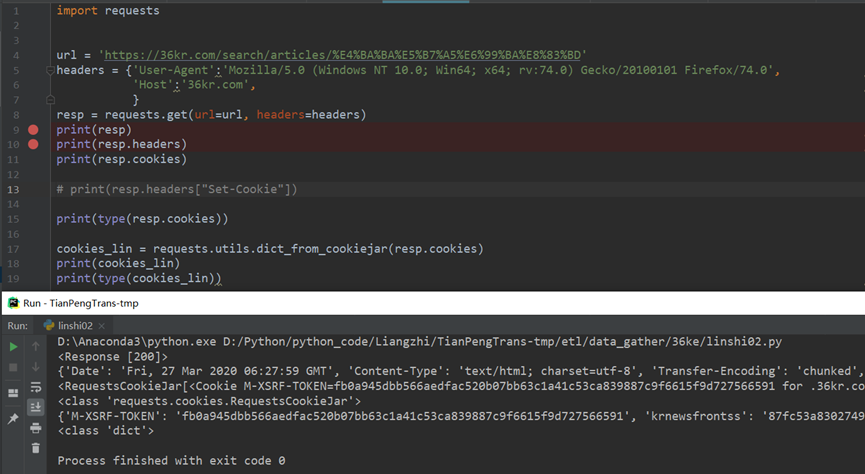
4.网页未响应 情况1:无response,报错 情况2:有response,为[ ]
情况1:无response,服务器没有响应,response为None

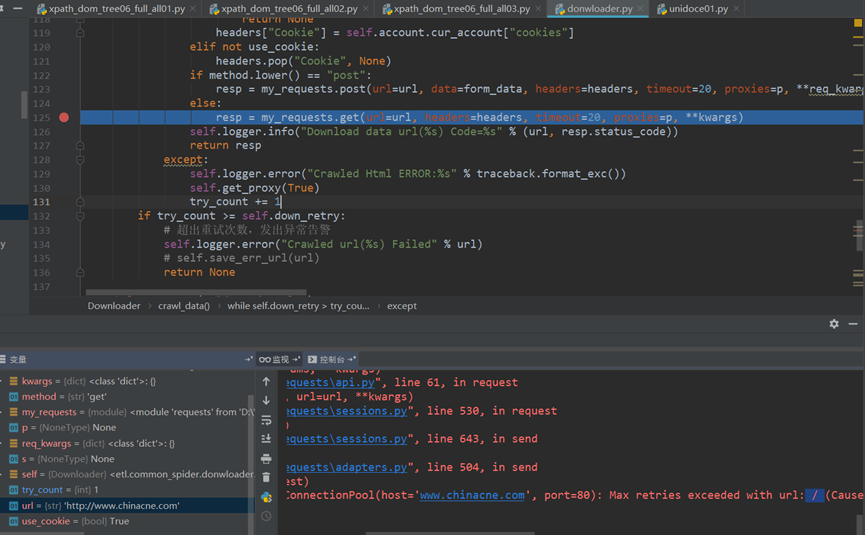
情况2:有response,返回空

5.requests.post
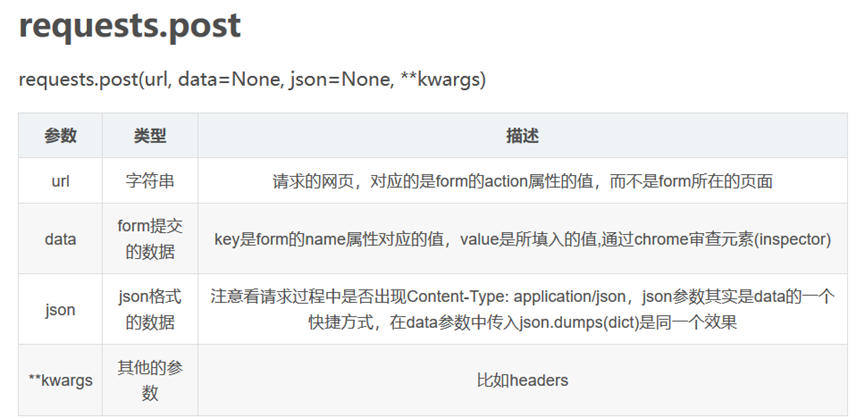
6.session = requests.session()
7.浏览器直接获取cURl命令 导入到 postman
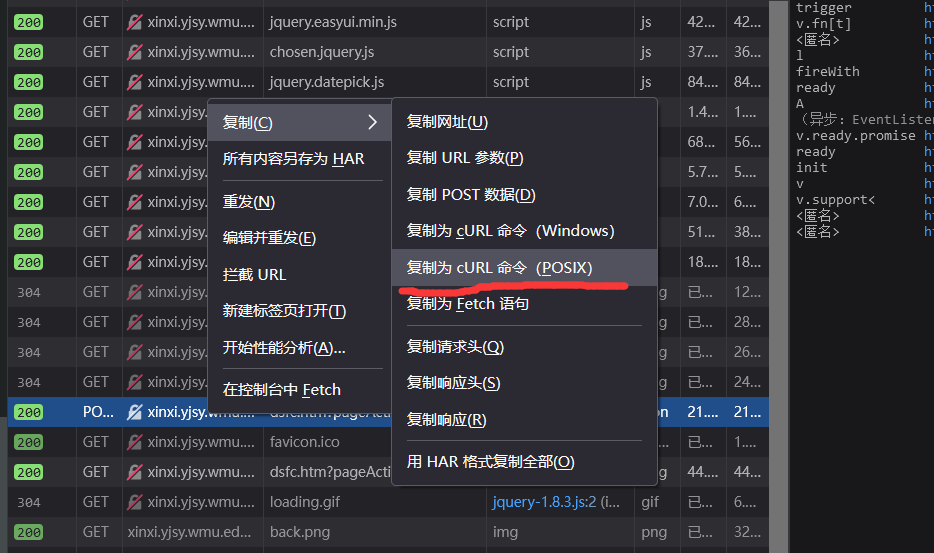
常见的编码方式
常见的有 ASCII、ISO-88591、GB23112、GBK、UTF-8、UTF-8、UTF-16。
在选择编码格式来存储汉字时,一般要考虑是存储空间还是编码的效率重要。
ASCII 码
ASCII 码总共有128个,用1个字节的低七位表示,0~31 是控制字符如换行、回车、删除等,32~126 是打印字符,可以通过键盘输入并且能够显示出来。
.ISO-8859-1
128个字符显然是不够用的,于是ISO组织在ASCII 码基础上又制定了一系列标准来拓展 ASCII 编码,它们是ISO-8859-1 至 ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所以应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
GB2312
GB2312 的全称是 《信息技术 中文编码字符集》,它是双字节编码,总的编码范围是 A1~F7,其中A1 ~ A9 是符号区,总共包含682个字符; B0~F7 是汉字区,包含6763个汉字。
GBK
全称是《汉字内码扩展规范》,它的出现是为了拓展 GB2312 ,并加入更多的汉字。它的编码是和GB2312 兼容的,也就是说用GB2312 编码的汉字可以用GBK 来解码,并且不会有乱码。
UTF-16
说到UTF 必须提到 Unicode ,ISO 试图创建一个全新的超语言字典,世界上所有的语言都可以通过这个字典来相互翻译。UTF-16 具体定义了Unicode 在计算中的存取方法。UTF-16 用两个字节来表示 Unicode 的转化格式,采用定长的表示方法,即不论什么字符都可以用两个字节表示。
UTF-8
UTF-16 存在存储空间浪费。UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以由1~6 个字节组成。如果是一个字节,最高位为0,则表示这是 1 个 ASCII 字符,可见,所有ASCII 编码已经是UTF-8了。
python爬虫 bs4 BeautifulSoup库
from bs4 import BeautifulSoup
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
截取h1标题,如下图
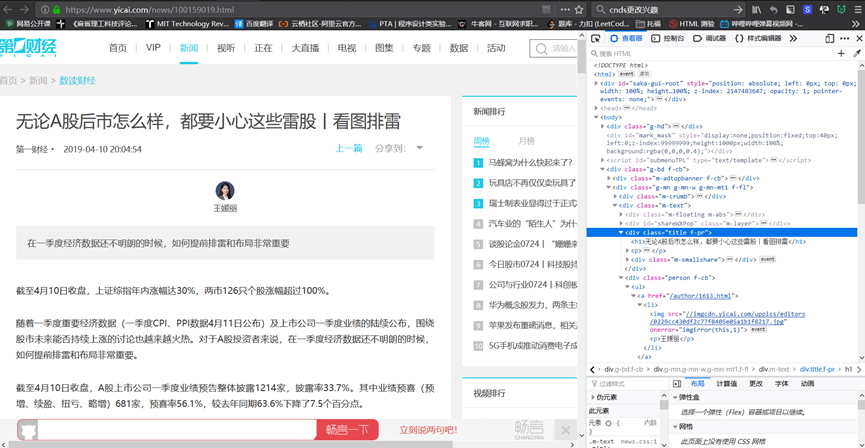
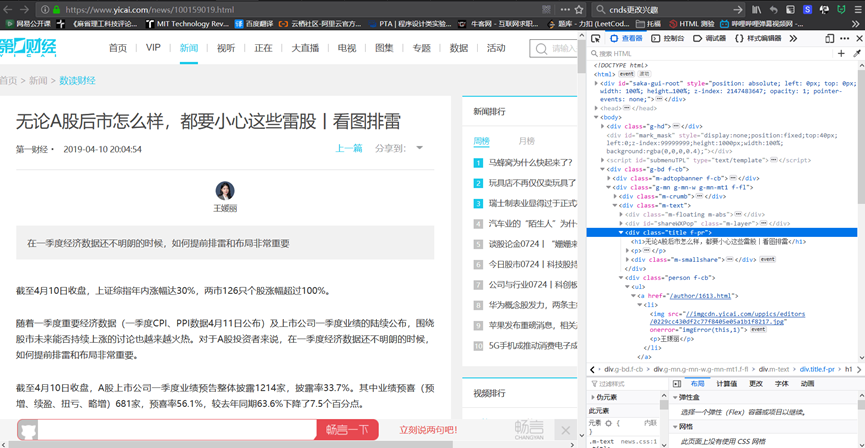

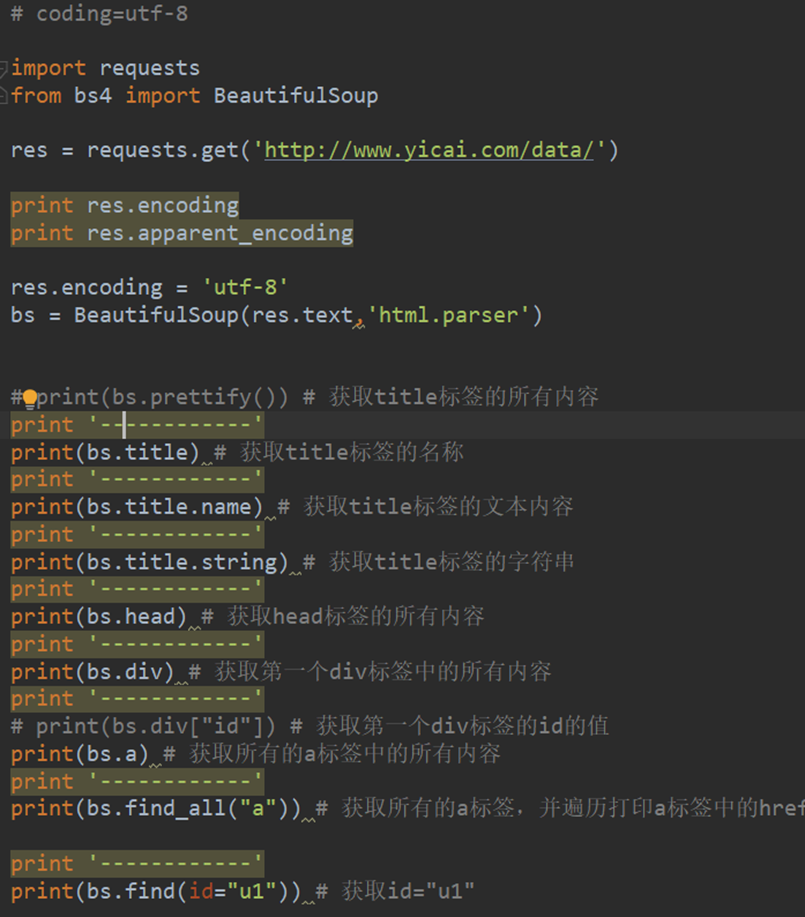
1.BeautifulSoup 爬正文
BeautifulSoup 是一个能从 HTML 或 XML 文件中提取数据的 Python 库。
soup.prettify()函数的作用是打印整个 html 文件的 dom 树。
怎么理解soup=BeautifulSoup(html,’html.parser’):
是指定Beautiful的解析器为”html.parser”还有BeautifulSoup(markup,”lxml”)BeautifulSoup(markup, “lxml-xml”) BeautifulSoup(markup,”xml”)等等很多种。
2.BS4抓取超链接
p.s. selenium库类似request库
name=[i.text.strip() for i in soup.findAll(name=’p’,attrs = {‘class’:’productTitle’})]
两个不同的find:
findAll(tag,attributes,recursive,text,limit,keywords)
find(tag,attributes,recursive,text,keywords)
p.s.搜狗微信搜索界面的链接需要用data-share来访问,而不是href链接
3.特殊情况
无法抓取到时间,在整个r1.text 输出结果中 crl+f搜索到时间在script脚本中
从新定位script

4.beautifulsoup select() 方法
bs4获取a标签的方法 soup.select()
conference_profession = soup.select('div[class="tt t2"] a')
print soup.select('p a[href="http://example.com/elsie"]')
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
conference_profession = soup.select('div[class="tt t2"] a')
5. bs4.element.Tag bs4.element.ResultSet
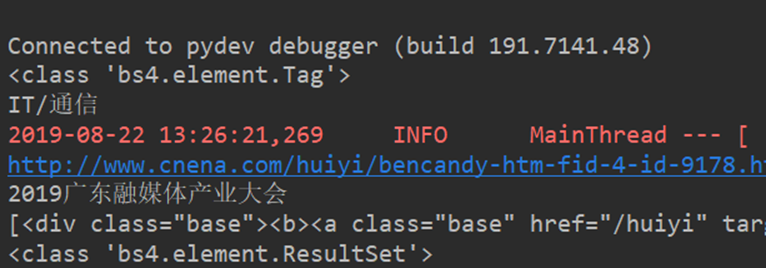
6.find_all的结果是 列表 find的结果是个tag tag可以用get.text()
for i in soup1.find(name=’p’, attrs={‘class’: ‘autor_name’}) 结果也是个tag
7.重点理解下这里的label:要先定义下label
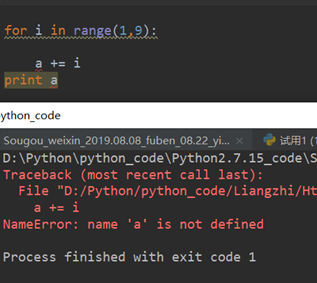
定义后:
8.BeautifulSoup中各种html解析器的比較及使用
https://www.cnblogs.com/wzzkaifa/p/7111431.html
9.requests的content和text方法的区别
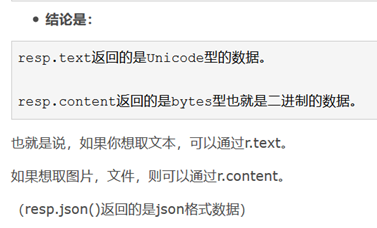
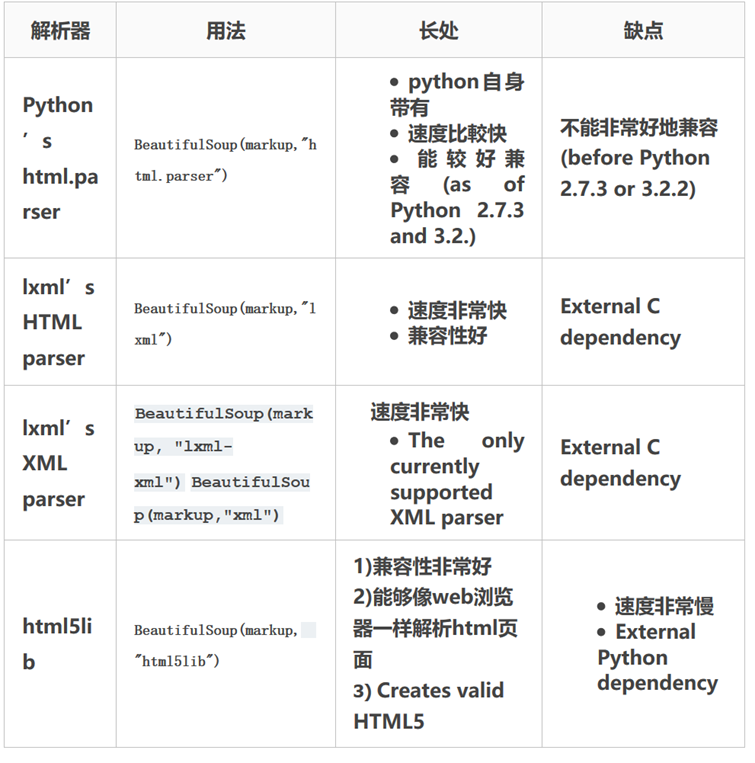
10.BeautifulSoup去除HTML指定标签和去除注释
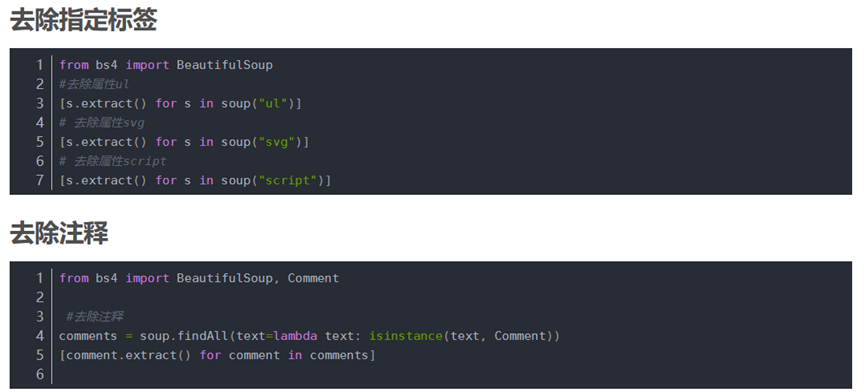
实例:
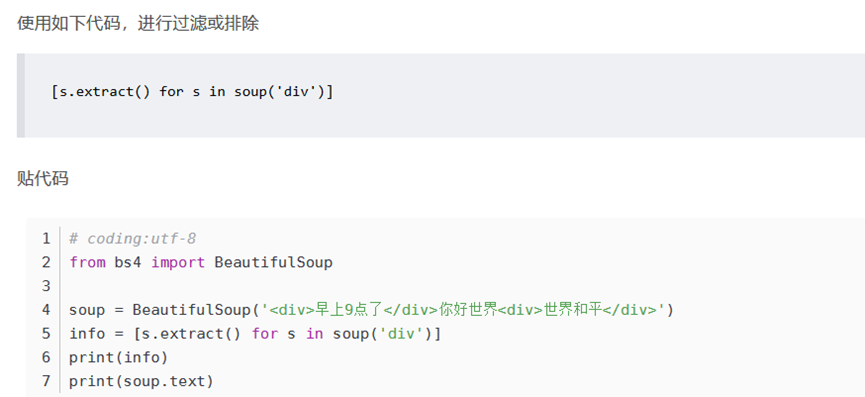
content_tag = soup.find('div',{'class':'dft-main clearfix'})
if content_tag:
# 去除属性ul
[s.extract() for s in content_tag("ul")]
[s.extract() for s in content_tag("style")]
# 去除属性svg
[s.extract() for s in content_tag("svg")]
# 去除属性script
[s.extract() for s in content_tag("script")]
content = content_tag.get_text().strip().replace('暂无内容', '').replace("'src'",'')
print(content)
11.Beautiful soup 父标签 子标签
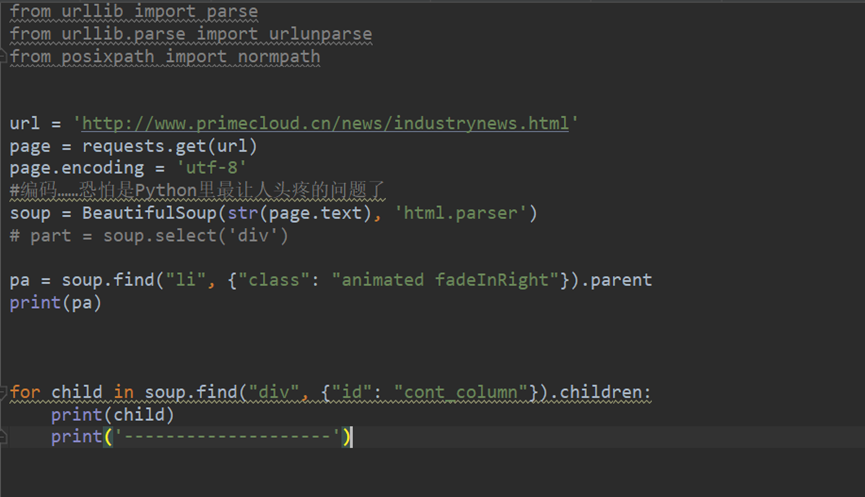
正则匹配 正则表达式 Regular Expression
1.re.sub,replace(),strip()的区别:
去掉两端字符串: strip()
h1.replace(‘<h1>’, ‘’)
re.sub(‘</h1>’, ‘ ‘, h1))
2.用python正则表达式提取字符串 re.findall(r”a(.+?)b”,str)
https://www.cnblogs.com/rj81/p/5933838.html
import re
str = "a123b"
print (re.findall(r"a(.+?)b",str))
输出['123']

需要截取时间:
time = re.findall(r’“,s=”(.+?)”;’, time):
正则表达式.匹配不到\n 的文本
使用正则表达式来获取一段文本中的任意字符,(.*)
结果运行之后才发现,无法获得换行之后的文本。
因为“.”(点符号)匹配的是除了换行符“\n”以外的所有字符。
以下为正确的正则表达式匹配规则:
(.)替换为([\s\S])即可
3.列表取除了第一个数的其他数 https://blog.csdn.net/jialibang/article/details/84989279
str="http://www.runoob.com/python/att-string-split.html"
print("0:%s"%str.split("/")[-1])
print("1:%s"%str.split("/")[-2])
print("2:%s"%str.split("/")[-3])
print("3:%s"%str.split("/")[-4])
print("4:%s"%str.split("/")[-5])
print("5:%s"%str.split("/",-1))
print("6:%s"%str.split("/",0))
print("7:%s"%str.split("/",1))
print("8:%s"%str.split("/",2))
print("9:%s"%str.split("/",3))
print("10:%s"%str.split("/",4))
print("11:%s"%str.split("/",5))
结果是:
0:att-string-split.html
1:python
2:www.runoob.com
3:
4:http:
5:['http:', '', 'www.runoob.com', 'python', 'att-string-split.html']
6:['http://www.runoob.com/python/att-string-split.html']
7:['http:', '/www.runoob.com/python/att-string-split.html']
8:['http:', '', 'www.runoob.com/python/att-string-split.html']
9:['http:', '', 'www.runoob.com', 'python/att-string-split.html']
10:['http:', '', 'www.runoob.com', 'python', 'att-string-split.html']
11:['http:', '', 'www.runoob.com', 'python', 'att-string-split.html']
即: -1 :全切 0 :不切 1:切一刀 (每一块都保留)
[-1]:将最后一块切割出来 [-2]:将倒数第二块切割出来 (只保留切出来的一块)
4.正则匹配学习记录
5.正则匹配 邮箱、电话、整数、日期、密码
https://www.jb51.net/article/176949.htm
import re
##匹配列表内的非负整数
list = [99,100,-100,-1,90]
pattern = re.compile(r'[1-9]\d*|0')
for i in list:
m = pattern.search(str(i))
print(m)
##匹配列表内的整数
list = [99,100,-100,-1,90]
pattern = re.compile(r'[1-9]\d*')
for i in list:
m = pattern.match(str(i))
print(m)
##匹配列表内的非正整数
list = [99,100,-100,-1,90]
pattern = re.compile(r'-[1-9]\d*|0')
for i in list:
m = pattern.match(str(i))
print(m)
# ##正则匹配邮箱
c = re.compile(r'^\w+@(\w+\.)+(com|cn|net|edu)$')
string = '507722618@qq.com'
s = c.search(string)
if s:
print(s.group())
##匹配十一位手机号
c = re.compile(r'^1[3-9]\d{9}$')
s = c.search('18785397892')
if s:
print(s.group())
c = re.compile(r'^[1-9]\d*|0$')
s = c.search('')
if s:
print(s.group())
##正则匹配日期
pattern = re.compile(r'[1-9]\d{3}-(1[0-2]|0?[1-9])-(3[0-1]|[1-2]\d|0?[1-9])')#定义匹配模式
string = 'hgfdjyjhfdjjj,2019-12-19jhgfjhgfjhf'
s = re.search(string)
print(s.group())
print(pattern.search(string,s.end()+1))
##匹配密码
pattern = re.compile(r'[A-Z]\w{7,9}')
m = pattern.search('basldaE3217894_324yiudasjl')
if m :
print(m.group())
正则匹配 邮箱地址
https://www.jb51.net/article/166059.htm
https://blog.csdn.net/zrr789/article/details/79918247
https://blog.csdn.net/m0_37360684/article/details/84140403
match()函数只检测RE是不是在string的开始位置匹配
search()会扫描整个string查找匹配,会扫描整个字符串并返回第一个成功的匹配
也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none
import re
a = '通讯地址:上海市曹安公路4800号电信大楼,邮政编码:201804,电子邮件:nijanice@163.com'
pat3 = '(\w)+(\.\w+)*@(\w)+((\.\w+)+)'
matched_address = re.search(pat3, a)
print(matched_address)
print(matched_address.group())
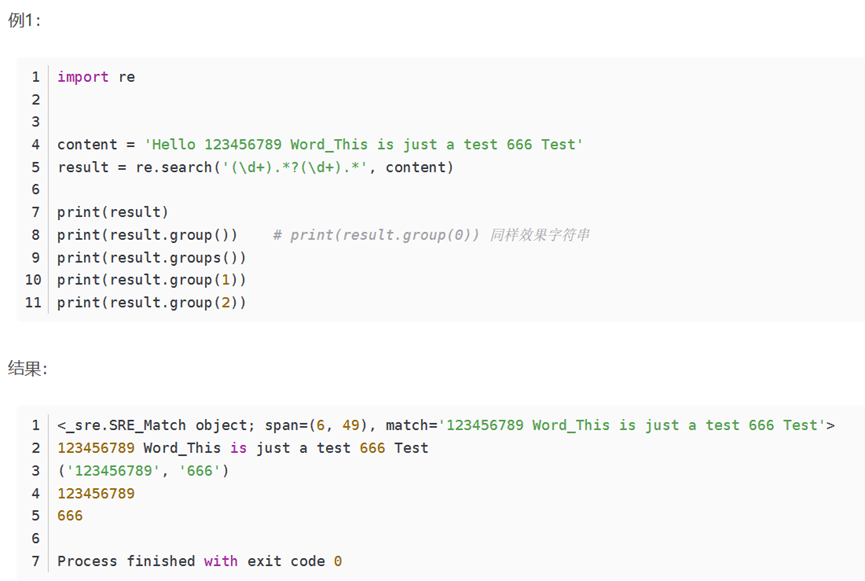
import re
pat = r'^(\w)+(\.\w+)*@(\w)+((\.\w+)+)$'
email_address = 'ddy_davie@aaa.com'
matched_address = re.match(pat, email_address)
print(matched_address.group())
text="JGod is a handsome boy ,but he is a ider"
print re.findall(r'\w*o\w*',text) #查找有o的单词
#输出结果为:['JGod', 'handsome', 'boy']
^ 脱字字符表示匹配搜索字符中串的开始位置。
& 恰好相反,表示匹配搜索字符串中结尾位置。

匹配电话号码
写一个正则表达式,能匹配出多种格式的电话号码,包括:
text = "(021)88776543 010-55667890 02584533622 057184720483 837922740"
m = re.findall(r'\(?0\d{2,3}[)-]?\d{7,8}',text)
if m:
print(m)
else:
print('not match')
网站匹配
url = 'dddddsas, 网址:https://www.cnblogs.com/papapython/p/7482349.html'
regular = re.compile(r'[a-zA-Z]+://[^\s]*[.com|.cn]')
print(re.findall(regular, url))
忽略大小写

8.正则表达式语法
https://www.jb51.net/article/50511.htm
正则表达式(RE)指定一个与之匹配的字符集合;本模块所提供的函数,将可以用来检查所给的字符串是否与指定的正则表达式匹配。
正则表达式可以被连接,从而形成新的正则表达式;例如A和B都是正则表达式,那么AB也是正则表达式。一般地,如果字符串p与A匹配,q与B匹配的话,那么字符串pq也会与AB匹配,但A或者B里含有边界限定条件或者命名组操作的情况除外。也就是说,复杂的正则表达式可以用简单的连接而成。
正则表达式可以包含特殊字符和普通字符,大部分字符比如’A’,’a’和’0’都是普通字符,如果做为正则表达式,它们将匹配它们本身。由于正则表达式可以连接,所以连接多个普通字符而成的正则表达式last也将匹配’last’。(后面将用不带引号的表示正则表达式,带引号的表示字符串)
下面就来介绍正则表达式的特殊字符:
‘.’
点号,在普通模式,它匹配除换行符外的任意一个字符;如果指定了 DOTALL 标记,匹配包括换行符以内的任意一个字符。
‘^’
尖尖号,匹配一个字符串的开始,在 MULTILINE 模式下,也将匹配任意一个新行的开始。
‘$’
美元符号,匹配一个字符串的结尾或者字符串最后面的换行符,在 MULTILINE 模式下,也匹配任意一行的行尾。也就是说,普通模式下,foo.$去搜索’foo1\nfoo2\n’只会找到’foo2′,但是在 MULTILINE 模式,还能找到 ‘foo1′,而且就用一个 $ 去搜索’foo\n’的话,会找到两个空的匹配:一个是最后的换行符,一个是字符串的结尾,演示:
代码如下:
re.findall(‘(foo.$)’, ‘foo1\nfoo2\n’) [‘foo2’] re.findall(‘(foo.$)’, ‘foo1\nfoo2\n’, re.MULTILINE) [‘foo1’, ‘foo2’] re.findall(‘($)’, ‘foo\n’) [’’, ‘’]
‘’
星号,指定将前面的RE重复0次或者任意多次,而且总是试图尽量多次地匹配。
‘+’
加号,指定将前面的RE重复1次或者任意多次,而且总是试图尽量多次地匹配。
‘?’
问号,指定将前面的RE重复0次或者1次,如果有的话,也尽量匹配1次。
*?, +?, ??
从前面的描述可以看到’‘,’+’和’?’都是贪婪的,但这也许并不是我们说要的,所以,可以在后面加个问号,将策略改为非贪婪,只匹配尽量少的RE。示例,体会两者的区别:
代码如下:
>>> re.findall('<(.*)>', '<H1>title</H1>')
['H1>title</H1']
>>> re.findall('<(.*?)>', '<H1>title</H1>')
['H1', '/H1']
{m}
m是一个数字,指定将前面的RE重复m次。
{m,n} m和n都是数字,指定将前面的RE重复m到n次,例如a{3,5}匹配3到5个连续的a。注意,如果省略m,将匹配0到n个前面的RE;如果省略n,将匹配n到无穷多个前面的RE;当然中间的逗号是不能省略的,不然就变成前面那种形式了。
{m,n}? 前面说的{m,n},也是贪婪的,a{3,5}如果有5个以上连续a的话,会匹配5个,这个也可以通过加问号改变。a{3,5}?如果可能的话,将只匹配3个a。
’' 反斜杆,转义’*‘,’?’等特殊字符,或者指定一个特殊序列(下面会详述) 由于之前所述的原因,强烈建议用raw字符串来表述正则。
[ ] 方括号,用于指定一个字符的集合。可以单独列出字符,也可以用’-‘连接起止字符以表示一个范围。特殊字符在中括号里将失效,比如[akm$]就表示字符’a’,’k’,’m’,或’$’,在这里$也变身为普通字符了。[a-z]匹配任意一个小写字母,[a-zA-Z0-9]匹配任意一个字母或数字。如果你要匹配’]’或’-‘本身,你需要加反斜杆转义,或者是将其置于中括号的最前面,比如[]]可以匹配’]’ 你还可以对一个字符集合取反,以匹配任意不在这个字符集合里的字符,取反操作用一个’^’放在集合的最前面表示,放在其他地方的’^’将不会起特殊作用。例如[^5]将匹配任意不是’5’的字符;[^^]将匹配任意不是’^’的字符。 注意:在中括号里,+、*、(、)这类字符将会失去特殊含义,仅作为普通字符。反向引用也不能在中括号内使用。
| ’ | ’ | ||||
| 管道符号,A和B是任意的RE,那么A | B就是匹配A或者B的一个新的RE。任意个数的RE都可以像这样用管道符号间隔连接起来。这种形式可以被用于组中(后面将详述)。对于目标字符串,被’ | ‘分割的RE将自左至右一一被测试,一旦有一个测试成功,后面的将不再被测试,即使后面的RE可能可以匹配更长的串,换句话说,’ | ‘操作符是非贪婪的。要匹配字面意义上的’ | ‘,可以用反斜杆转义:|,或是包含在反括号内:[ | ]。 |
(…) 匹配圆括号里的RE匹配的内容,并指定组的开始和结束位置。组里面的内容可以被提取,也可以采用\number这样的特殊序列,被用于后续的匹配。要匹配字面意义上的’(‘和’)’,可以用反斜杆转义:(、),或是包含在反括号内:[(]、[)]。
(?…) 这是一个表达式的扩展符号。’?’后的第一个字母决定了整个表达式的语法和含义,除了(?P…)以外,表达式不会产生一个新的组。下面介绍几个目前已被支持的扩展:
(?iLmsux) ‘i’、’L’、’m’、’s’、’u’、’x’里的一个或多个字母。表达式不匹配任何字符,但是指定相应的标志:re.I(忽略大小写)、re.L(依赖locale)、re.M(多行模式)、re.S(.匹配所有字符)、re.U(依赖Unicode)、re.X(详细模式)。关于各个模式的区别,下面会有专门的一节来介绍的。使用这个语法可以代替在re.compile()的时候或者调用的时候指定flag参数。 例如,上面举过的例子,可以改写成这样(和指定了re.MULTILINE是一样的效果):
代码如下:
re.findall(‘(?m)(foo.$)’, ‘foo1\nfoo2\n’)
[‘foo1’, ‘foo2’]
另外,还要注意(?x)标志如果有的话,要放在最前面。
(?:…) 匹配内部的RE所匹配的内容,但是不建立组。
(?P
代码如下:
>>> m=re.match('(?P<var>[a-zA-Z_]\w*)', 'abc=123')
>>> m.group('var')
'abc'
>>> m.group(1)
'abc'
(?P=name)
匹配之前以name命名的组里的内容。 演示一下:
代码如下:
>>> re.match('<(?P<tagname>\w*)>.*</(?P=tagname)>', '<h1>xxx</h2>') #这个不匹配
>>> re.match('<(?P<tagname>\w*)>.*</(?P=tagname)>', '<h1>xxx</h1>') #这个匹配
<_sre.SRE_Match object at 0xb69588e0>
(?#…)
注释,圆括号里的内容会被忽略。
(?=…)
如果 … 匹配接下来的字符,才算匹配,但是并不会消耗任何被匹配的字符。例如 Isaac (?=Asimov) 只会匹配后面跟着 ‘Asimov’ 的 ‘Isaac ‘,这个叫做”前瞻断言”。
(?!…)
和上面的相反,只匹配接下来的字符串不匹配 … 的串,这叫做”反前瞻断言”。
(?<=…)
只有当当前位置之前的字符串匹配 … ,整个匹配才有效,这叫”后顾断言”。字符串’abcdef’可以匹配正则(?<=abc)def,因为会后向查找3个字符,看是否为abc。所以内置的子RE,需要是固定长度的,比如可以是abc、a|b,但不能是a*、a{3,4}。注意这种RE永远不会匹配到字符串的开头。举个例子,找到连字符(‘-‘)后的单词:
代码如下:
>>> m = re.search('(?<=-)\w+', 'spam-egg')
>>> m.group(0)
'egg'
(?<!…) 同理,这个叫做”反后顾断言”,子RE需要固定长度的,含义是前面的字符串不匹配 … 整个才算匹配。
(?(id/name)yes-pattern|no-pattern) 如有由id或者name指定的组存在的话,将会匹配yes-pattern,否则将会匹配no-pattern,通常情况下no-pattern也可以省略。例如:(<)?(\w+@\w+(?:.\w+)+)(?(1)>)可以匹配 ‘user@host.com’ 和 ‘user@host.com’,但是不会匹配 ‘<user@host.com’。
下面列出以’'开头的特殊序列。如果某个字符没有在下面列出,那么RE的结果会只匹配那个字母本身,比如,$只匹配字面意义上的’$’。
\number 匹配number所指的组相同的字符串。组的序号从1开始。例如:(.+) \1可以匹配’the the’和’55 55’,但不匹配’the end’。这种序列在一个正则表达式里最多可以有99个,如果number以0开头,或是有3位以上的数字,就会被当做八进制表示的字符了。同时,这个也不能用于方括号内。
\A 只匹配字符串的开始。
\b 匹配单词边界(包括开始和结束),这里的”单词”,是指连续的字母、数字和下划线组成的字符串。注意,\b的定义是\w和\W的交界,所以精确的定义有赖于UNICODE和LOCALE这两个标志位。
\B 和\b相反,\B匹配非单词边界。也依赖于UNICODE和LOCALE这两个标志位。
\d 未指定UNICODE标志时,匹配数字,等效于:[0-9]。指定了UNICODE标志时,还会匹配其他Unicode库里描述为字符串的符号。便于理解,举个例子(好不容易找的例子啊,呵呵):
代码如下:
\u2076\和u2084分别是上标的6和下标的4,属于unicode的DIGIT
>>> unistr = u'\u2076\u2084abc'
>>> print unistr
⁶₄abc
>>> print re.findall('\d+', unistr, re.U)[0]
⁶₄
\D 和\d相反,不多说了。
\s 当未指定UNICODE和LOCALE这两个标志位时,匹配任何空白字符,等效于[ \t\n\r\f\v]。如果指定了LOCALE,则还要加LOCALE相关的空白字符;如果指定了UNICODE,还要加上UNICODE空白字符,如较常见的空宽度连接空格(\uFEFF)、零宽度非连接空格(\u200B)等。
\S 和\s相反,也不多说。
\w 当未指定UNICODE和LOCALE这两个标志位时,等效于[a-zA-Z0-9]。当指定了LOCALE时,为[0-9]加上当前LOCAL指定的字母。当指定了UNICODE时,为[0-9_]加上UNICODE库里的所有字母。
\W 和\w相反,不多说。
\Z 只匹配字符串的结尾。
匹配之搜索
python提供了两种基于正则表达式的操作:匹配(match)从字符串的开始检查字符串是否个正则匹配。而搜索(search)检查字符串任意位置是否有匹配的子串(perl默认就是如此)。 注意,即使search的正则以’^’开头,match和search也还是有许多不同的。
代码如下:
>>> re.match("c", "abcdef") # 不匹配
>>> re.search("c", "abcdef") # 匹配
<_sre.SRE_Match object at ...>
9.正则匹配是否含有中文 re匹配中文和非中文
9.1 是否包含中文
https://blog.csdn.net/edwzhang/article/details/45969723
zhPattern = re.compile(u'[\u4e00-\u9fa5]+')
• match = zhPattern.search(contents)
•
• if match:
• print '有中文:%s' % (match.group(0),)
• else:
• print '没有包含中文'
9.1 re匹配中文和非中文
import re
data = """我始终!@@##¥%…………&alkjdfsb1234\n
566667是中国人woaldsfkjzlkcjxv123*())<>
"""
# 匹配所有汉字
print(re.findall('[\u4e00-\u9fa5]', data))
# 匹配所有单字符,英文,数字,特殊符号
print(re.findall('[\x00-\xff]', data))
# 匹配所有非单字符,入汉字和省略号
print(re.findall('[^\x00-\xff]', data))
“\u4e00-\u9fa5”是unicode编码,一种全世界语言都包括的一种编码。(国际化功能中常常用到),\u4e00-\u9fa5是用来判断是不bai是中文的一个条件
[\u4e00-\u9fa5] //匹配中文字符
^[1-9]\d*$ //匹配正整数
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
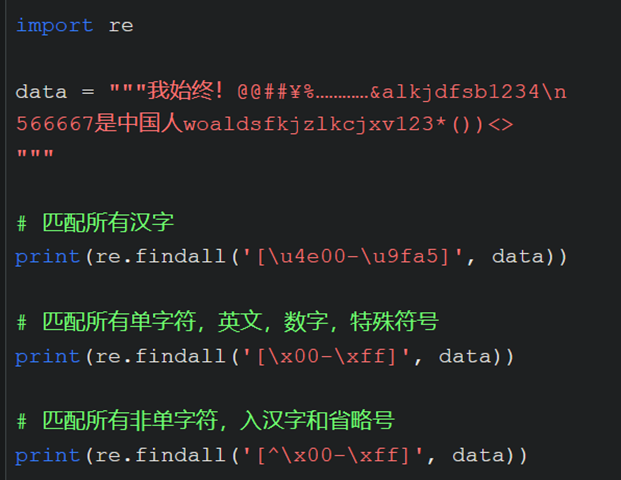
10.re.sub()替换功能
re.sub是个正则表达式方面的函数,用来实现通过正则表达式,实现比普通字符串的replace更加强大的替换功能。简单的替换功能可以使用replace()实现。
11.re模块 去除字母,数字,中文
line = 'experience06'
rule = re.compile(u"[^A-Za-z]")
line = rule.sub(' ', line)
print(line)
12.re.compile 的使用
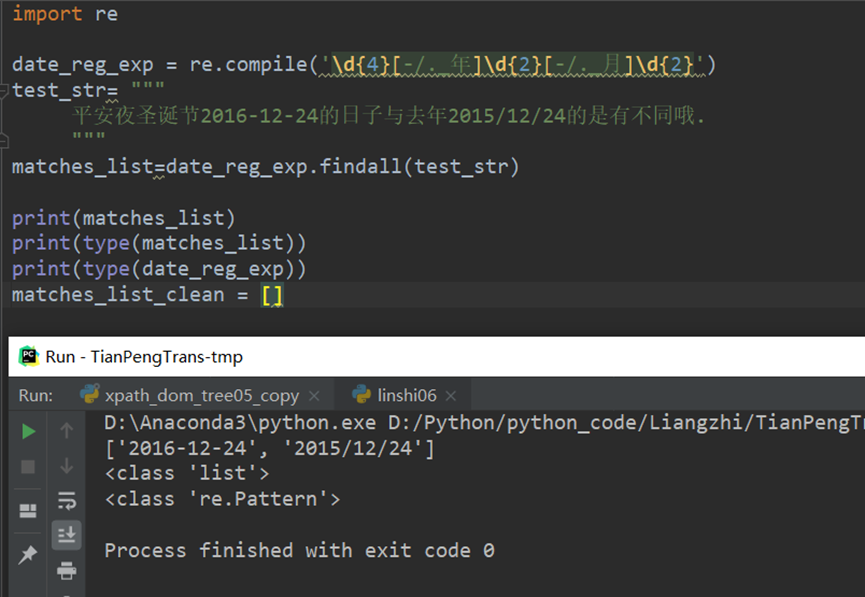
13.re.findall(‘hello(.*?)world’,a,re.S) Python re.S的作用
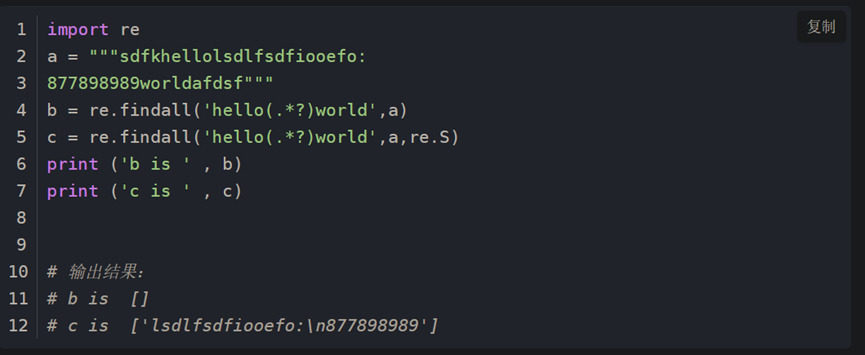
14.正则匹配出数字和小数
v1 = re.search("\d+(\.\d+)?", "100.22元")
print(v1.group())
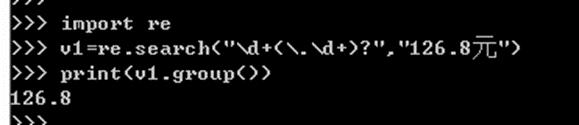
15.正则匹配ip地址
import re
# string_ip = "is this 236.168.192.1 ip 12321"
string_ip = '''192.168.8.84
192.168.8.85
192.168.8.86
0.0.0.1
256.1.1.1
192.256.256.256
192.255.255.255
aa.bb.cc.dd'''
result = re.findall(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b", string_ip)
if result:
print(result)
else:
print ("re cannot find ip")
16.正则表达式符号
正则表达式的一些匹配规则:
. :用于匹配任意一个字符,如 a.c 可以匹配 abc 、aac 、akc 等
^ :用于匹配以...开头的字符,如 ^abc 可以匹配 abcde 、abcc 、abcak 等
$ :用于匹配以...结尾的字符,如 abc$ 可以匹配 xxxabc 、123abc 等
* :匹配前一个字符零次或多次,如 abc* 可以匹配 ab 、abc 、abcccc 等
+ :匹配前一个字符一次或多次,如 abc+ 可以匹配 abc 、abcc 、abcccc 等
? :匹配前一个字符零次或一次,如 abc? 只能匹配到 ab 和 abc
\ :转义字符,比如我想匹配 a.c ,应该写成 a\.c ,否则 . 会被当成匹配字符
| :表示左右表达式任意匹配一个,如 aaa|bbb 可以匹配 aaa 也可以匹配 bbb
[]:匹配中括号中的任意一个字符,如 a[bc]d 可以匹配 abd 和 acd,也可以写一个范围,如 [0-9] 、[a-z] 等
():被括起来的表达式将作为一个分组,如 (abc){2} 可以匹配 abcabc ,a(123|456)b 可以匹配 a123b 或 a456b
{m}:表示匹配前一个字符m次,如 ab{2}c 可以匹配 abbc
{m,n}:表示匹配前一个字符 m 至 n 次,如 ab{1,2}c 可以匹配 abc 或 abbc
\d :匹配数字,如 a\dc 可以匹配 a1c 、a2c 、a3c 等
\D :匹配非数字,也就是除了数字之外的任意字符或符号,如 a\Dc 可以匹配 abc 、aac 、a.c 等
\s :匹配空白字符,也就是匹配空格、换行符、制表符等等,如 a\sc 可以匹配 'a c' 、a\nc 、a\tc 等
\S :匹配非空白字符,也就是匹配空格、换行符、制表符等之外的其他任意字符或符号,如 a\Sc 表示除了 'a c' 之外都能匹配,abc 、a3c 、a.c 等
\w :匹配大小写字母和数字,也就是匹配 [a-zA-Z0-9] 中的字符,如 a\wc 可以匹配 abc 、aBc 、a2c 等
\W :匹配非大小写字母和数字,也就是匹配大小写字母和数字之外的其他任意字符或符号,如 a\Wc 可以匹配 a.c 、a#c 、a+c 等
python 函数 def
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。

python模糊匹配和 str find
代码:
a = ['123','666','355']
b = ['2','5']
for i in range(len(b)):
for j in range(len(a)):
if a[j].find(b[i]) == -1:
continue
print(a[j])
FuzzyWuzzy 模糊匹配工具
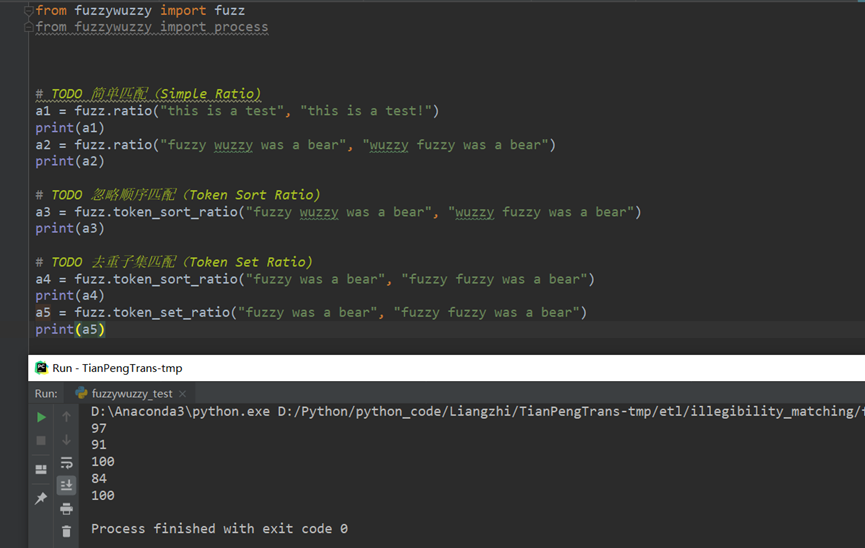
Crawler 爬虫
1.翻页问题
math.floor()方法 注意返回的是浮点数
import math
f = 11.2
print math.ceil(f) #向上取整
print math.floor(f) #向下取整
print round(f) #四舍五入
这三个函数的返回结果都是浮点型
p.s. list转成str字符串的办法 list后面加[0]
2.网页不响应问题:访问页面过于频繁,抓取第一步的时候返回就为空
for循环返回空的时候会直接跳出for循环

解决方法:
使用time.sleep方法 t -- 推迟执行的秒数,该函数没有返回值。
Python time sleep() 函数推迟调用线程的运行,可通过参数secs指秒数,表示进程挂起的时间。
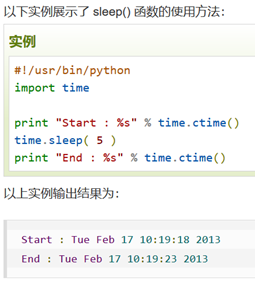
3.document.cookie 获取cookie
document.cookie的搜索方式 浏览器控制台中搜索
4.验证码判断
5.i = soup.find_all(name=’div’, attrs={‘class’: ‘c-span21 c-span-last op-ip-detail’})[0][0]的意思是??????
6.第一行,第二行的结果和第五行的结果相同, 如下图

7.指定编码格式
指定网站的编码格式 charset 字符集 从网站head里面获取
每次页面请求的时候都要设置一遍编码:
url = 'http://www.cnena.com/huiyi/'
r = requests.get(url, headers=headers)
r.encoding = 'gb2312'
soup = BeautifulSoup(r.text, 'html.parser')
8.自动更新cookie (总共三个方法)
https://www.jb51.net/article/135952.htm
https://blog.csdn.net/qq_42750240/article/details/89597936
Postman 测试第一个大类
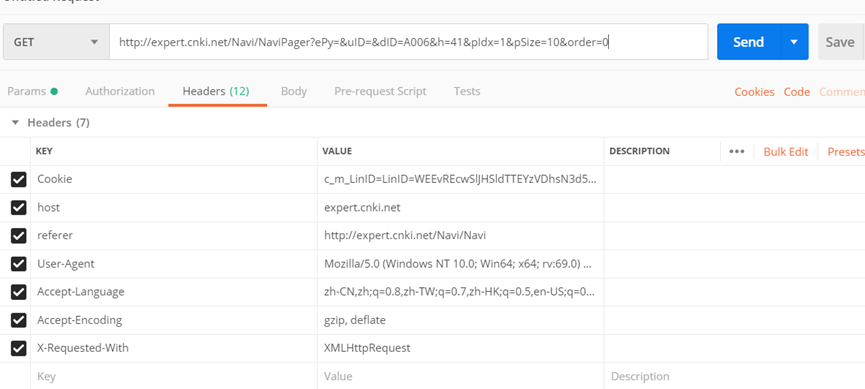
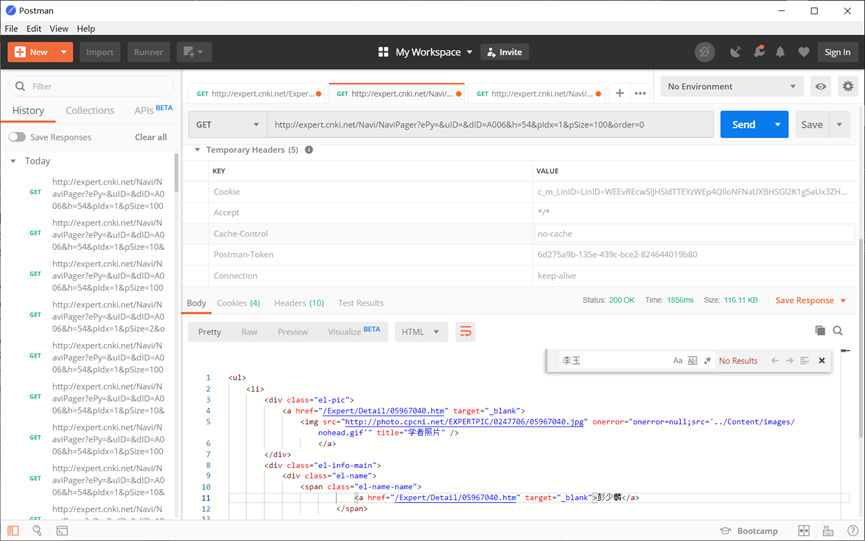
网址模板:http://expert.cnki.net/Navi/NaviPager?ePy=&uID=&dID=A006&pIdx=0&pSize=1000&order=0
9.直接获取cookie【request post模拟登录后获取cookie】 it桔子举例:
获取与拼接cookie方法:
r = requests.post(url=url, data=datas, heaers=headers)
结果:

10.自动查询网站编码方式
import chardet
import urllib
可根据需要,选择不同的数据
TestData=urllib.urlopen('http://www.baidu.com').read()
print chardet.detect(TestData)
confidence代表匹配度
11.智能化爬虫总汇
https://cuiqingcai.com/6454.html
• Diffbot,国外的一家专门来做智能化解析服务的公司,https://www.diffbot.com
• Boilerpipe,Java 语言编写的一个页面解析算法,https://github.com/kohlschutter/boilerpipe
• Embedly,提供页面解析服务的公司,https://embed.ly/extract
• Readability,是一个页面解析算法,但现在官方的服务已经关闭了,https://www.readability.com/
• Mercury,Readability 的替代品,https://mercury.postlight.com/
• Goose,Java 语音编写的页面解析算法,https://github.com/GravityLabs/goose
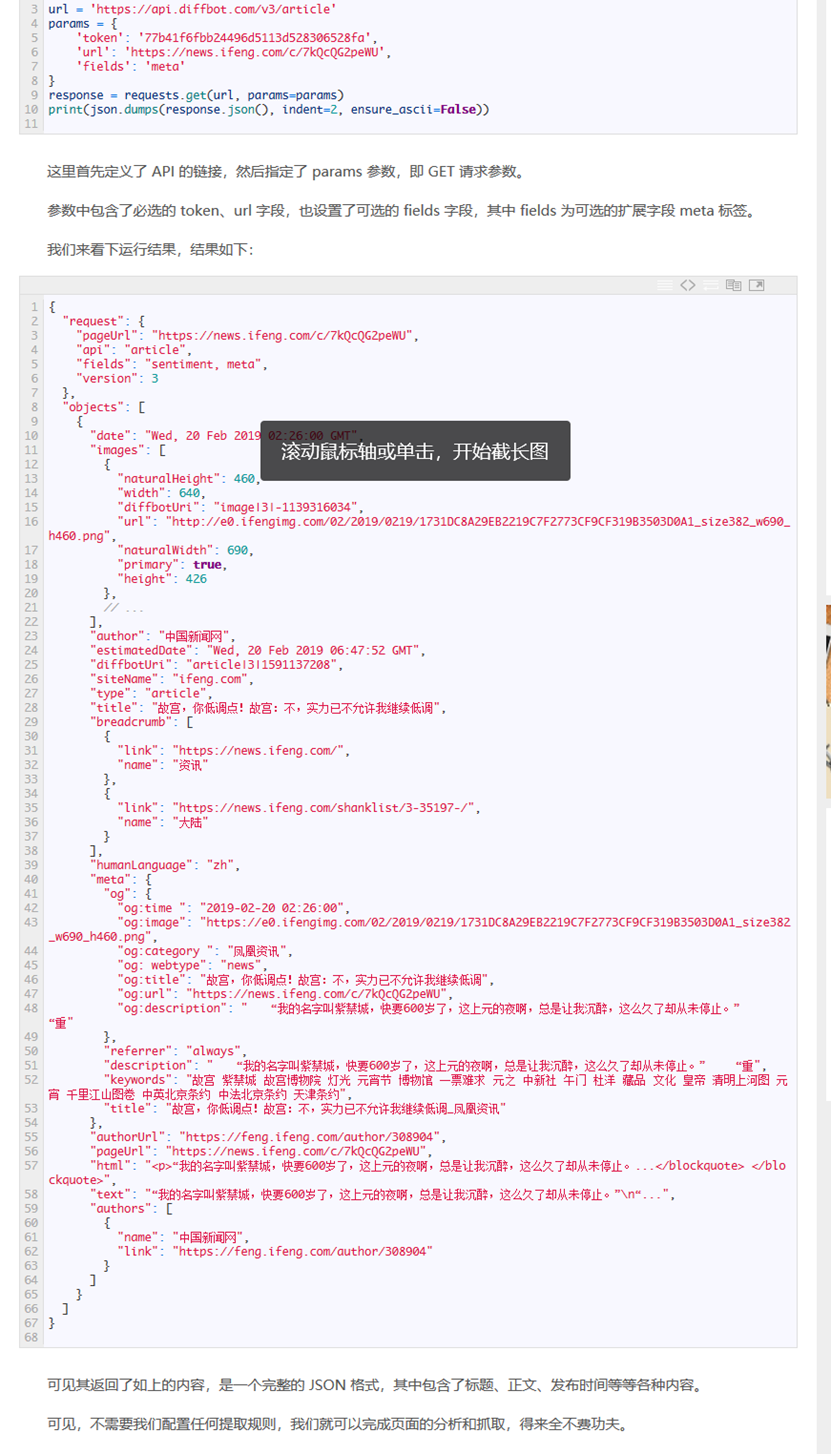
12.乱码问题总汇
Python requests请求页面返回乱码问题
序言
有时候在通过Python爬取网页数据的时候,比如抖音、快手等短视频数据;网页会返回乱码;这种乱码数据,不管是gb2312、utf-8、gbk、亦或者使用gbk的超集gb18030等编码都毫无用处。看下图。
原因出在一个参数上 ‘accept-encoding’: ‘gzip, deflate, br’
gzip是一种数据格式;默认且目前仅使用deflate算法压缩data部分,这种方法常用于压缩传输。
普通浏览器在访问网页时,之所以要添加 ‘accept-encoding’: ‘gzip, deflate, br’ ;是因为,浏览器对于从服务器中返回的对应的gzip压缩的网页,会自动解压缩,所以,在requests的时候,添加对应的请求头,来表明自己接收压缩后的数据。
而在上面的代码中,如果也添加此头的信息,结果就是,返回的是压缩后的数据,没有解码,直接将压缩后的数据当做普通的html文本来处理,所以显示出来的内容,就是乱码了。(看到这里是不是有种恍然大悟😄)
如果还不理解再直白点:就是服务器数据返回给客户端时候已经被gzip压缩了,而你的程序里面没有自动解压而已。 解决方案
1、注释掉 ;
2、可以弄个解压算法把乱码的数据进行解压,即可得到正常的HTML返回结果。
lxml 的使用
1.lxml介绍
https://www.cnblogs.com/zhangxinqi/p/9210211.html
https://www.cnblogs.com/zhangxinqi/p/9210211.html#_label5
2.Etree的使用
from scrapy import Selector
from lxml import html
etree = html.etree
‘body’是大标签

3.lxml中etree.html和etree.parse的区别
etree.parse直接接受一个文档,按照文档结构zd解析
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml')
root = tree.getroot()
etree.html可以解析html文件:
page = etree.HTML(html.lower().decode('utf-8'))
hrefs = page.xpath(u"//a")
for href in hrefs:
print href.attrib
理解continue和break
Python continue 语句跳出本次循环,而break跳出整个循环。
continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
continue语句用在while和for循环中
break:跳出当前循环体,也称结束当前循环体
continue:跳出此次循环,继续执行下一次循环
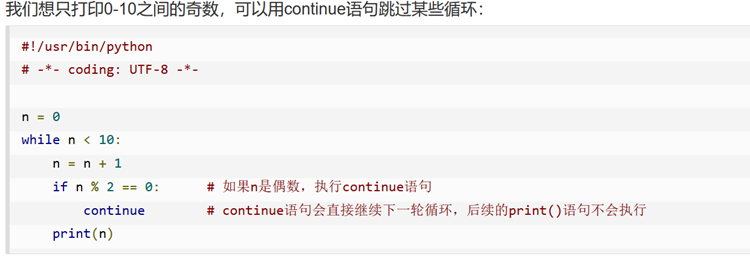
函数封装与调用 代码规范
https://www.cnblogs.com/chownjy/p/8663024.html
https://www.cnblogs.com/EEEE1/p/9352984.html
1.1self概念
1.2init__概念
1.3class类
1.4def函数
1.5if __name == ‘main’:
在定义方法的时候有一个self参数,这个参数代表实例对象本身。
首先明确的是self只有在类的方法中才会有,独立的函数或方法是不必带有self的。self在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
Self名称不是必须的,在python中self不是关键词,你可以定义成a或b或其它名字都可以,但是约定成俗(为了和其他编程语言统一,减少理解难度),不要搞另类,大家会不明白的。
1)class类包含:
类的属性:类中所涉及的变量
类的方法:类中函数
2)_init_函数(方法)
1.首先说一下,带有两个下划线开头的函数是声明该属性为私有,不能在类地外部被使用或直接访问。
2.init函数(方法)支持带参数的类的初始化 ,也可为声明该类的属性
3.init函数(方法)的第一个参数必须是 self(self为习惯用法,也可以用别的名字),后续参数则可 以自由指定,和定义函数没有任何区别。
3)函数定义
Python编程中对于某些需要重复调用的程序,可以使用函数进行定义,基本形式为:
def 函数名(参数1, 参数2, ……, 参数N)
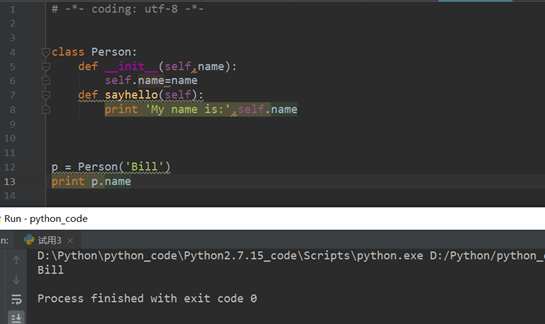
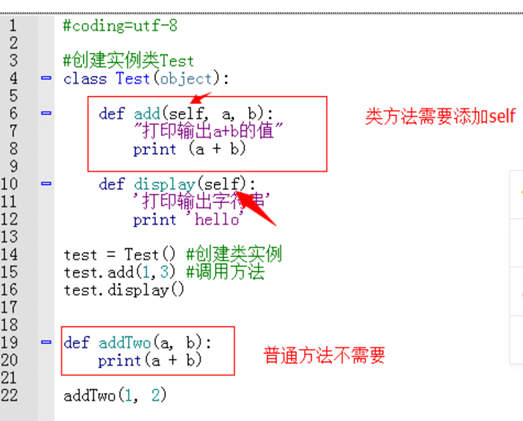
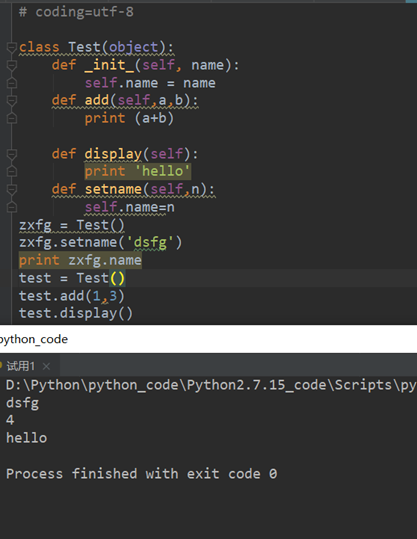
p.s重要快捷键delete:删除整行 control+r 替换和替换全部
p.s.python中alt按住可以选择多个字段 行 列等
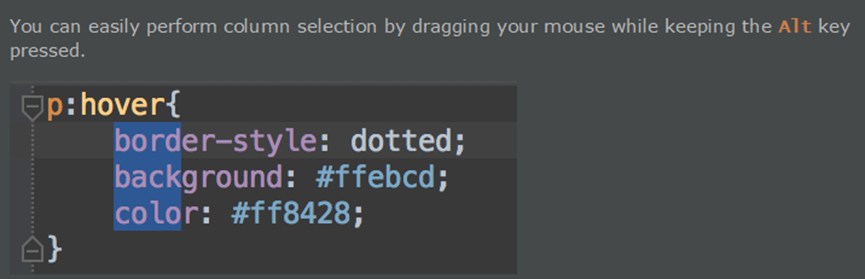
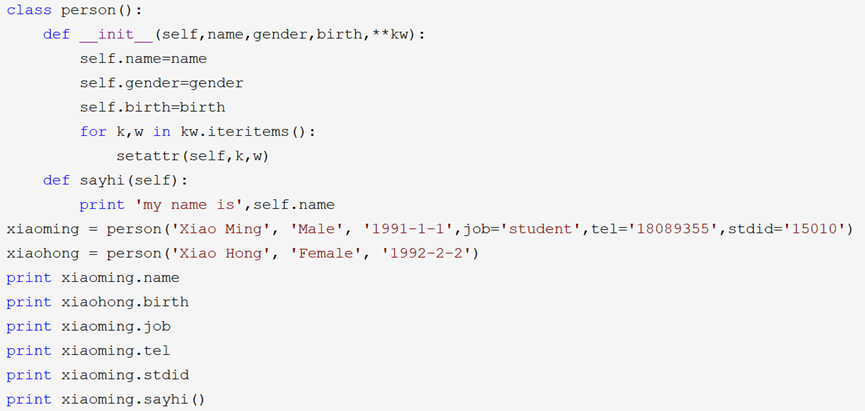
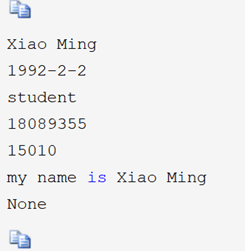
1.问题一:参数的传导(按着执行顺序来,就不会标红)
2.问题二:def函数 方法的命名规范 一般加”get”等
3.问题三:if name == ‘main’: 怎么理解
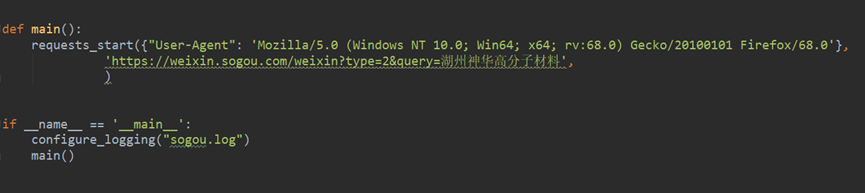
在大多数编排得好一点的脚本或者程序里面都有这段if name == ‘main’:
这段代码的功能
一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行。因此if __name__ == 'main': 的作用就是控制这两种情况执行代码的过程,在if __name__ == 'main': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的。
举个例子,下面在test.py中写入如下代码:
print "I'm the first."
if __name__=="__main__":
print "I'm the second."
并直接执行test.py,结果如下图,可以成功print两行字符串。即,if __name__=="__main__": 语句之前和之后的代码都被执行。
然后在同一文件夹新建名称为import_test.py的脚本,只输入如代码:
import test
执行import_test.py脚本,输出结果如下:
if __name__=="__main__":
只输出了第一行字符串。即,if __name__=="__main__": 之前的语句被执行,之后的没有被执行。
运行的原理
每个python模块(python文件,也就是此处的test.py和import_test.py)都包含内置的变量__name__,当运行模块被执行的时候,__name__等于文件名(包含了后缀.py);如果import到其他模块中,则__name__等于模块名称(不包含后缀.py)。而"__main__"等于当前执行文件的名称(包含了后缀.py)。进而当模块被直接执行时,__name__ == 'main'结果为真。
同样举例说明,我们在test.py脚本的if __name__=="__main__":之前加入print __name__,即将__name__打印出来。文件内容和结果如下,
pythonèæ¬
可以看出,此时变量__name__的值为"__main__";
再执行import_test.py,模块内容和执行结果如下:
__name__åé
此时,test.py中的__name__变量值为test,不满足__name__=="__main__"的条件,因此,无法执行其后的代码。
规范代码def 中参数的设置 方便以后修改函数

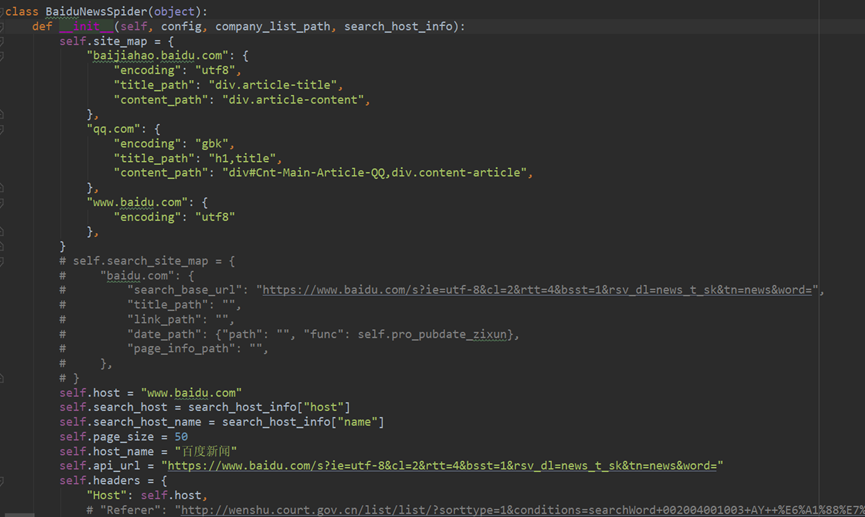
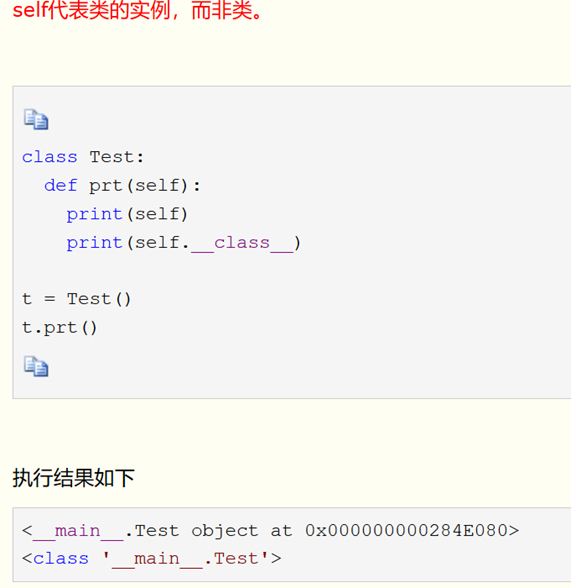
Log日志配置,将log输出到日志
1.Log基础
https://www.cnblogs.com/nancyzhu/p/8551506.html
日志是跟踪软件运行时所发生的事件的一种方法。软件开发者在代码中调用日志函数,表明发生了特定的事件。事件由描述性消息描述,该描述性消息可以可选地包含可变数据(即,对于事件的每次出现都潜在地不同的数据)。事件还具有开发者归因于事件的重要性;重要性也可以称为级别或严重性。
logging提供了一组便利的函数,用来做简单的日志。它们是 debug()、 info()、 warning()、 error() 和 critical()。
需求:
输出log到控制台以及将日志写入log文件。
保存2种类型的log, all.log 保存debug, info, warning, critical 信息, error.log则只保存error信息,同时按照时间自动分割日志文件。

'r'表示打开文件只读,不能写。
'w'表示打开文件只写,并且清空文件。
'x'表示独占打开文件,如果文件已经存打开就会失败。
'a'表示打开文件写,不清空文件,在文件后尾追加的方式写入。
'b'表示二进制的模式打开文件。
't'表示文本模式,默认情况下就是这种模式。
'+'打开文件更新(读取或写入)
https://www.cnblogs.com/yx12138/p/10849041.html
注意事项:
在应用日志时,如果想要保留异常的堆栈信息。
import logging
import requests
logging.basicConfig(
filename='wf.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=logging.ERROR
)
try:
requests.get('http://www.xxx.com')
except Exception as e:
msg = str(e) # 调用e.__str__方法
logging.error(msg,exc_info=True)
2.log输出格式
这里修改log的输出格式

ip代理的使用
https://www.cnblogs.com/dengsm/p/6213998.html
import random
ip_pool = [
'xxxx:0000',
'xxxx:0000',
'xxxx:0000',]
def ip_proxy():
ip = ip_pool[random.randrange(0,3)]
proxy_ip = 'http://'+ip
proxies = {'http':proxy_ip}
return proxies
print(ip_proxy())
换种方法:用上公司的代理ip后报错 如下
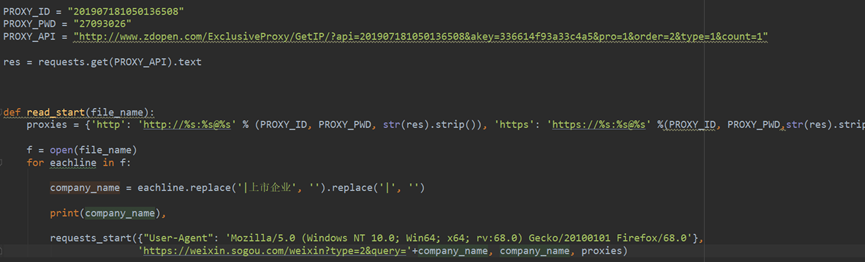
抛出 requests.exceptions.ConnectionError 未知的服务器 requests.exceptions.ProxyError: HTTPSConnectionPool(host=’weixin.sogou.com’, port=443): Max retries exceeded with url: /weixin?type=2&query=%EF%BB%BF%E6%AC%A7%E8%AF%97%E6%BC%AB%E7%94%9F%E7%89%A9%0A&page=2 (Caused by ProxyError(‘Cannot connect to proxy.’, NewConnectionError(‘<urllib3.connection.VerifiedHTTPSConnection object at 0x000000000608BDD8>: Failed to establish a new connection: [Errno 10060] ‘,)))
ip代理代码回顾

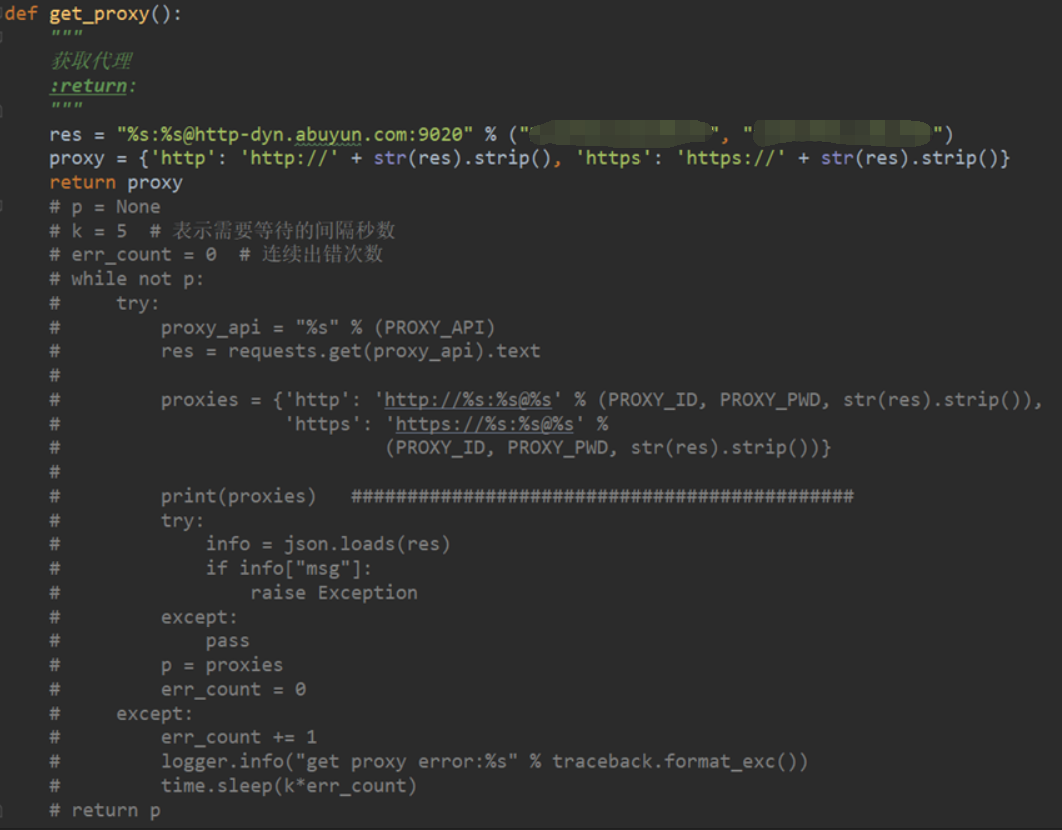
循环读取文件的每一行(两种比较重要的方法)
方法1:
f = open("E:/b.xxxxxxxxx_file/top100_company_list.txt") # 返回一个文件对象
line = f.readline() # 调用文件的 readline()方法
while line:
print line, # 后面跟 ',' 将忽略换行符
print 1
# print(line, end = '') # 在 Python 3中使用
line = f.readline()
f.close()
方法2:
f = open('E:/b.xxxxxxxxx_file/top100_company_list.txt')
for eachline in f:
print(eachline),
print 1
待改进代码(我的):
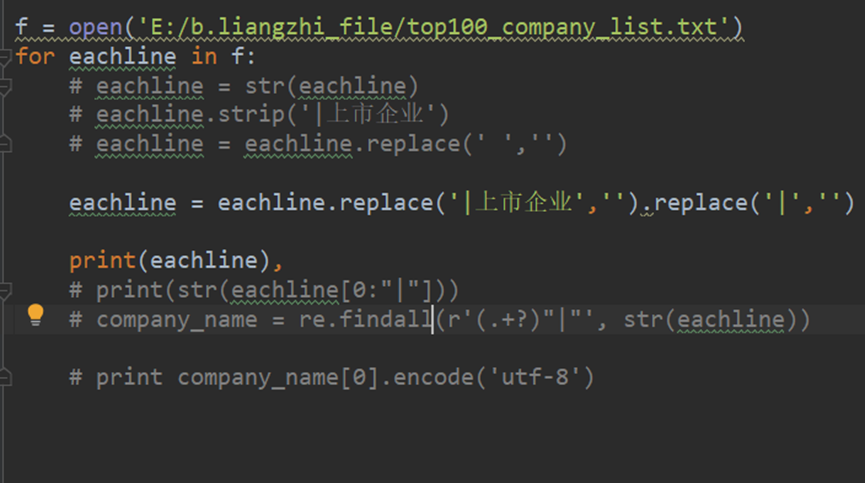
改进后的代码:
replace的用法
a.replace(“123”,””).replace(“t”,””).replace(“hfhf”,””) 单引号双引号都可以
注意def()函数,参数的传入顺序

如果是写了参数xx=xx, 顺序就无所谓了
Pycharm 软件基础操作
1.重新格式化代码的使用
2.打印字体的颜色
print("\033[1;33;0m"+MyPredict+"\033[0m")
结果:

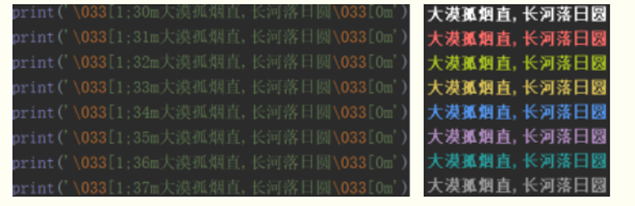
3.Pycharm中 python console转换编码的用法
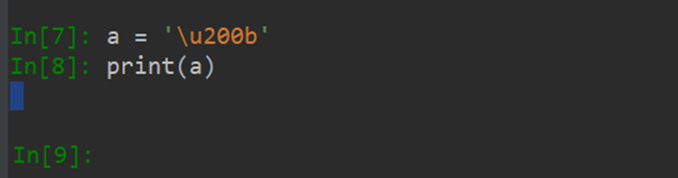
4.Pycharm 一键加引号,快速加引号,批量加引号
https://blog.csdn.net/wang_hugh/article/details/81043852

然后选中
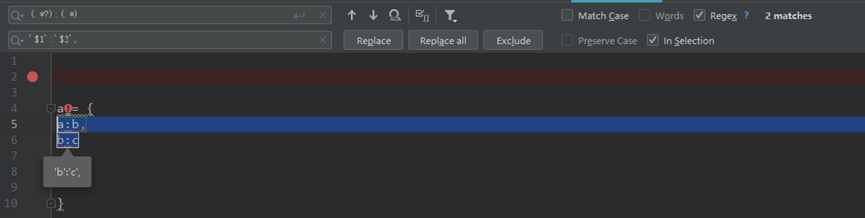
最后点replace all
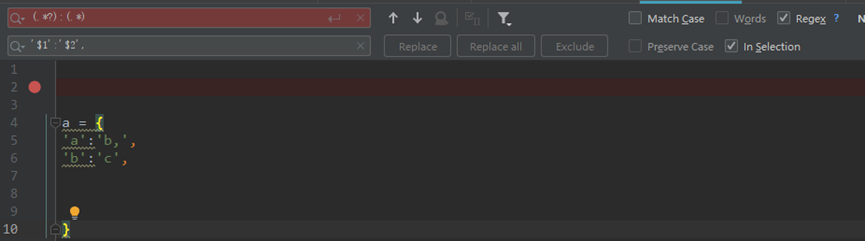
5.Pycharm 步入 步过
F8步过的时候会直接返回函数的结果,而不会进入到函数中。 F7步入的时候,如果遇到函数,会自动进入到函数体内部。
说明:
• Step Over:在单步执行时,在函数内遇到子函数时不会进入子函数内单步执行,而是将子函数整个执行完再停止,也就是把子函数整个作为一步。有一点,经过我们简单的调试,在不存在子函数的情况下是和Step Into效果一样的(简而言之,越过子函数,但子函数会执行)。
• Step Into:单步执行,遇到子函数就进入并且继续单步执行(简而言之,进入子函数)。
• Step Into My Code:进入自己编写的函数,不进入系统函数,很少用到。
• Force Step Into:强制进入,在调试的时候能进入任何方法。
• Step Out:当单步执行到子函数内时,用Step Out就可以执行完子函数余下部分,并返回到上一层函数。
• Run to Cursor:一直执行,到光标处停止,用在循环内部时,点击一次就执行一个循环。
6.# TODO 解释
在 PyCharm 中,使用 Alt + 6 快捷键,可快速调出项目中的全部 TODO 注释;
7.pycharm中python console控制台中输入函数 执行函数 和循环等
def split_text(text, length):
word_list = []
each_word_list = list(text)
len_each_word_list = len(each_word_list)
for num, i in enumerate(each_word_list):
if num + length <= len_each_word_list:
word_list.append(''.join(each_word_list[num:num + length]))
# print(each_word_list[num:num+length])
return word_list
for split_length in range(2, 9):
word_list = split_text('我们去打猎', split_length)
print(word_list)
['我们', '们去', '去打', '打猎']
['我们去', '们去打', '去打猎']
['我们去打', '们去打猎']
['我们去打猎']
[]
[]
[]
8.Pycharm中用正则匹配出ip地址
import re
string_ip = ''
result = re.findall(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b", string_ip)
# 正则表达式
# \b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b
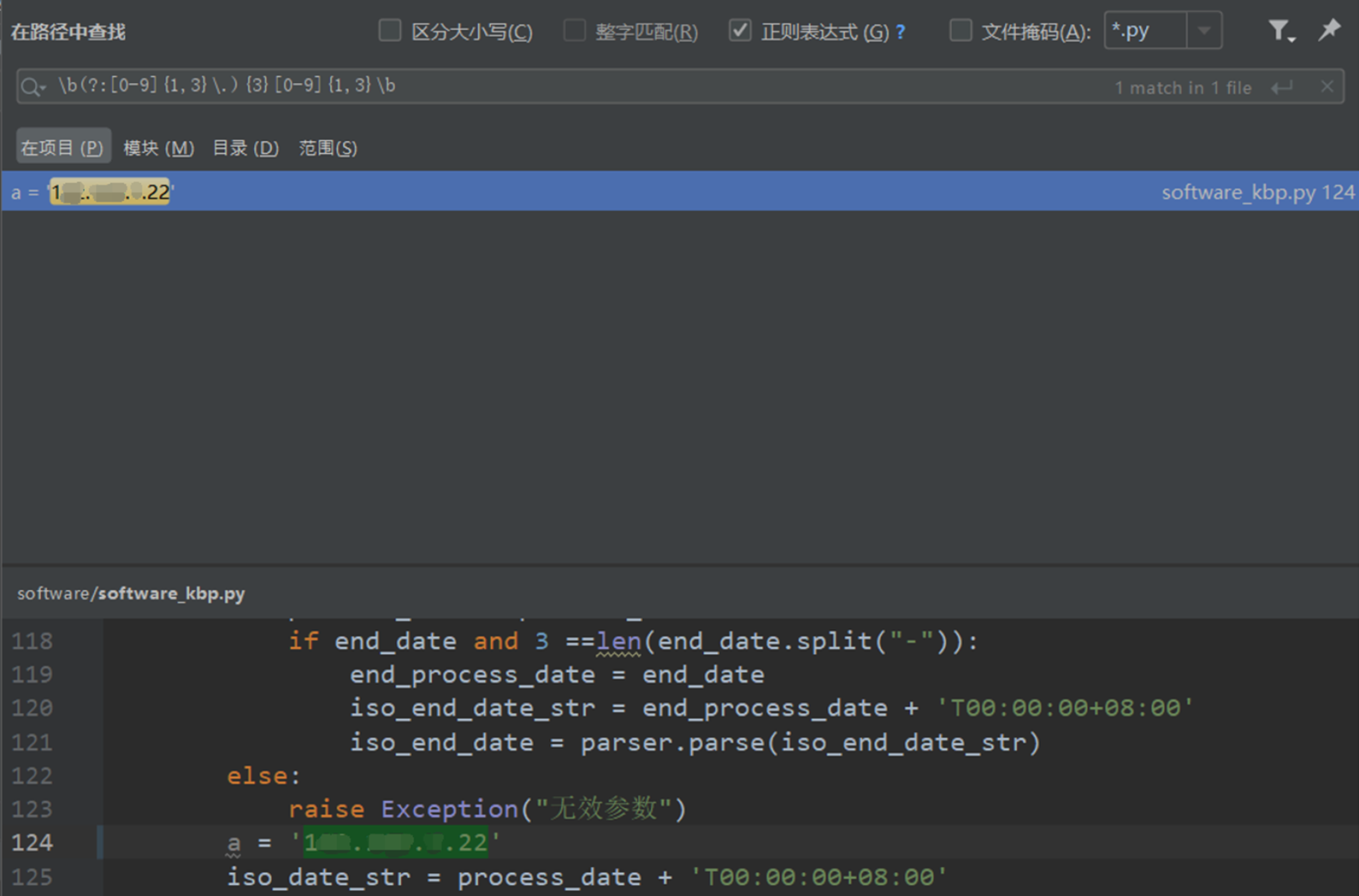
9.Pycharm 监视器用法
运行到一个变量的时候,变量出现后设置断点,例如soup,然后在监视里输入相关的soup语法直接调试
VSCode 软件基础操作
1.SFTP 安装和使用
2.markdown 相关插件安装
https://blog.csdn.net/pxyp123/article/details/124331401
3.更新代码到github
url_img的抓取
去掉首尾字符串和图片的抓取
我的代码,待改进:
改进后:
Return 相关操作
1.return 返回空值的用法
return空值 直接写return就好了
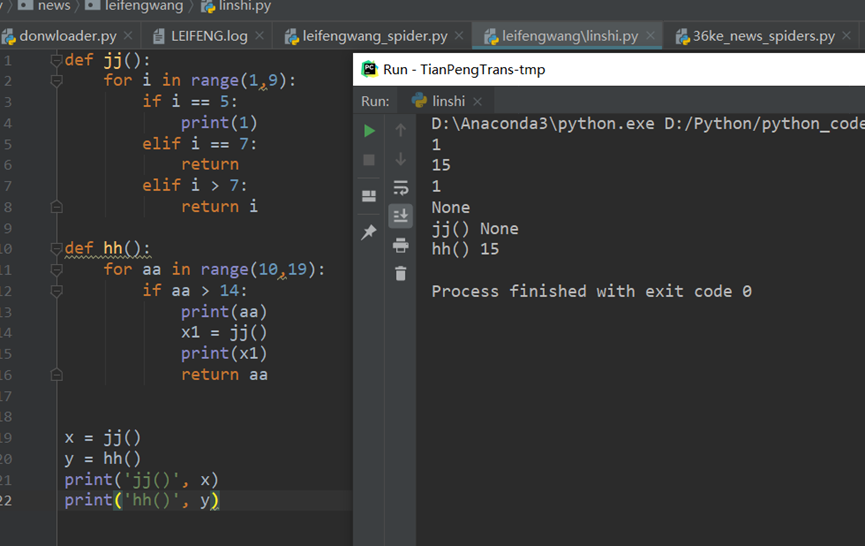
2.return报错 TypeError:’NoneType’ object is not iterable
https://blog.csdn.net/qq_42780289/article/details/96971940
解决办法:
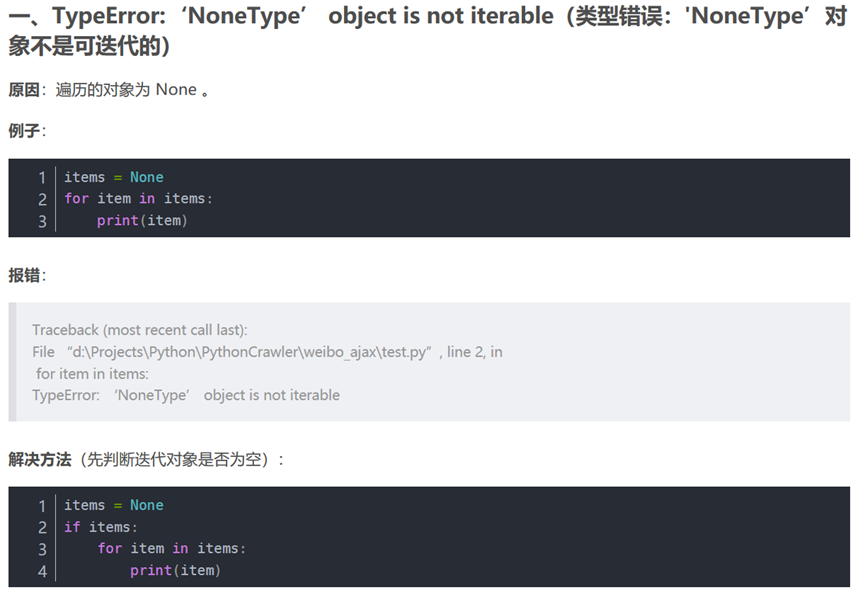


怎么理解 return 和 continue
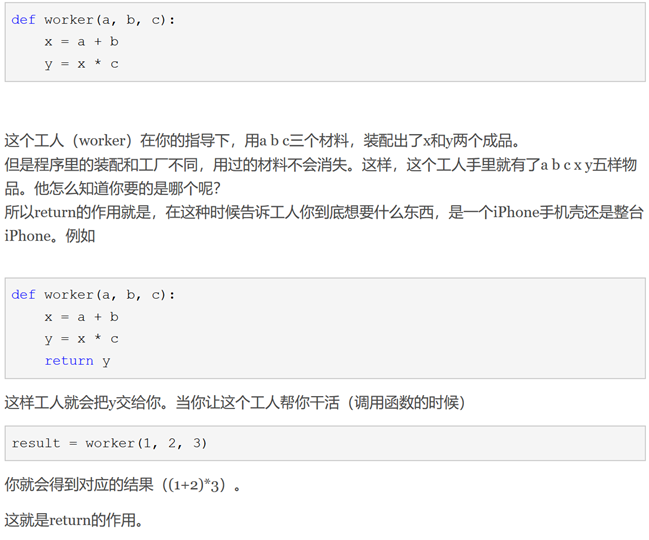
http://c.biancheng.net/view/4491.html
Python中,用 def 语句创建函数时,可以用 return 语句指定应该返回的值,该返回值可以是任意类型。需要注意的是,return 语句在同一函数中可以出现多次,但只要有一个得到执行,就会直接结束函数的执行。
函数中,使用 return 语句的语法格式如下:
return [返回值]
其中,返回值参数可以指定,也可以省略不写(将返回空值 None)。
【例 1】
def add(a,b):
c = a + b
return c
#函数赋值给变量
c = add(3,4)
print(c)
#函数返回值作为其他函数的实际参数
print(add(3,4))
运行结果为:
7
7
本例中,add() 函数既可以用来计算两个数的和,也可以连接两个字符串,它会返回计算的结果。
通过 return 语句指定返回值后,我们在调用函数时,既可以将该函数赋值给一个变量,用变量保存函数的返回值,也可以将函数再作为某个函数的实际参数。
【例 2】
def isGreater0(x):
if x > 0:
return True
else:
return False
print(isGreater0(5))
print(isGreater0(0))
运行结果为:
True
False
return引申:全局变量和局部变量
局部变量是只能再函数或代码段内使用的变量。函数或代码段一旦结束,局部变量的生命周期也就结束。局部变量的作用范围只在其被创建的函数范围内有效。

def里面的count是一个局部变量(上图)。在function函数中将crawler函数赋值给变量count,此时count相对与crawler函数来讲是个全局变量(下图)。
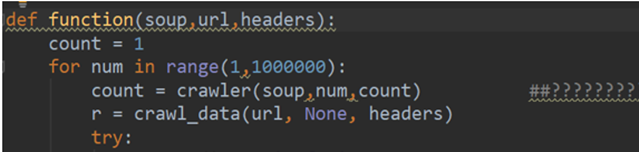
全局变量是能够被不同的函数、类或文件共享的变量,在函数之外定义的变量都可以被称为全局变量。全局变量可以被文件内部的任何函数和外部文件访问。
python执行顺序(接上面的)
count = crawler(soup,num,count) 先执行crawler函数,(然后执行运算加减乘除),然后赋值给count变量。
traceback
https://www.jianshu.com/p/01ed4b8d7d9a
1.traceback.print_exc()
2.traceback.format_exc()
3.traceback.print_exception()
4.print_exc():是对异常栈输出
5.format_exc():是把异常栈以字符串的形式返回,print(traceback.format_exc()) 就相当于traceback.print_exc()
6.print_exception():traceback.print_exc()实现方式就是traceback.print_exception(sys.exc_info()),可以点sys.exc_info()进去看看实现
验证码识别
https://blog.csdn.net/qq_39620871/article/details/80732521
selenium 和 Webdriver
from selenium import webdriver
selenium[səˈliːniəm]
1.安装
安装chromedriver.exe 插件 python通过控制chrome浏览的插件来控制浏览器。下载地址:http://chromedriver.storage.googleapis.com/index.html
爬取搜狗微信top100公司的时候 本地遇到ip正常,然后出现爬取时验证码,但是本地浏览器仍旧可以打开搜狗微信搜索结果页面的情况。
https://blog.csdn.net/yx_ming/article/details/81916491
2.介绍
Selenium是一个浏览器自动化操作框架。selenium主要由三种工具组成。
2.1.第一个工具——SeleniumIDE,是Firefox的扩展插件,支持用户录制和回访测试。录制/回访模式存在局限性,对许多用户来说并不适合。
2.2.因此第二个工具——Selenium WebDriver提供了各种语言环境的API来支持更多控制权和编写符合标准软件开发实践的应用程序。
2.3.最后一个工具——SeleniumGrid帮助工程师使用Selenium API控制分布在一系列机器上的浏览器实例,支持并发运行更多测试。
在项目内部,它们分别被称为”IDE”、”WebDriver”和”Grid”。
问题反馈:一个用webdriver访问次数过多会出现需要扫描二维码进行访问的情况
pip install selenium
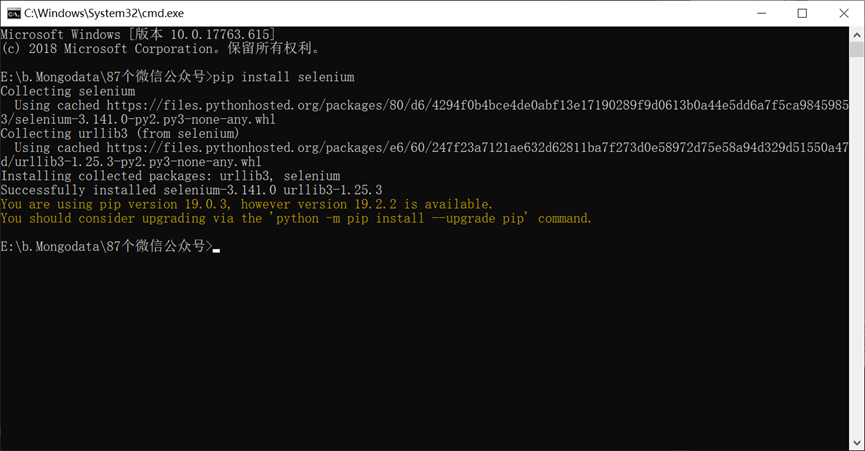
3.webdriver
https://blog.csdn.net/qq_39481696/article/details/82882186
官网上是这么介绍它的:
WebDriver is a clean, fast framework for automated testing of webapps.(WebDriver是一个干净、快速的web应用自动测试框架。)
from selenium import webdriver
browser = webdriver.chrome(web)
browser.get(address)
soup = BeautifulSoup(browser.page_source, 'html.parser')
Webdriver 的使用
1.webdriver 定位方法 https://www.cnblogs.com/yoyoketang/p/6557421.html
1.id定位:find_element_by_id(self, id_)
2.name定位:find_element_by_name(self, name)
3.class定位:find_element_by_class_name(self, name)
4.tag定位:find_element_by_tag_name(self, name)
5.link定位:find_element_by_link_text(self, link_text)
6.partial_link定位find_element_by_partial_link_text(self, link_text)
7.xpath定位:find_element_by_xpath(self, xpath)
8.css定位:find_element_by_css_selector(self, css_selector)
2.webdriver碰到网页未响应 https://blog.csdn.net/weixin_41624982/article/details/89048936
首先需要区分两种超时情况,一种是页面加载出现的超时,一种是获取页面元素的超时。
对于页面加载出现的超时,Selenium提供了两个设置:
driver.set_page_load_timeout() # 设置页面加载超时
driver.set_script_timeout() # 设置页面异步js执行超时
set_page_load_timeout是用于设置页面加载超时,如下图在指定时间内未加载出页面则会报错。
如下图:
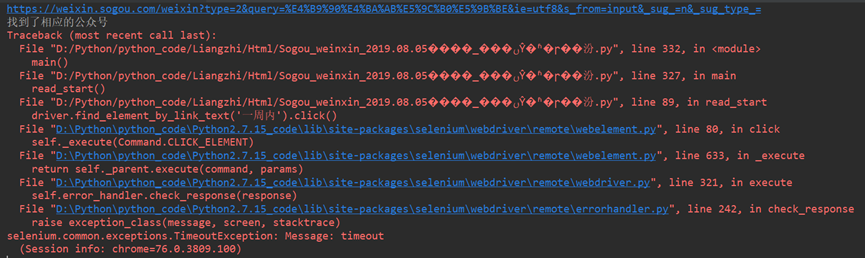
https://blog.csdn.net/Wuli_SmBug/article/details/82053372
webdriver 的三种等待方式(强制等待、隐式等待、显示等待) 显示等待与隐式等待相对,显示等待必须在每个需要等待的元素前面进行声明。
引入WebDriverWait from selenium.webdriver.support.ui import WebDriverWait
引入expected_conditions类,并重命名为EC from selenium.webdriver.support import expected_conditions as EC
引入By类 from selenium.webdriver.common.by import By
设置等待 wait = WebDriverWait(driver,10,0.5) wait.until(EC.presence_of_element_located((By.ID,’KW’)))
显示等待需要用到两个类:
WebDriverWait和expected_conditions两个类。
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver:浏览器驱动
timeout:最长超时时间,默认以秒为单位
poll_frequency:检测的间隔步长,默认为0.5s
ignored_exceptions:超时后的抛出的异常信息,默认抛出NoSuchElementExeception异常
4.webdriver获取当前网页网址 print(driver.current_url)
webdriver 网页的前进、后退
https://www.cnblogs.com/qingqing-919/p/8709064.html
driver.get("http://wenku.baidu.com") #输入网址
driver.back() #向后退
driver.forward() #向前进
driver.refresh() #刷新页面
设置超时等待的时间,超过不再等待
driver.set_page_load_timeout(2) #设置超时等待的时间,超过不再等待
5.webdriver通过browser.page_source得到网页源代码,再进行xpath提取
def danwei2():
browser = webdriver.Ie(r'D:\driver\IEDriverServer.exe')
# browser = webdriver.Firefox(r'D:\driver\geckodriver')
# browser = webdriver.Chrome(r'D:\driver\chromedriver.exe')
# browser = webdriver.PhantomJS(r'D:\phantomjs-2.1.1-windows\bin\phantomjs')
url = 'http://search.gjsy.gov.cn:9090/queryAll/listFrame2?page=2&districtCode=130300&checkYear=2017&sydwName=&selectPage=0'
browser.get(url)
time.sleep(0.5)
print(browser.page_source) #打印源码
res = browser.page_source #page_source页面源代码
rs1 = etree.HTML(res) # 是将HTML转化为二进制/html 格式
num = rs1.xpath('//*[@id="searchForm"]/table/tbody/tr/td/table/tbody/tr[2]/td/table/tbody/tr[9]/td/table/tbody/tr[2]/td/table/tbody/tr[2]/td[2]/a/text()')
unit = rs1.xpath('//*[@id="searchForm"]/table/tbody/tr/td/table/tbody/tr[2]/td/table/tbody/tr[9]/td/table/tbody/tr[2]/td/table/tbody/tr[2]/td[3]/a/text()')
print(num)
print(unit)
6.完整代码
webdriver的使用 https://www.jianshu.com/p/adddf2c77d4e
from selenium import webdriver
from selenium.webdriver.support.select import Select
import time
# 打开浏览器,同时打开首页
url = 'https://jc-lab.yscredit.com/'
driver = webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
# driver = webdriver.Chrome()
driver.get(url)
# 通过js改密码登录
js = "document.getElementById('zhanghaoLogin').style.display='block'"
js2 = "document.getElementById('mobileLogin').style.display='none'"
driver.execute_script(js)
driver.execute_script(js2)
# 通过id定位搜索框,同时输入登录用户名密码
driver.find_element_by_id('username').clear()
# xxx是账号和密码
driver.find_element_by_id('username').send_keys('xxx')
driver.find_element_by_id('password').clear()
driver.find_element_by_id('password').send_keys('xxx')
driver.find_element_by_id('login_btn').click()
time.sleep(3)
#进入首页搜索
driver.find_element_by_id('queryInput').send_keys('西藏家家乐购信息技术股份有限公司')
driver.find_element_by_class_name('query-button').click()
print("cccccccccccc")
time.sleep(2)
#点击企业名
#driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[3]/div[1]/div[2]/div/span[2]/div[1]/span[1]').click()
driver.find_element_by_css_selector(' body > div.jc-header-and-main2 > div.monitor-content-container > div > div.main-content-right-container > div.monitor-right-section > div:nth-child(2) > div > span:nth-child(2) > div.list-title > span.company-title.pointer.ng-binding').click()
#company-title pointer ng-binding
#company-title.pointer.ng-binding
print("aaaaaaaaaaaaa")
time.sleep(3)
print("bbbbbbbbbbbbb")
cookies = driver.get_cookies()
print(cookies)
handle = driver.current_window_handle
handles = driver.window_handles
for i in handles:
# driver.switch_to.window(i)
# break
print(i)
print(handle)
#if i == handle:
driver.switch_to.window(i)
driver.find_element_by_id('opinionMsg').click()
time.sleep(3)
driver.find_element_by_css_selector('div#opinionMsgNewsdiv div.rel.time-range').click()
time.sleep(2)
driver.find_element_by_css_selector('div#opinionMsgNewsdiv ul.dropdown-menu.change-list-all li:nth-of-type(1) a').click()
# time.sleep(5)
# driver.quit()
7.webdriver 识别验证码 https://www.cnblogs.com/landhu/p/4968577.html
8.webdriver 开发者模式
开始屏蔽selenium,防止被各大网站识别出来,设置开发者模式https://www.cnblogs.com/cloudbird/p/10524242.html
9.下一页的元素是li这一行去定位
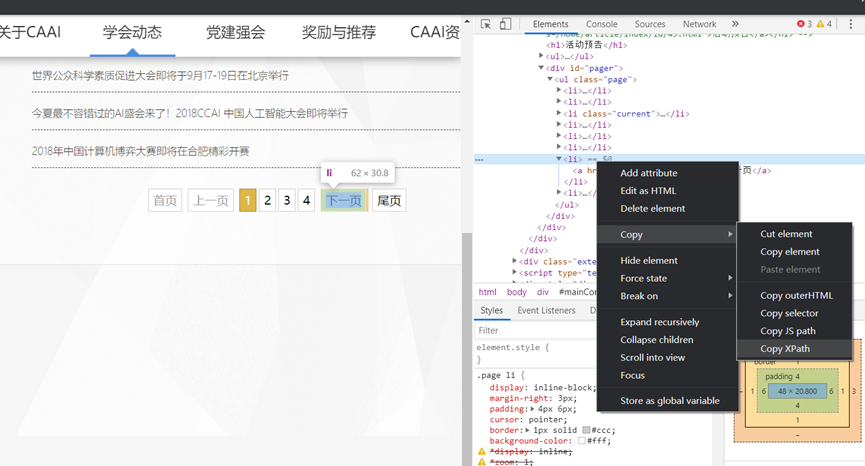
10.webdriver句柄切换
handle = driver.current_window_handle #获取当前窗口句柄
handles = driver.window_handles #获取所有窗口句柄
切换句柄可以使用
?
1
dr.switch_to.window(handle) #其中handle为获取到的窗口句柄
假设handles为获取到的所有窗口,则handles为一个list,可使用访问list的方法读取句柄。
?
1
2
dr.switch_to.window(handles[0]) #切换到第一个窗口的句柄
dr.switch_to.window(handles[-1]) #切换到最新窗口的句柄
11.webdriver 滚动条控制
https://blog.csdn.net/legend818/article/details/90543438
selenium中没有直接控制滚动条的方法,可以使用方法:execute_script(),可以直接执行js的脚本。
代码:
js = "window.scrollTo(0,document.body.scrollHeight)"
self.driver.execute_script(js)
time.sleep(2)

竖向滚动条控制,三种方法总有一款适合你。
1.滚动条拉到最底:
js="var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)
2.滚动条拉到最底:
js="var q=document.getElementById('id').scrollTop=10000"
driver.execute_script(js)
这里的id为滚动条的id,滚动条没有id的网页此方法不适用。
3.滚动条拉到最底:
js = "var q=document.body.scrollTop=10000"
driver.execute_script(js)
可以修改scrollTop 的值来定位右侧滚动条的位置,0是最最顶部,10000是最底部。
在百度中搜索selenium,拖动滚动条至最底端:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
# 搜索 selenium
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
# 等待元素可见
WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.XPATH,'//*[@id="5"]/h3/a')))
# 将滚动条下拉至最低
js="var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)
12.webdriver 关闭浏览器弹窗 安装pykeyboard
https://www.cnblogs.com/Simple-Small/p/12486621.html
编码问题
1.问题一:
https://mp.weixin.qq.com/s?src=11×tamp=1565751612&ver=1789&signature=fA4pma6G7yfdtJri-vXYcVZaUbBZ2mrrQx-q6rPpLSJlVNYU0BJvU9sUnXUQvEpfvKmCYToIQ99AUSH923oXwEcharLeXfmTT0ir0svjtfKjKmkDvhCqWxEyUuID&new=1

2.error ‘NoneType’ object has no attribute ‘encoding’
原因:取到空值,空值是不能encoding的
null一般是指对象为空,即obj = null; 空值一般是指对象的参数值为空字符串,例obj.value=’’;
3.设置默认编码格式
reload(sys)
sys.setdefaultencoding(‘utf8’)
递归函数:既在函数内调用函数本身的函数 Recursive function
1.递归介绍
https://www.cnblogs.com/meng-wei-zhi/p/8182659.html
递归函数 斐波那契数列
简单地理解就是函数调用自身的过程就称之为递归
如果一个问题可以表示为更小规模的迭代运算,就可以使用递归算法。
如果设F(n)为该数列的第n项(n∈N*),那么这句话可以写成如下形式::F(n)=F(n-1)+F(n-2)
迷宫问题 https://blog.csdn.net/qq_29681777/article/details/83719680
经典递归
def refunc(n):
i = 1
if n > 1:
i = n
n = n * refunc(n-1)
print("%d! =" %i, n)
return n
refunc(5)
2.递归详解
递归详细
这个代码中find_all_paths部分,第一层return [path]给newpaths,第二层return paths,以保持for node in g:这个循环一直进行,paths = [ ]这个东西只执行一次,所以paths相当于没有落空。
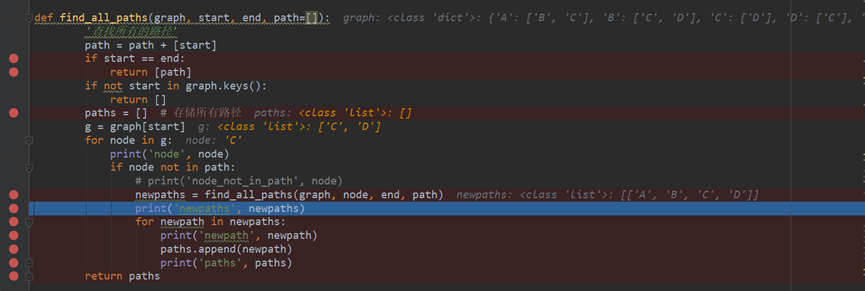
执行结果:
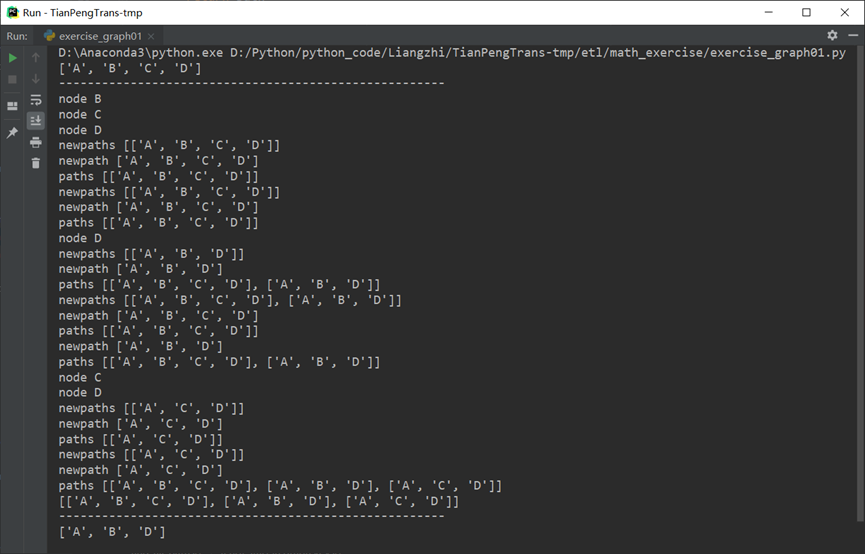
源代码:
# -*- encoding:utf-8 -*-
'''
A --> B
A --> C
B --> C
B --> D
C --> D
D --> C
E --> F
F --> C
'''
def find_path(graph, start, end, path=[]):
'寻找一条路径'
path = path + [start]
if start == end:
return path
if not start in graph.keys():
return None
for node in graph[start]:
if node not in path:
newpath = find_path(graph, node, end, path)
if newpath: # 看是否有下一个节点,此节点能否接通
return newpath
return path
def find_all_paths(graph, start, end, path=[]):
'查找所有的路径'
path = path + [start]
if start == end:
return [path]
if not start in graph.keys():
return []
paths = [] # 存储所有路径
g = graph[start]
for node in g:
print('node', node)
if node not in path:
# print('node_not_in_path', node)
newpaths = find_all_paths(graph, node, end, path)
print('newpaths', newpaths)
for newpath in newpaths:
print('newpath', newpath)
paths.append(newpath)
print('paths', paths)
return paths
def find_shortest_path(graph, start, end, path=[]):
'查找最短路径'
path = path + [start]
if start == end:
return path
if not start in graph.keys():
return None
shortest = None
for node in graph[start]:
if node not in path:
newpath = find_shortest_path(graph, node, end, path)
if newpath:
if not shortest or len(newpath) < len(shortest):
shortest = newpath
return shortest
# test
if __name__ == '__main__':
graph = {'A': ['B', 'C'],
'B': ['C', 'D'],
'C': ['D'],
'D': ['C'],
'E': ['F'],
'F': ['C']}
print (find_path(graph,'A','D'))
print('------------------------------------------------------')
print (find_all_paths(graph,'A','D'))
print('------------------------------------------------------')
print (find_shortest_path(graph,'A','D'))
3.递归中的return
一层一层返回
return:从被调用函数返回到主调函数中继续执行,并非一遇到return整个递归结束。
Anaconda
1.安装
然后安装pytorch 导入pycharm 使用清华源网站下载
https://www.cnblogs.com/xym4869/p/10309643.html
https://blog.csdn.net/zzq060143/article/details/88042075
2.Anaconda如何在已有的python版本上创建一个新的python的环境
https://blog.csdn.net/weixin_39954229/article/details/78100968?utm_source=blogxgwz8
第一步:打开终端
例如要在Anaconda下创建一个新的python2.7的环境
终端下输入:conda create -n py2 anaconda python=2.7
其中py2是你的新的python2.7环境的名称
接下来选择yes,等待安装完成
第二步:
使用python2.7环境
Windows: conda activate py2
Linux and Mac OS X: source activate py2
结束python2.7环境:
Windows: conda deactivate
Linux and Mac OS X: source deactivate
想要删除指定路径下的虚拟环境,使用如下的命令:conda remove --prefix=M:\InstalledSoft\Anaconda3\envs\py2 --all
http://jingyan.baidu.com/article/7e44095329a53b2fc0e2efb7.html
关于默认参数、可变参数、关键字参数,命名关键字参数的理解
https://www.jianshu.com/p/a74442a18077?utm_campaign
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict.如我下面的代码:

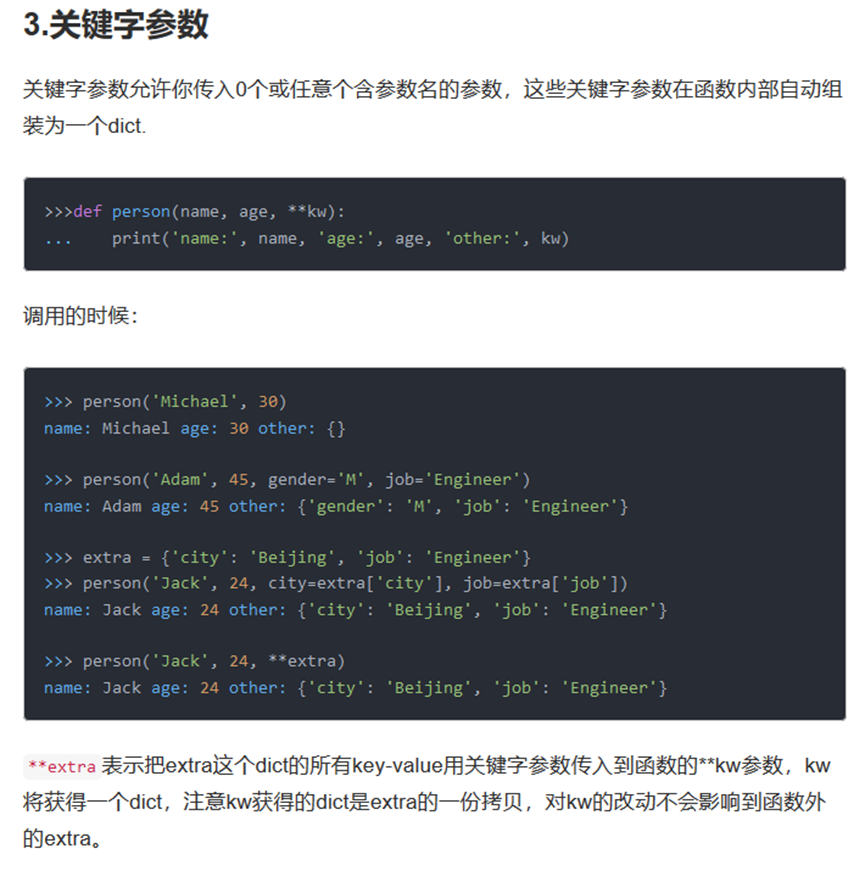
electra模型 谷歌开源
https://www.leiphone.com/news/202003/WPDVkBDxhk3J9hV7.html
原文地址:
https://ai.googleblog.com/2020/03/more-efficient-nlp-model-pre-training.html
GitHub 地址:
https://github.com/google-research/electra
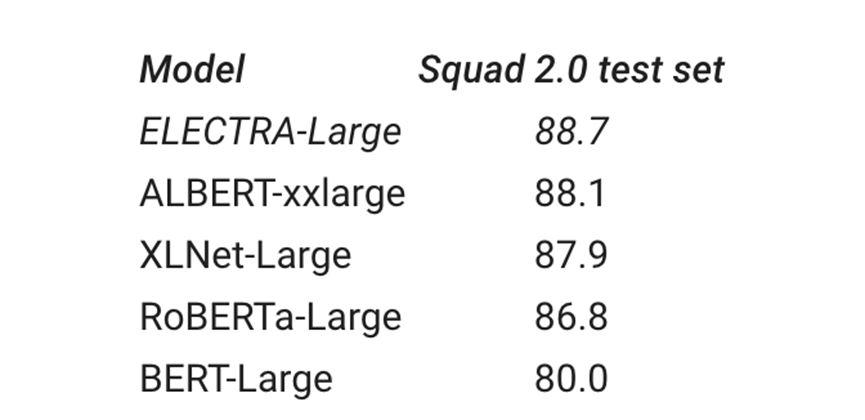
RPC
1.远程调用RPC
RPC是远程过程调用(Remote Procedure Call)的缩写形式。SAP系统RPC调用的原理其实很简单,有一些类似于三层构架的C/S系统,第三方的客户程序通过接口调用SAP内部的标准或自定义函数,获得函数返回的数据进行处理后显示或打印
2.RPC和http client区别
1.rpc是基于自定义tcp 没有太多的垃圾数据 而httpclient 基于http协议,做请求响应,要模仿网页请求,访问服务端,报文头垃圾数据较多 简单直接快速开发 面对小企业特别好用 但是当服务特别多的时候就不那么好用
2.rpc框架都是基于面向服务的,封装了服务发现和函数代理调用,并且优化了效率
分布式存储
MongoDB 索引优化
1.出现的问题
科维网80万条数据爬取时,由于数据量太大,mongodb储存时索引匹配出问题,既数据去重复的步骤。
解决办法:优化索引,改成url匹配。然后并没有解决问题 下午时候又可以正常跑了
问题原因:应该mongo服务器卡住了 需要时不时看下是否正常在跑。
重要问题反馈:由于科维网数据量大,这里我用了8个线程去跑,但是mongodb储存时去重复步骤出了问题,又换成两个线程再跑,周末研究下能否稳定在8线程跑。
既去重复的代码出问题,卡住

2.mongodb索引 https://www.runoob.com/mongodb/mongodb-indexing.html
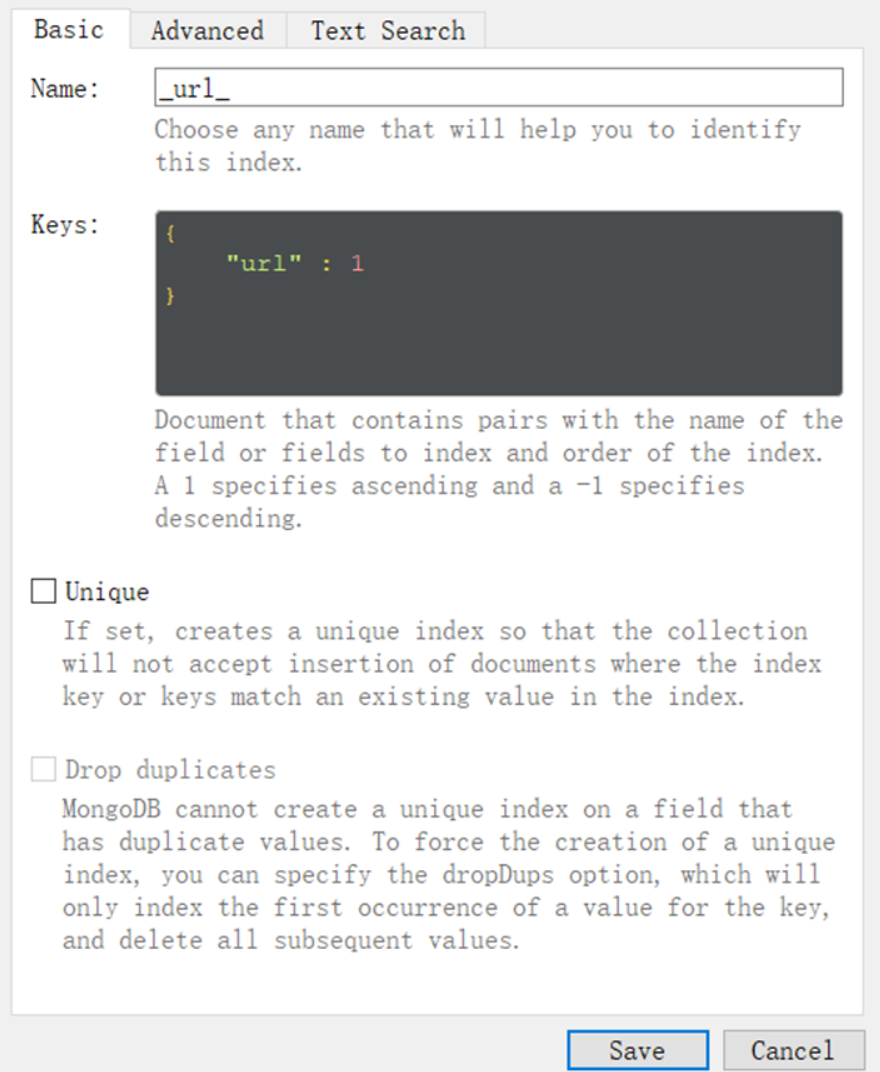

索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
3.mongo find问题 10万数量以上会很缓慢
https://blog.csdn.net/XuekunLu/article/details/51243068
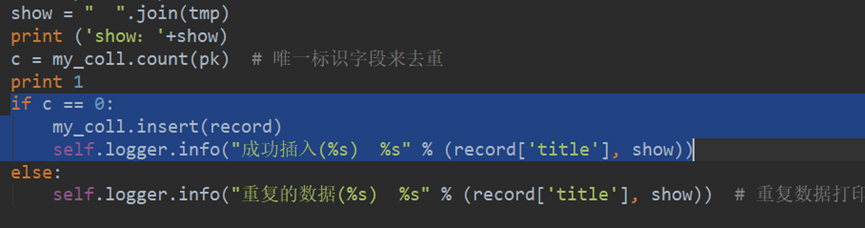
print show
r_in_db = my_coll.find_one(pk) # 唯一标识字段来去重
if not r_in_db:
my_coll.insert(record)
self.logger.info("成功插入(%s) %s" % (record['title'], show))
else:
self.logger.info("重复的数据(%s) %s" % (record['title'], show)) # 重复数据打印到日志
布隆过滤器 Bloom Filter 原理
https://www.jianshu.com/p/2104d11ee0a2
Python 安装官方whl包 和 tar.gz包的方法(推荐)
Windows环境:
安装whl包:pip install wheel -> pip install **.whl
安装tar.gz包:cd到解压后路径,python setup.py install
Linux环境:
安装whl同上
安装tar.gz:cd到解压后路径,./configure -> make -> make install
PDF文件 生成原理 储存原理
PDF也是类似word的标签语言。不过PDF主要的信息都是按页来描述的。具体的格式信息是公开的。
“本宝宝用的是 pdffactory pro,相当于一个虚拟打印机将所有可打印的文件打成 PDF 文件,本人常用来打 dwg,word,txt 计算书”
PDF文件格式可以将bai文字、字型du、格式、颜色及独立于设备和分辨率的zhi图形图dao像等封装在一个文件中。
而你的意思是将PDF文件以数据库形式存放,需要时以数据库来调用么。计算机多以二进制保存传输数据,PDF文件本身是一组二进制流,在封装的文件中将不同的信息分开归类,数据库则与之等同的设定一系列的项目来存放这些数据。SQL数据库是三级模式的数据库,分为关系模式,储存模式和子模式。
PDF转换成Word的原理是:
先将PDF文档中的文档元素提取出来,然后再将这些文档元素一个一个的复制到新生成的word文档中,并将原PDF文档中的排版信息也引用到word文档中。这样,PDF文档中的文字,图片,表格,注释等等文档元素就能转换成Word文档中相对应的元素
1.原理
格式原理:

原理图:
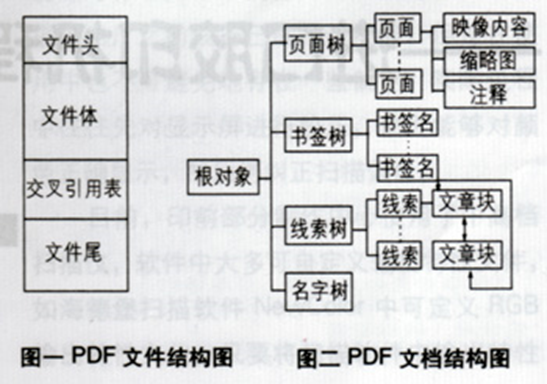
详细1:
 详细2:
详细2:
 详细3:
PDF交叉引用表
详细3:
PDF交叉引用表
PDF文件中交叉引用流对象(cross-reference stream)的解析方法
https://blog.csdn.net/yinqingwang/article/details/50674627
http://www.voidcn.com/article/p-mqwkaoan-bch.html

USBkey 原理
1024位非对称密钥算法
https://www.cnblogs.com/xtiger/p/10972373.html
数学基础:
互质关系,欧拉函数,欧拉定理,模反元素
国密即国家密码局认定的国产密码算法。主要有SM1,SM2,SM3,SM4。密钥长度和分组长度均为128位。
SM1 为对称加密。其加密强度与AES相当。该算法不公开,调用该算法时,需要通过加密芯片的接口进行调用。
SM2为非对称加密,基于ECC。该算法已公开。由于该算法基于ECC,故其签名速度与秘钥生成速度都快于RSA。ECC 256位(SM2采用的就是ECC 256位的一种)安全强度比RSA 2048位高,但运算速度快于RSA。
SM3 消息摘要。可以用MD5作为对比理解。该算法已公开。校验结果为256位。
SM4 无线局域网标准的分组数据算法。对称加密,密钥长度和分组长度均为128位。
USB转HDMI原理 DisplayLink
SB转HDMI的芯片不论大厂小厂用的芯片都是DisplayLink,虽然号称外置显卡,但和咱们一般认为的显卡不一样,不是直接将显卡的信号输出到USB接口,而且用CPU实时将信号压缩后传输到USB接口再转换成HDMI信号,说白了,就是用CPU代替GPU,这样带来的问题就是占用CPU超高,播放电影会卡。
DisplayLink是一个通过USB接口实现显示器连接到电脑的连接技术,可以非常简单、方便的连接电脑和多个显示设备。该技术可以通过USB接口扩展虚拟的电脑的桌面。DisplayLink技术最多可以支持6台显示器同时显示32位色彩的任意分辨率画面
前端渲染 和 后端渲染
前端渲染就是前端来写html的tag
后端渲染就是后端来写html的tag

重点理解这里for循环中return后crawler函数赋值给变量count
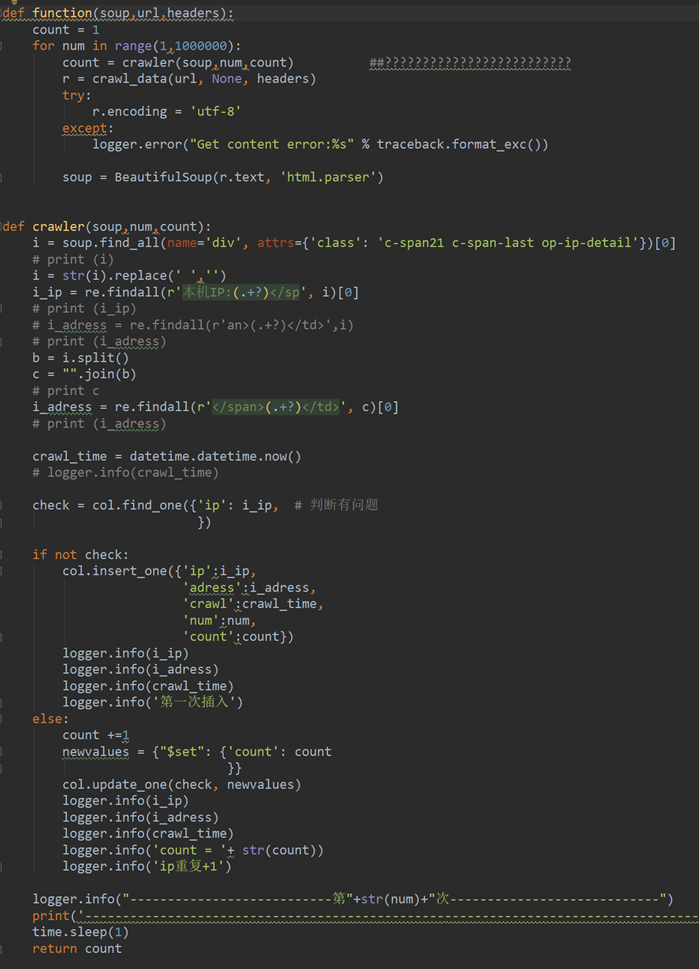
测试新的阿布云代理ip稳定性和ip重复率
(测试12560次,一次一条,总共10小时,非重复的有11746条,重复率6.48%,设置请求间隔1s,实际请求间隔2s-5s不等,总共报错264次,报错率2.1%,速率:21条/分钟。)
时间处理 datetime.timedelta
1.几小时前,几分钟前
https://www.cnblogs.com/saryli/p/6934913.html
https://blog.csdn.net/sunjinjuan/article/details/79113120
代码:
import datetime
now = datetime.datetime.now()
now - datetime.timedelta(hours=3)
datetime.datetime(2018, 1, 20, 8, 14, 45, 545000)
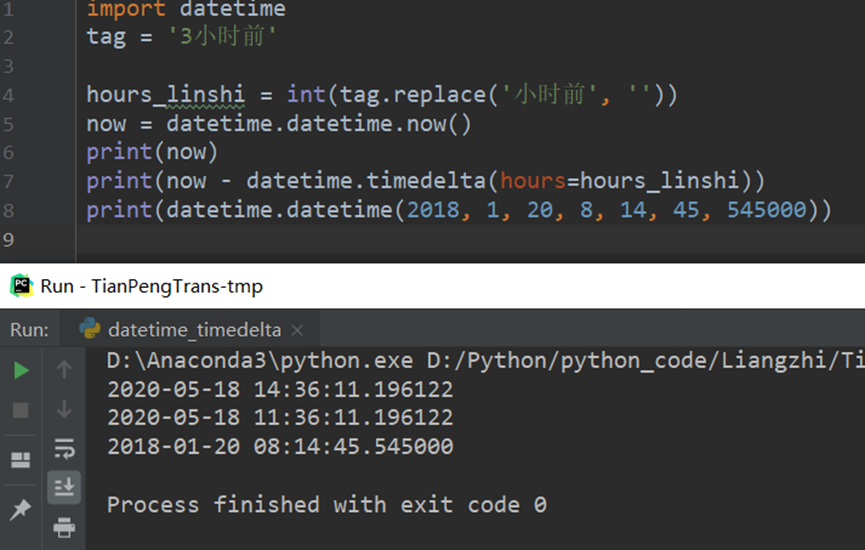
2.# 获取当前系统时间
方法一:
import datetime
(datetime.datetime.now() -datetime.timedelta()).strftime(“%Y-%m-%d %H:%M:%S”)
方法二:
Iso时间
datetime.datetime.now()
isodate类型
db.tianyc04.insert({mark:1, mark_time:new Date()})
db.tianyc04.insert({mark:2, mark_time:Date()})
db.tianyc04.find()
{ “_id” : ObjectId(“5126e00939899c4cf3805f9b”), “mark” : 1, “mark_time” : ISODate(“2013-02-22T03:03:37.312Z”) }
{ “_id” : ObjectId(“5126e00c39899c4cf3805f9c”), “mark” : 2, “mark_time” : “Fri Feb 22 2013 11:03:40 GMT+0800” }
我们看:使用new Date(),插入的是一个isodate类型;而使用Date()插入的是一个字符串类型。
那isodate是什么日期类型的?我们看这2个值,它比字符串大概少了8小时。这是由于mongo中的date类型以UTC(Coordinated Universal Time)存储,就等于GMT(格林尼治标准时)时间。而我当前所处的是+8区,所以mongo shell会将当前的GMT+0800时间减去8,存储成GMT时间。
如果通过get函数来获取,那么mongo会自动转换成当前时区的时间:
db.tianyc04.findOne({mark:1})
{
“_id” : ObjectId(“5126e00939899c4cf3805f9b”),
“mark” : 1,
“mark_time” : ISODate(“2013-02-22T03:03:37.312Z”)
}
db.tianyc04.findOne({mark:1}).mark_time
ISODate(“2013-02-22T03:03:37.312Z”)
x=db.tianyc04.findOne({mark:1}).mark_time
ISODate(“2013-02-22T03:03:37.312Z”)
x
ISODate(“2013-02-22T03:03:37.312Z”)
x.getFullYear()
2013
x.getMonth() # js中的月份是从0开始的(0-11)
1
x.getMonth()+1
2
x.getDate()
22
x.getHours() #注意这里获取到的小时是11,而不是3
11
x.getMinutes()
3
x.getSeconds()
37
self 理解
1.调整爬虫代码 加入self 实例类需要self 普通def不需要

在定义方法的时候有一个self参数,在所有的方法声明中都要用到这个参数,这个参数代表实例对象本身,当你用实例调用方法的时候, 由解释器自动的把实例对象本身悄悄的传递给方法,不需要你自己传递self进来,例如有一个带有两个参数的方法,你所有调用只需要传递进来二个参数。
例如这两个文件:
文件名: test.py
class A:
def abc(self,a,b):
a=a+1
b=b+1
文件名: test2.py
import A
A.abc(1,2)
print a,b
test2.py中如果使用a,b两个参数时,需要传递a,b两个参数,除了这两个参数以外的内容也是需要传递的,那么其中的self就代表了其他信息;
p.s. 什么是函数?函数是带名字的代码块
函数的实参和形参
形参:形参就是形式上的参数,相当与默认参数
实参:传入参数
def search(*t, d):
*t 把实参打包到一个元组 **d形参前面加可以应用一个字典
search(‘one’,’two’,one=’1’,two=’2’,three=’3’)
下面的参数传递:

self.后面定义的变量,方法 可以在所在的class中直接调用,直接使用self.+变量,方法就好了
对象和类 对象生命周期的基础是创建、初始化和销毁
def init():的含义
不是代表__init__()函数,而是代表会调用__init__()函数,就是创建对象时执行的第一个函数,一般会用来初始化对象。
这个函数类似init()初始化方法,来初始化新创建对象的状态,在一个对象被创建以后会立即调用。
1.首先说一下,带有两个下划线开头的函数是声明该属性为私有,不能在类地外部被使用或直接访问。
2.init函数(方法)支持带参数的类的初始化 ,也可为声明该类的属性
3.init函数(方法)的第一个参数必须是 self(self为习惯用法,也可以用别的名字),后续参数则可 以自由指定,和定义函数没有任何区别。
代码规范学习记录
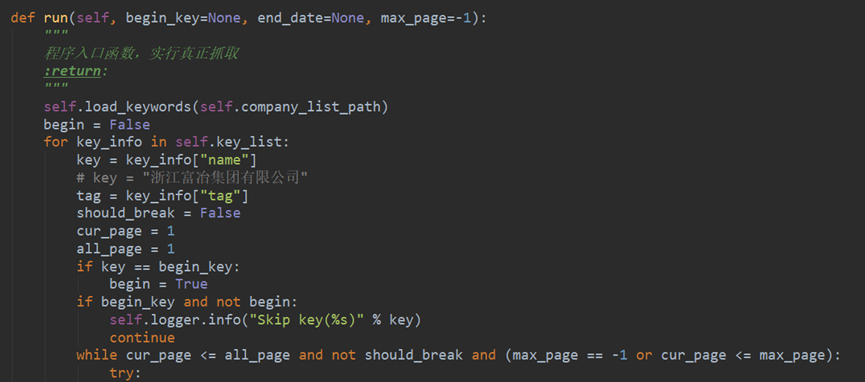

xpath 获取某个标签的子标签和 这个标签的文本
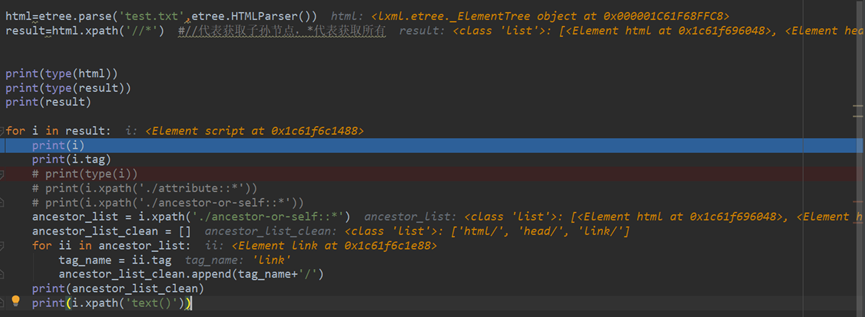
最后一句是获取文本
https://www.cnblogs.com/zhang-pengcheng/p/4294930.html
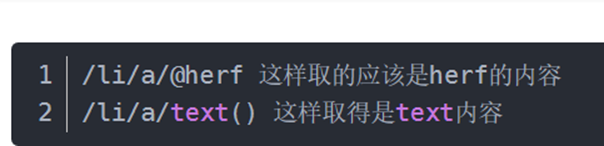
https://blog.csdn.net/qq_37059367/article/details/83819828
<div>
<a id="1" href="www.baidu.com">我是第1个a标签</a>
<p>我是p标签</p>
<a id="2" href="www.baidu.com">我是第2个a标签</a>
<a id="3" href="www.baidu.com">我是第3个a标签</a>
<a id="4" href="www.baidu.com">我是第4个a标签</a>
<p>我是p标签</p>
<a id="5" href="www.baidu.com">我是第5个a标签</a>
</div>
获取第三个a标签的下一个a标签:"//a[@id='3']/following-sibling::a[1]"
获取第三个a标签后面的第N个标签:"//a[@id='3']/following-sibling::*[N]"
获取第三个a标签的上一个a标签:"//a[@id='3']/preceding-sibling::a[1]"
获取第三个a标签的前面的第N个标签:"//a[@id='3']/preceding-sibling::*[N]"
获取第三个a标签的父标签:"//a[@id=='3']/.."
html2text模块 网页标签文本分类
1.代码
按照网站格式抓取文本
传入源码
>>> import html2text
>>>
>>> h = html2text.HTML2Text()
>>> # Ignore converting links from HTML
>>> h.ignore_links = True
>>> print h.handle("<p>Hello, <a href='http://earth.google.com/'>world</a>!")
Hello, world!
>>> print(h.handle("<p>Hello, <a href='http://earth.google.com/'>world</a>!"))
Hello, world!
2.标签分类结果 result
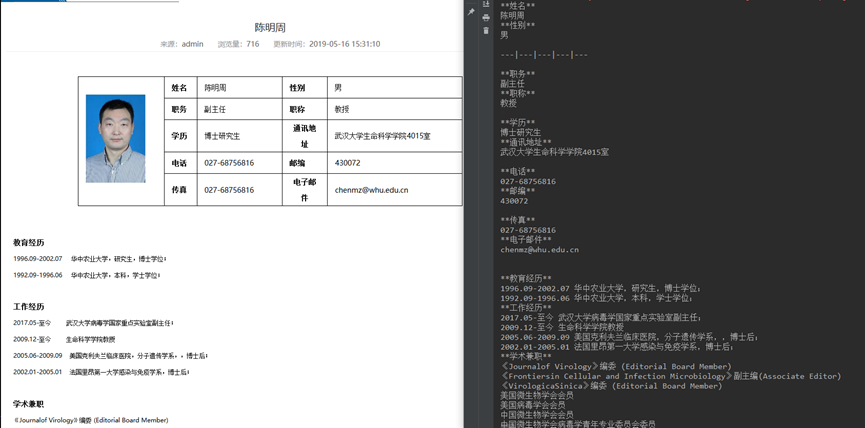
3.html2text缺点分析
对多重标题,既内嵌的标题识别不好,只能识别套在外面的标题
Software 软件安装
1.NoSQLBooster for MongoDB
2.MobaXterm Professinal (Linux)
3.Navicat Prremiun (MySQL)
4.
Goose Extractor 抽取正文
http://www.sohu.com/a/258765905_642571
Goose Extractor基于NLTK和Beautiful Soup,分别是文本处理和HTML解析的领导者。
Goose Extractor是一个Python的开源文章提取库。’Goose Extractor完全用Python重写了。目标是给定任意资讯文章或者任意文章类的网页,不仅提取出文章的主体,同时提取出所有元信息以及图片等信息。’
1.Goose 源码分析
2.测试
http://www.sohu.com/a/258765905_642571
除了标题 title和正文 cleaned_text外,还可以获取一些额外的信息,比如:
meta_deion:摘要
meta_keywords:关键词
tags:标签
top_image:主要图片
infos:包含所有信息的 dict
raw_html:原始 HTML 文本
1.1
url=
# 获取文章内容
article = g.extract(url=url) 这里article的type是<class 'goose.article.Article'>
# 标题
print( '标题:', article.title)
# 显示正文
print(article.cleaned_text)
1.2
可以根据需要添加user-agent 信息:
g = Goose({ 'browser_user_agent': 'Version/5.1.2 Safari/534.52.7'})
https://blog.csdn.net/weixin_42139375/article/details/82902955
环境配置链接:https://www.jianshu.com/p/a445750dd016
3.完整测试 分析
goose测试自动抓取结果百度新闻结果图文展示:
3.1灰体字没有抓到
3.1头部的描述词可以抓到,头部的图片也可以抓到
时间测试1:
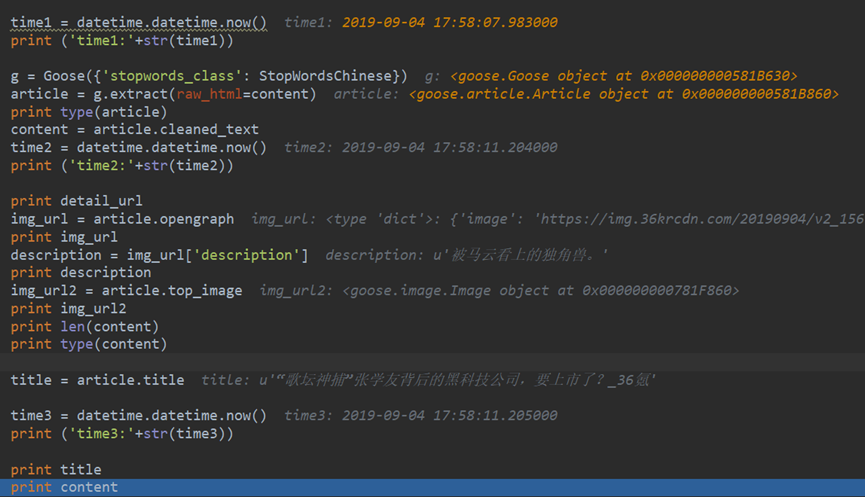
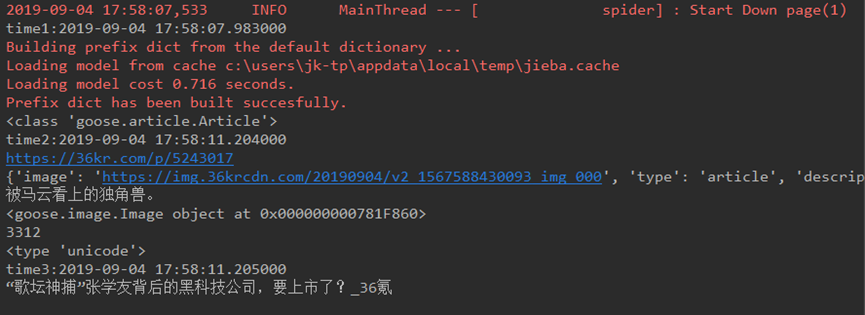
时间测试2:
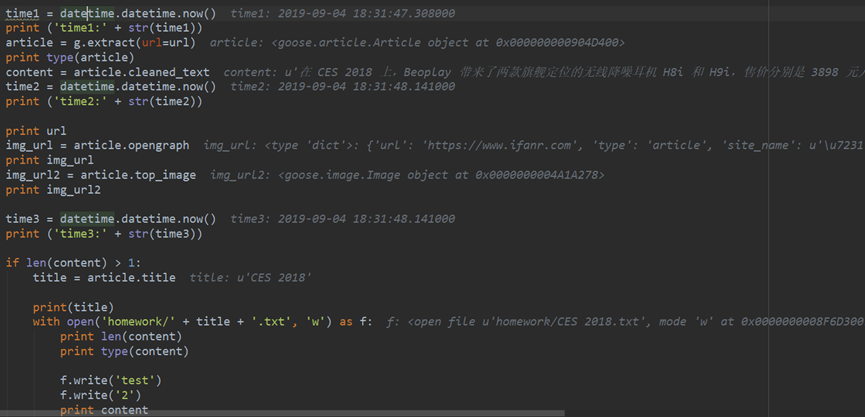
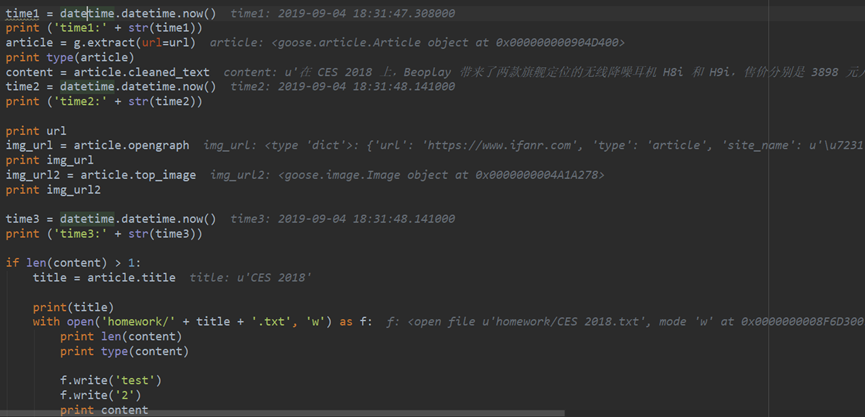
4.goose测试总结:
4.1. 在上述示例中使用到的 StopWordsChinese 为中文分词器,可一定程度上提高中文文章的识别准确率,但更耗时。
4.2. Goose 虽然方便,但并不能保证每个网站都能精确获取,因此适合大规模文章的采集,如热点追踪、舆情分析等。它只能从概率上保证大多数网站可以相对准确地抓取。我经过一些尝试后发现,抓取英文网站优于中文网站,主流网站优于小众网站,文本的提取优于图片的提取。
4.3. 如果你是使用基于 python2 的 goose,有可能会遇到编码上的问题(尤其是 windows 上)。这方面可以在公众号对话里回复关键词 编码,我们有过相关的讲解。
4.4.抓取时间大概1秒一个 只抓链接和文本
4.5.从项目中的requirements.txt文件可以看出,goose 中使用到了Pillow、lxml、cssselect、jieba、beautifulsoup、nltk,goose3 还用到了 requests
4.6.jieba-中文分词利器
4.7.只抓到一张图片,标签可以提取但不准确,提取文本和标题title较为准确,可以抓取部分描述和部分tag
4.8多次时间测试:
测试100次 分析文本时间0.8-1.4s之间


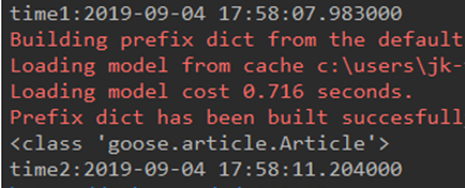

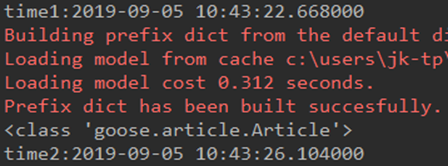

5.完整 Goose学习 https://www.helplib.com/GitHub/article_111492
5.1
切换解析器:Goose现在可以与lxml解析器或者lxml解析器一起使用。 默认情况下使用html解析器。 如果你想使用soup解析器,在配置字典中传递它:
g = Goose({‘browser_user_agent’: ‘Mozilla’, ‘parser_class’:’soup’}
5.2
article.top_image.src
http://i2.cdn.turner.com/cnn/dam/assets/111017024308-occupy-london-st-paul-s-cathedral-story-top.jpg
5.3
手机抓包 探究如何模拟手机端爬取微信公众号文章(比电脑端更全)
电脑端搭建安卓jdk环境(搭建运行环境)
很多app的信息、访问,只能在手机端进行,比如抖音、微信公众号,可以搭建安卓jdk运行环境。下载appium 这个app。Appium有python数据接口。
Selenium和Appium的关系
Selenium是web端的自动化测试工具,Appium是移动端的自动化测试工具
联系:在Python的appium包中实际继承了Selenium,在测试过程中将移动端的页面元素当作是网页来处理。所以Selenium的定位方法也可以使用。
Error Collection 问题汇总
1.TypeError: not all arguments converted during string formatting
在格式化字符串的时候,不是所有的参数被转换
解决方法:
%s 数量要对应好
self.logger.error("详情页出错:%s%s" % (traceback.format_exc(), detail_url))
2.抓取总共页数时,用页数列表里倒数第几个来确定,更保险,更稳固
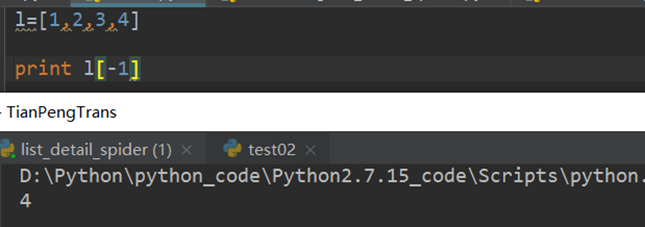
3.TypeError: missing 1 required positional argument: ‘self’


报错:missing 1 required positional argument: ‘self’
原因:在调用类函数的时候,没有进行实例化
解决办法:

4.pymongo.errors.DuplicateKeyError:E11000
https://www.jianshu.com/p/32408703619d
出现这种错误,依据提示看来是因为MongoDB使用了同一ID产生的问题,其实主要原因并不在数据库:
创建字典时,放在了for循环外。
传递给mongodb的一直是都是同一个dict对象,所以mongo保存时会出现 "_id" 重复的问题。
所以,只需要把 创建的字典 放到循环里面,即可解决。
5.pymongo.errors.CursorNotFound: Cursor not found
原因+解决办法
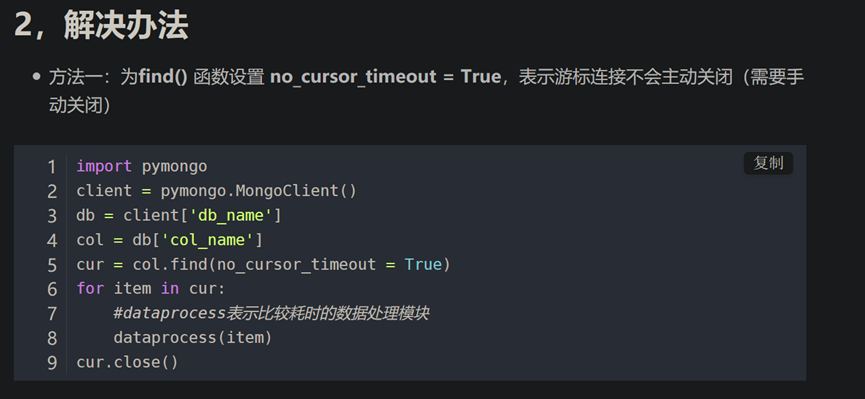
6.Fatal Python error: Cannot recover from stack overflow (嵌套层数过多超出限制)
https://blog.csdn.net/Dontla/article/details/103811587
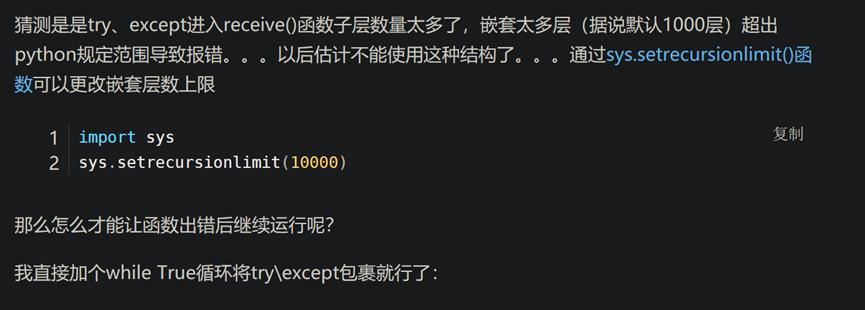
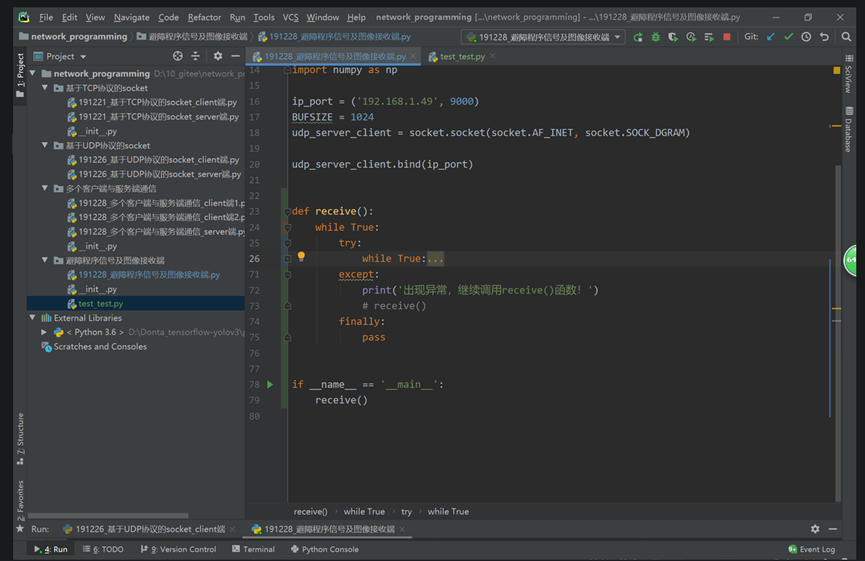
7.TypeError: cannot unpack non-iterable NoneType object
python报错如下:
TypeError: cannot unpack non-iterable NoneType object
解决方法:报错的原因是函数返回值得数量不一致,查看函数返回值数量和调用函数时接收返回值的数量是不是一致,修改一致即可
8.pymongo.errors.CursorNotFound: Cursor not found
Mongo读取一个进程的缓存时间默认20分钟,超过20分钟会报错,如果读取一条数据,然后要操作很长时间,那就把所有数据都读出来,然后操作
https://www.cnblogs.com/beiyi888/p/11577408.html
故事背景:先从数据库中取得所有数据 db[‘test’].find(),然后对结果进行for循环,但是当do_something函数耗时过长,在cursor上长时间没有进行操作,引发cursor在mongodb服务端超时。
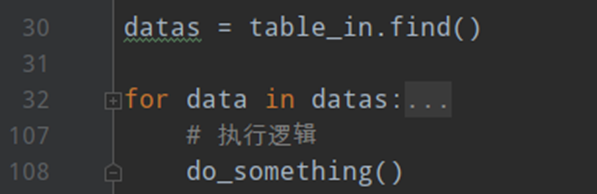
分析原因:
你在用 db.collection.find() 的时候,它返回的不是所有的数据,而实际上是一个“cursor”。它的默认行为是:第一次向数据库查询 101 个文档,或 1 MB 的文档,取决于哪个条件先满足;之后每次 cursor 中的文档用尽后,查询 4 MB 的文档。另外,find() 的默认行为是返回一个 10 分钟无操作后超时的 cursor。如果我一个 batch 的文档十分钟内没处理完,过后再处理完了,再用同一个 cursor id 向服务器取下一个 batch,这时候 cursor id 当然已经过期了,这也就能解释为啥我得到 cursor id 无效的错误了。
思路总结:
默认 mongo server维护连接的时间窗口是十分钟;默认 单次从 server获取数据是101条或者 大于1M小于16M的数据,所以默认情况下,如果10分钟内未能处理完数据,则抛出该异常。
9.mongo报错:bson.errors.InvalidBSON: ‘utf-8’ codec can’t decode byte 0xed in position
解决方法:
https://stackoverflow.com/questions/36314776/pymongo-error-bson-errors-invalidbson-utf8-codec-cant-decode-byte-0xa1-in-p
col1 = col1.with_options(codec_options = bson.CodecOptions(unicode_decode_error_handler="ignore"))
完整代码:
import bson
import pymongo
client = pymongo.MongoClient(host='xxxx', port=00000)
db1 = client.lz_data_yewu
col1 = db1.expert_ckcest
col1 = col1.with_options(codec_options = bson.CodecOptions(unicode_decode_error_handler="ignore"))
c=0
print(col1.find_one())
for i in col1.find():
if '中国院士馆' in i['department']:
c += 1
print(c)
print(i['expert_name'])
10.mongodb pymongo.errors.CursorNotFound: Cursor not found, cursor id: 82792803897 Mongo游标超时问题
Mongo游标超时问题:
默认 mongo server维护连接的时间窗口是十分钟
默认 单次从 server获取数据是101条或者 大于1M小于16M的数据
所以默认情况下,如果10分钟内未能处理完数据,则抛出该异常。
解决办法:
1.修改每批次获取数据量的条数,即batch size:
collection.find(condition).batch_size(5)
批量数需 估算十分钟内能处理的数据量
2.延长超时时间 cursor
db.getCollection("unicom_jd").find({}).noCursorTimeout()
self.mongo_col_read.find(no_cursor_timeout=True)
11.TypeError: ‘NoneType’ object is not iterable
这个错误提示一般发生在将None赋给多个值时。

12.MySQL ErrorMessage: MySQL Query ErrorSQL:
MySQL ErrorMessage: MySQL Query ErrorSQL: SELECT depth, parentid, front FROM xycms_productcate WHERE cid=Error: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘’ at line 1Errno.: 1064
13.bug记录 mongo delete
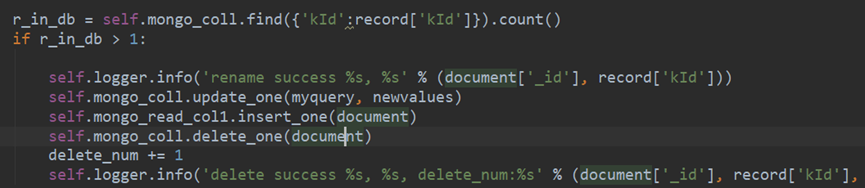
Document 是个对象,当update后document发生了改变,所以这里删除失败了
14.RuntimeError: dictionary changed size during iteration
原因:在遍历过程中对字典进行的操作影响到遍历过程。
解决办法:
使用要遍历的字典的拷贝,这里使用浅拷贝。如果遍历过程对字典的操作较复杂,建议使用深拷贝
d = {1: "a", 2: "b", 3: {4: None, 5: "d", 6: {7: "e"}}, 8: "f"}
record = d
for key, value in (record.copy()).items():
if isinstance(value, dict):
for child_key, child_value in value.items():
if child_value == None:
record[key][child_key] = ''
else:
pass
else:
if value == None:
record[key] = ''
else:
pass
print(record)
Embedding的理解
Embedding 是一个将离散变量转为连续向量表示的一个方式。嵌入。通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中,一个萝卜一个坑。
https://zhuanlan.zhihu.com/p/46016518
https://www.zhihu.com/question/32275069
高纬度数据
维数灾难(Curse of Dimensionality):通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。维数灾难涉及数字分析、抽样、组合、机器学习、数据挖掘和数据库等诸多领域。
特征抽取
基于低维投影的降维:主要包括主成分分析( Principal Component Analysis, PCA) 方法和投影寻踪 ( Projection Pursuit,PP) 方法
基于神经网络的降维:主要包括自动编码网络、自组织映射网络和生成建模
基于数据间相似度的降维:主要包括多维尺度、随机邻居嵌入、Isomap、局部线性嵌入和拉普拉斯特征映射
基于分形的降维
Projection Pursuit,即投影寻踪

文本相似度计算
1.基本方法
句子相似度计算我们一共归类了以下几种方法:
• 编辑距离计算
• 杰卡德系数计算
• TF 计算
• TFIDF 计算
• Word2Vec 计算
2.编辑距离
动态规划 DP – decision process
动态规划(dynamic programming)是运筹学的一个分支,是求解决策过程(decision process)最优化的数学方法。20世纪50年代初美国数学家R.E.Bellman等人在研究多阶段决策过程(multistep decision process)的优化问题时,提出了著名的最优化原理(principle of optimality),把多阶段过程转化为一系列单阶段问题,利用各阶段之间的关系,逐个求解,创立了解决这类过程优化问题的新方法——动态规划。
动态规划一般可分为线性动规,区域动规,树形动规,背包动规四类。
举例:
线性动规:拦截导弹,合唱队形,挖地雷,建学校,剑客决斗等;
区域动规:石子合并, 加分二叉树,统计单词个数,炮兵布阵等;
树形动规:贪吃的九头龙,二分查找树,聚会的欢乐,数字三角形等;
背包问题:01背包问题,完全背包问题,分组背包问题,二维背包,装箱问题,挤牛奶(同济ACM第1132题)等;
应用实例:
最短路径问题,项目管理,网络流优化等;
MQ 消息列队
1.分布式追踪系统,链路追踪
https://www.cnblogs.com/binyue/p/5703812.html
p.s 架构 Software Architecture、 架构,又名软件架构,是有关软件整体结构与组件的抽象描述,用于指导大型软件系统各个方面的设计。架构描述语言(ADL)用于描述软件的体系架构。
链路追踪原理图
2.RabbitMQ
https://www.cnblogs.com/ajianbeyourself/p/3847645.html
相当于一个mongo数据库,mongo数据库中的一个临时表,用完的数据就销毁。消息列队。
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而群集和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。

软件对比:

#####下载安装rabbitmq和Erlang
下载安装rabbitmq和Erlang
下载安装rabbitmq和Erlang
https://baijiahao.baidu.com/s?id=1608425504960724381&wfr=spider&for=pc
两个都加入path系统变量
最后我们在本地浏览器中输入:localhost:15672访问RabbitMQ的后台管理页面(初始化用户名和密码都是guest)
Rabbitmq的使用:
https://www.cnblogs.com/saryli/p/9150985.html
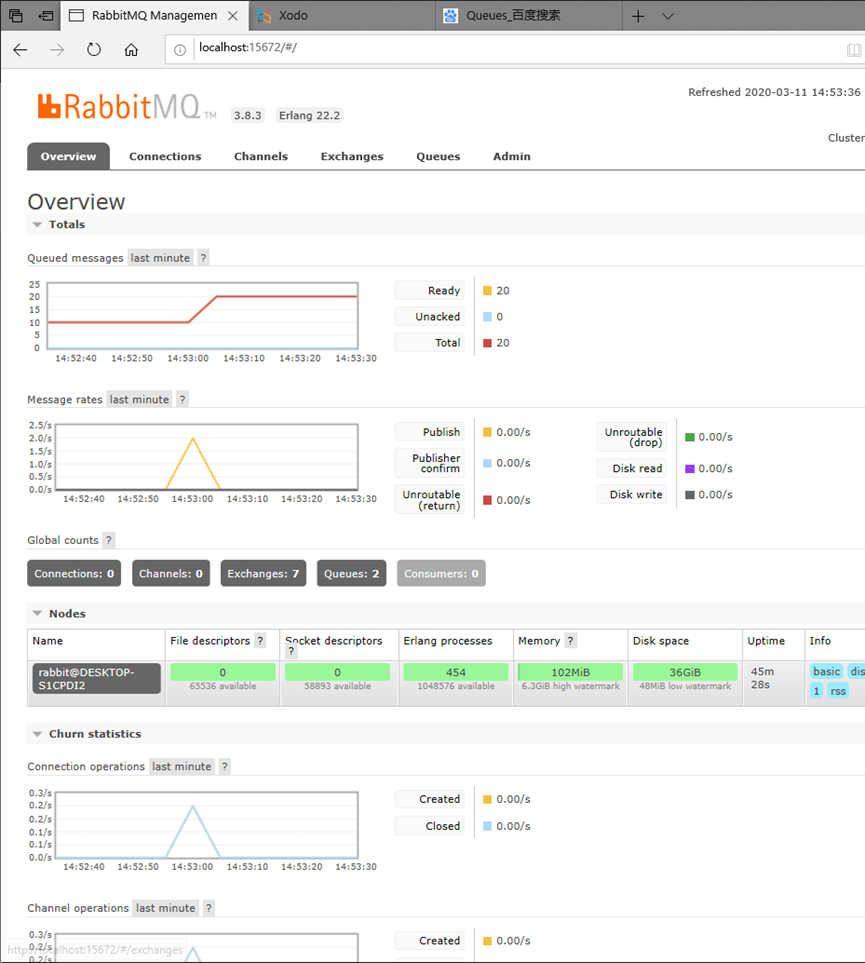
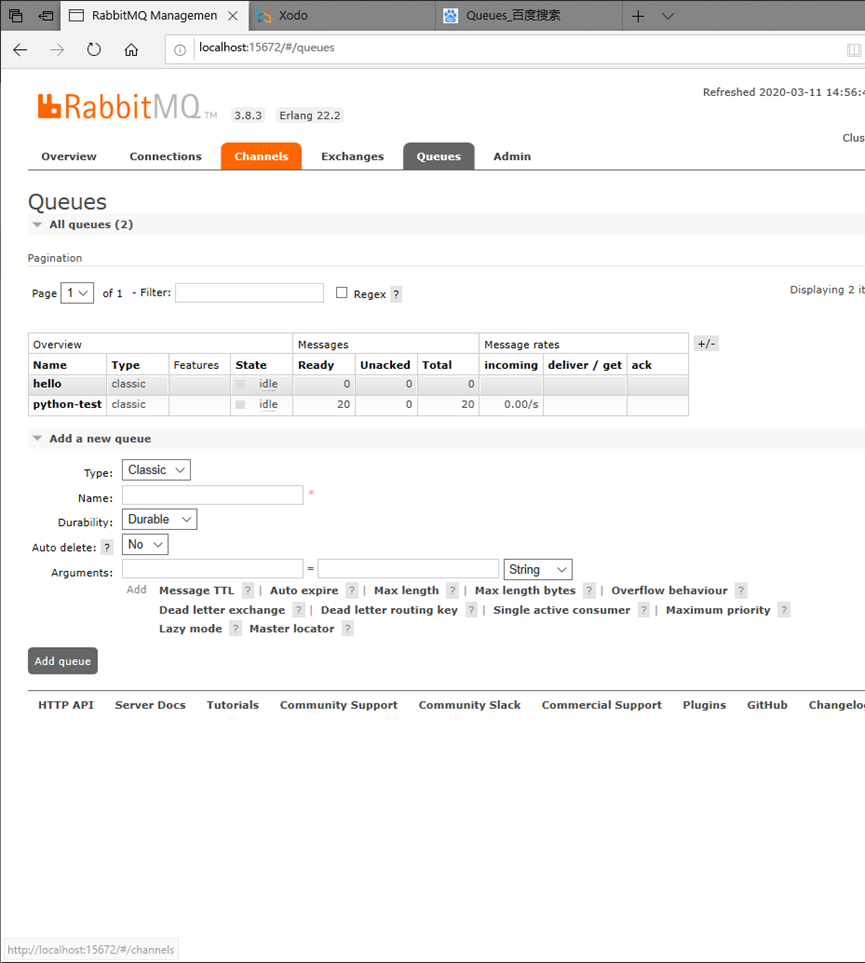
import pika
import json
credentials = pika.PlainCredentials('guest', 'guest') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
# connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost')) # 连接本地的RabbitMQ服务器
channel=connection.channel()
# 声明消息队列,消息将在这个队列传递,如不存在,则创建
result = channel.queue_declare(queue = 'hello')
# channel.basic_publish(exchange='', # 使用默认的exchange来发送消息到队列
# routing_key='hello', # 发送到该队列 hello 中
# body='Hello World!') # 消息内容
for i in range(10):
message=json.dumps({'OrderId':"1000%s"%i})
# 向队列插入数值 routing_key是队列名
channel.basic_publish(exchange = '',routing_key = 'python-test',body = message)
print(message)
connection.close()
rabbitmq使用的协议是amqp,用于python的推荐客户端是pika
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。
3.Kafka 开源消息系统
https://blog.csdn.net/qq_36918149/article/details/98471761
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka原理
Kafka是为了高吞吐量设计的
https://www.cnblogs.com/haolujun/p/9632835.html
jieba 中文分词算法
https://www.cnblogs.com/sthu/p/9316051.html
https://www.jianshu.com/p/a2f0c272e32e
https://blog.csdn.net/Sakura55/article/details/88286293
https://www.cnblogs.com/lyq-biu/p/9641677.html
https://www.cnblogs.com/wkfvawl/p/9487165.html
1.分词模式
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
“停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。”
from importlib import reload
添加自定义关键词:
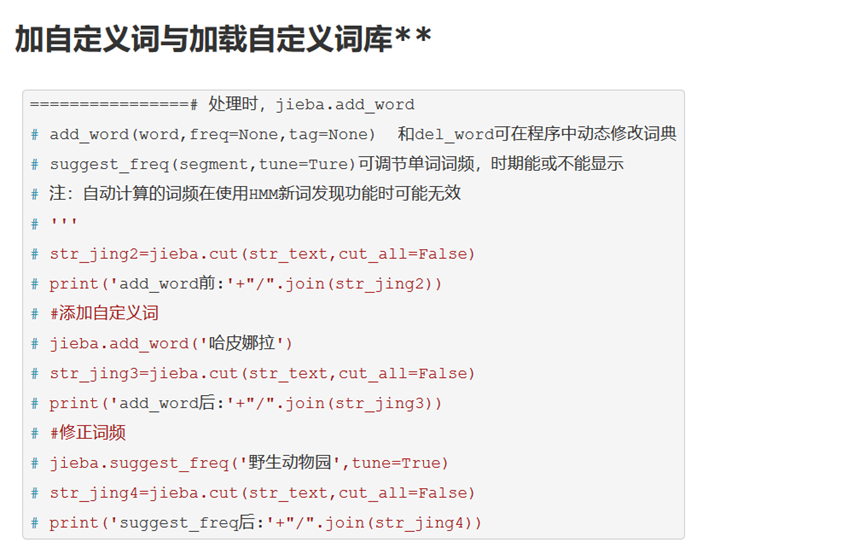
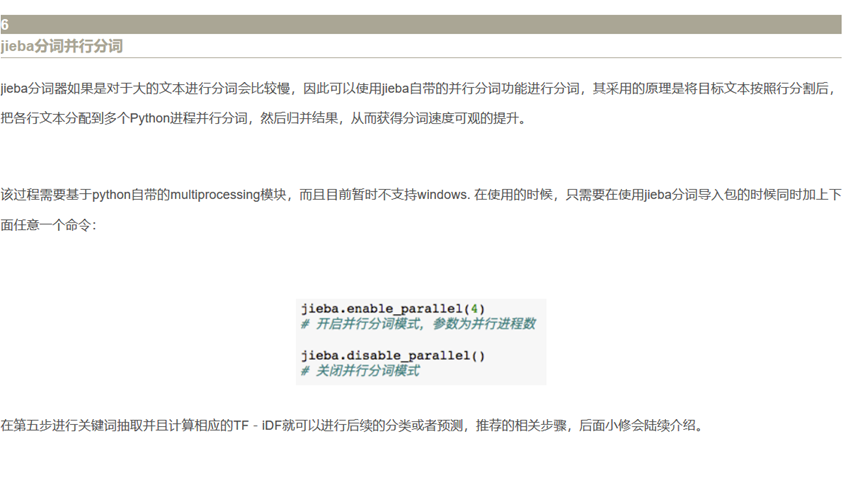
2.jieba加入指定词语(长词)和设置权重

文本摘要生成
https://www.cnblogs.com/Allen-rg/p/10986900.html
自动文本摘要有非常多的应用场景,如自动报告生成、新闻标题生成、搜索结果预览等。
尽管对自动文本摘要有庞大的需求,这个领域的发展却比较缓慢。对计算机而言,生成摘要是一件很有挑战性的任务。从一份或多份文本生成一份合格摘要,要求计算机在阅读原文本后理解其内容,并根据轻重缓急对内容进行取舍,裁剪和拼接内容,最后生成流畅的短文本。因此,自动文本摘要需要依靠自然语言处理/理解的相关理论,是近几年来的重要研究方向之一。
自动文本摘要通常可分为两类,分别是抽取式(extractive)和生成式(abstractive)。抽取式摘要判断原文本中重要的句子,抽取这些句子成为一篇摘要。而生成式方法则应用先进的自然语言处理的算法,通过转述、同义替换、句子缩写等技术,生成更凝练简洁的摘要。比起抽取式,生成式更接近人进行摘要的过程。历史上,抽取式的效果通常优于生成式。伴随深度神经网络的兴起和研究,基于神经网络的生成式文本摘要得到快速发展,并取得了不错的成绩。
关键词抽取 算法 原理 Keyword extractor
1.关键词提取 背景
(1)国外背景
1、 Krulwich 和Burkey 利用启发式规则抽取文档中重要的词和短语。这些启发式规则主要依据格式和简单结构特点抽取关键词[ 1 ] 。
2、 Steier 和Belew利用互信息发现文档中含两个词的关键词,他们在研究中发现,同样两个词的短语,专业领域计算出的互信息值往往比通用领域高[2 ] 。
3、 Turney 与Witten 分别开发了系统GenEx 与KEA ,这两个系统在关键词抽取的发展史上具有重要的意义。他们首次利用监督学习的方法训练已标注关键词的语料,然后通过训练出的关键词抽取模型对未标注关键词的文档进行关键词抽取,此方法在准确率与召回率上都超越了前人的工作。
Turney 利用遗传算法和C4.5决策树学习方法设计了系统GenEx 。而Witten 采用朴素贝叶斯技术对短语离散的特征值进行训练,获取模型的权值,以完成下一步从文档中抽取关键短语的任务[ 3~4 ] 。
4、 Salton 提出了TF/ IDF ( Term Frequency & Inverse Document Frequency) 算法。此后Salton 多次论证TF/IDF 公式在信息检索中的有效性,在1988 年又详细阐述了多种词权重计算方法在文献检索时适用情况[ 5 ] 。词频 (TF) 是一词语出现的次数除以该文件的总词语数。逆向文件频率 (inverse document frequency,IDF) 可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
(2) 国内背景
1、刘远超和王晓龙等人利用粗集理论对关键词短语的构成规则进行了挖掘,将挖掘出的规则用于指导关键词的自动抽取,避免了一些错误的搭配被抽取,从而提高了系统的性能,使抽取结果更加符合人们的习惯[6 ] 。
2、任克强和赵光甫等人提出以带权语言网络来表征HTML 标记对网页文本的影响,给出了综合介数指标与紧密度指标的词语中心度度量方法,实现了网页关键词的抽取算法,表现出良好的抽取效果以及可解释性。
3、马亮和何婷婷等人采用查询相关性特征和话题相关性特征来对关键词语进行打分,最后将这两个特征进行线性组合来得到关键词语的重要度[7 ]。
主题句提取背景
国外背景
目前仅有Kastner 等[9]为CNN 新闻自动提取“新闻要点”的工作与本文思路相同, 都是在单篇新闻文档中利用语法、语义和统计特征提取包含事件信息的最重要的句子。Kastner等分析了CNN 新闻中要点句的分布特征, 结合句子特征(句子位置、时间信息、因果动词、特定触发词等)和词特征(动词类别、专有名词、bonus 或stigma词)计算句子的重要性, 提取4 个包含关键事实信息的句子作为“新闻要点”。
2.TF-IDF 词频算法
2.1 TF-IDF 介绍
TF-IDF(注意:这里不是减号)是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
一个词预测主题能力越强,权重就越大,反之,权重就越小。我们在网页中看到“原子能”这个词,或多或少地能了解网页的主题。我们看到“应用”一次,对主题基本上还是一无所知。因此,“原子能“的权重就应该比应用大。 应删除词的权重应该是零。
2.2 计算tdidf
https://blog.csdn.net/levy_cui/article/details/77962768
[math.log]
如果a^b=c,则称b是以a为底c的对数,记作:b=loga(c)。
log是对数,即已知幂的底数求指数
比如已知2和8,求2的几次方是8,即log(2)8=3

3.TextRank算法提取关键词
https://blog.csdn.net/weixin_43378396/article/details/90322422
https://blog.csdn.net/qian99/article/details/83713872
https://blog.csdn.net/qq_41664845/article/details/82869596
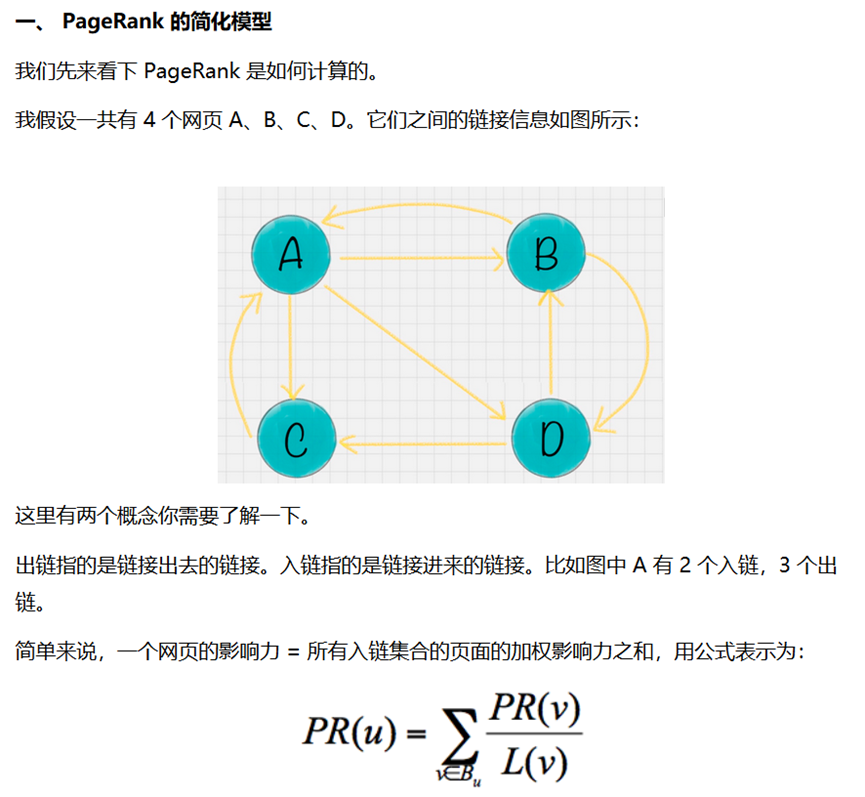
4.词向量算法
标题抽取 标题识别 Title Extractor

正文抽取 Text Extractor
正文提取原理
https://zhuanlan.zhihu.com/p/26192335
boilerpipe3安装 java写的自动获取正文包
from boilerpipe.extract import Extractor
your_url = 'http://gr.xjtu.edu.cn/web/meikuizhi'
extractor = Extractor(extractor='ArticleExtractor', url=your_url)
extracted_text = extractor.getText()
extracted_html = extractor.getHTML()
print(extracted_text)
print('------------------------')
extractor2 = Extractor(extractor='KeepEverythingExtractor', url=your_url)
extracted_text2 = extractor2.getText()
print(extracted_text2)
boilerpipe.extract.Extractor 提取非英文文章
from boilerpipe.extract import Extractor
extractor = Extractor(extractor='ArticleExtractor', url=your_url)
extractor = Extractor(extractor='KeepEverythingExtractor', url=detail_url)
extracted_text = extractor.getText()
精准分句
def cut_sent(para):
para = re.sub('([。;!?\?])([^”'])', r"\1\n\2", para) # 单字符断句符
para = re.sub('(\.{6})([^”'])', r"\1\n\2", para) # 英文省略号
para = re.sub('(\…{2})([^”'])', r"\1\n\2", para) # 中文省略号
para = re.sub('([。;!?\?][”'])([^,;。!?\?])', r'\1\n\2', para)
# 如果双引号前有终止符,那么双引号才是句子的终点,把分句符\n放到双引号后,注意前面的几句都小心保留了双引号
para = para.rstrip() # 段尾如果有多余的\n就去掉它
# 很多规则中会考虑分号;,但是这里我把它忽略不计,破折号、英文双引号等同样忽略,需要的再做些简单调整即可。
return para.split("\n")
句法分析
1.依存句法分析
https://www.sohu.com/a/325005804_312708
句法结构分析(syntactic structure parsing),又称短语结构分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是识别出句子中的短语结构以及短语之间的层次句法关系。
依存关系分析,又称依存句法分析(dependency syntactic parsing),简称依存分析,作用是识别句子中词汇与词汇之间的相互依存关系。
深层文法句法分析,即利用深层文法,例如词汇化树邻接文法(Lexicalized Tree Adjoining Grammar,LTAG)、词汇功能文法(Lexical Functional Grammar,LFG)、组合范畴文法(Combinatory Categorial Grammar,CCG)等,对句子进行深层的句法以及语义分析。
维基百科是这样描述的:The dependency-based parse trees of dependency grammars see all nodes as terminal, which means they do not acknowledge the distinction between terminal and non-terminal categories. They are simpler on average than constituency-based parse trees because they contain fewer nodes.
依存句法是由法国语言学家L.Tesniere最先提出。它将句子分析成一颗依存句法树,描述出各个词语之间的依存关系。也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的。
在自然语言处理中,用词与词之间的依存关系来描述语言结构的框架称为依存语法(dependence grammar),又称从属关系语法。利用依存句法进行句法分析是自然语言理解的重要技术之一。
重要概念
依存句法认为“谓语”中的动词是一个句子的中心,其他成分与动词直接或间接地产生联系。
依存句法理论中,“依存”指词与词之间支配与被支配的关系,这种关系不是对等的,这种关系具有方向。确切的说,处于支配地位的成分称之为支配者(governor,regent,head),而处于被支配地位的成分称之为从属者(modifier,subordinate,dependency)。
依存语法本身没有规定要对依存关系进行分类,但为了丰富依存结构传达的句法信息,在实际应用中,一般会给依存树的边加上不同的标记。
依存语法存在一个共同的基本假设:句法结构本质上包含词和词之间的依存(修饰)关系。一个依存关系连接两个词,分别是核心词(head)和依存词(dependent)。依存关系可以细分为不同的类型,表示两个词之间的具体句法关系。
新闻列表页识别
1.思路
1. 图像识别
2. Html结构 标签识别
3. 关键字定位
4. url特征提取 分类
2.新闻列表页url识别结果
BFS算法 Breadth First Search
https://www.jianshu.com/p/aecba8d8aca0
BFS算法原理
关系抽取 Relation Extractor
数据唯一性判断
AlphaGo(google) 原理 蒙特卡洛树搜索(MCTS)代码详解
https://blog.csdn.net/cinderella___/article/details/102556309
https://blog.csdn.net/windowsyun/article/details/88770799
https://www.sohu.com/a/226383491_129720

Pytorch
1.介绍
在开始使用PyTorch时应该了解的主要元素:
·PyTorch张量:
张量只是多维数组。PyTorch中的张量类似于numpy的ndarrays,另外,张量也可以在GPU上使用。PyTorch支持各种类型的张量。
·数学运算
·Autograd模块
·Optim模块
·神经网络模块
2.pytorch 实现 n-gram
https://blog.csdn.net/hao5335156/article/details/80623290
文本分类 Text Classification
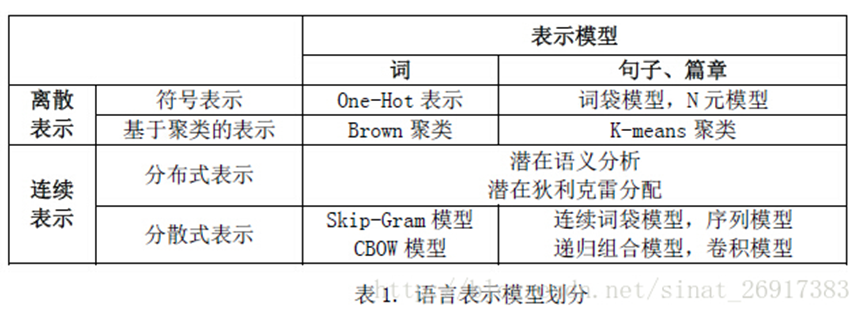
聚类 Cluster
1.Brown Clustering算法 布朗聚类 原理
初始的时候,将每一个词独立的分成一类,然后,将两个类合并,使得合并之后评价函数最大,然后不断重复上述过程,达到想要的类的数量的时候停止合并。
上面提到的评价函数,是对于n个连续的词(w)序列能否组成一句话的概率的对数的归一化结果。于是,得到评价函数
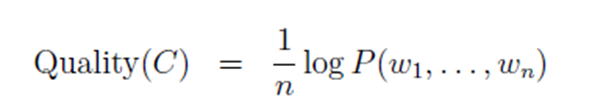
其中:n是文本长度,w是词
2.DBSCAN sklearn
两个重要参数min_samples和 eps
https://www.cnblogs.com/pinard/p/6217852.html
https://www.jianshu.com/p/b004861105f4
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
3.scikit-learn中的DBSCAN类 进一步学习和理解
https://blog.csdn.net/luanpeng825485697/article/details/79443512
在scikit-learn中,DBSCAN算法类为sklearn.cluster.DBSCAN。要熟练的掌握用DBSCAN类来聚类,除了对DBSCAN本身的原理有较深的理解以外,还要对最近邻的思想有一定的理解。集合这两者,就可以玩转DBSCAN了。
KNN临近算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
4.DBSCAN类重要参数
DBSCAN类的重要参数也分为两类,一类是DBSCAN算法本身的参数,一类是最近邻度量的参数,下面我们对这些参数做一个总结。
1)eps: DBSCAN算法参数,即我们的ϵ
-邻域的距离阈值,和样本距离超过ϵ的样本点不在ϵ-邻域内。默认值是0.5.一般需要通过在多组值里面选择一个合适的阈值。eps过大,则更多的点会落在核心对象的ϵ
-邻域,此时我们的类别数可能会减少, 本来不应该是一类的样本也会被划为一类。反之则类别数可能会增大,本来是一类的样本却被划分开。
2)min_samples: DBSCAN算法参数,即样本点要成为核心对象所需要的ϵ
-邻域的样本数阈值。默认值是5. 一般需要通过在多组值里面选择一个合适的阈值。通常和eps一起调参。在eps一定的情况下,min_samples过大,则核心对象会过少,此时簇内部分本来是一类的样本可能会被标为噪音点,类别数也会变多。反之min_samples过小的话,则会产生大量的核心对象,可能会导致类别数过少。
3)metric:最近邻距离度量参数。可以使用的距离度量较多,一般来说DBSCAN使用默认的欧式距离(即p=2的闵可夫斯基距离)就可以满足我们的需求。可以使用的距离度量参数有:
a) 欧式距离 “euclidean”: ∑i=1n(xi−yi)2−−−−−−−−−−√
b) 曼哈顿距离 “manhattan”: ∑i=1n|xi−yi|
c) 切比雪夫距离“chebyshev”: max|xi−yi|(i=1,2,...n)
d) 闵可夫斯基距离 “minkowski”: ∑i=1n(|xi−yi|)p−−−−−−−−−−−√p
p=1为曼哈顿距离, p=2为欧式距离。
e) 带权重闵可夫斯基距离 “wminkowski”: ∑i=1n(w∗|xi−yi|)p−−−−−−−−−−−−−−√p
其中w为特征权重
f) 标准化欧式距离 “seuclidean”: 即对于各特征维度做了归一化以后的欧式距离。此时各样本特征维度的均值为0,方差为1.
g) 马氏距离“mahalanobis”:(x−y)TS−1(x−y)−−−−−−−−−−−−−−−√
其中,S−1
为样本协方差矩阵的逆矩阵。当样本分布独立时, S为单位矩阵,此时马氏距离等同于欧式距离。
还有一些其他不是实数的距离度量,一般在DBSCAN算法用不上,这里也就不列了。
4)algorithm:最近邻搜索算法参数,算法一共有三种,第一种是蛮力实现,第二种是KD树实现,第三种是球树实现。这三种方法在K近邻法(KNN)原理小结中都有讲述,如果不熟悉可以去复习下。对于这个参数,一共有4种可选输入,'brute'对应第一种蛮力实现,'kd_tree'对应第二种KD树实现,'ball_tree'对应第三种的球树实现, 'auto'则会在上面三种算法中做权衡,选择一个拟合最好的最优算法。需要注意的是,如果输入样本特征是稀疏的时候,无论我们选择哪种算法,最后scikit-learn都会去用蛮力实现'brute'。个人的经验,一般情况使用默认的 'auto'就够了。 如果数据量很大或者特征也很多,用"auto"建树时间可能会很长,效率不高,建议选择KD树实现'kd_tree',此时如果发现'kd_tree'速度比较慢或者已经知道样本分布不是很均匀时,可以尝试用'ball_tree'。而如果输入样本是稀疏的,无论你选择哪个算法最后实际运行的都是'brute'。
5)leaf_size:最近邻搜索算法参数,为使用KD树或者球树时, 停止建子树的叶子节点数量的阈值。这个值越小,则生成的KD树或者球树就越大,层数越深,建树时间越长,反之,则生成的KD树或者球树会小,层数较浅,建树时间较短。默认是30. 因为这个值一般只影响算法的运行速度和使用内存大小,因此一般情况下可以不管它。
6) p: 最近邻距离度量参数。只用于闵可夫斯基距离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离, p=2为欧式距离。如果使用默认的欧式距离不需要管这个参数。
以上就是DBSCAN类的主要参数介绍,其实需要调参的就是两个参数eps和min_samples,这两个值的组合对最终的聚类效果有很大的影响。
5.聚类第二次学习 DBSCAN
https://blog.csdn.net/linchuhai/article/details/88526476
6.文本分类和聚类有什么区别
简单点说:分类是将一片文章或文本自动识别出来,按照先验的类别进行匹配,确定。聚类就是将一组的文章或文本信息进行相似性的比较,将比较相似的文章或文本信息归为同一组的技术。分类和聚类都是将相似对象归类的过程。区别是,分类是事先定义好类别,类别数不变。分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴。聚类则没有事先预定的类别,类别数不确定。聚类不需要人工标注和预先训练分类器,类别在聚类过程中自动生成。分类适合类别或分类体系已经确定的场合,比如按照国图分类法分类图书;聚类则适合不存在分类体系、类别数不确定的场合,一般作为某些应用的前端,比如多文档文摘、搜索引擎结果后聚类(元搜索)等。
分类(classification )是找出描述并区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。分类技术在数据挖掘中是一项重要任务,目前商业上应用最多。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个类中。
要构造分类器,需要有一个训练样本数据集作为输入。训练集由一组数据库记录或元组构成,每个元组是一个由有关字段(又称属性或特征)值组成的特征向量,此外,训练样本还有一个类别标记。一个具体样本的形式可表示为:(v1,v2,…,vn; c);其中vi表示字段值,c表示类别。分类器的构造方法有统计方法、机器学习方法、神经网络方法等等。
不同的分类器有不同的特点。有三种分类器评价或比较尺度:1)预测准确度;2)计算复杂度;3)模型描述的简洁度。预测准确度是用得最多的一种比较尺度,特别是对于预测型分类任务。计算复杂度依赖于具体的实现细节和硬件环境,在数据挖掘中,由于操作对象是巨量的数据,因此空间和时间的复杂度问题将是非常重要的一个环节。对于描述型的分类任务,模型描述越简洁越受欢迎。
另外要注意的是,分类的效果一般和数据的特点有关,有的数据噪声大,有的有空缺值,有的分布稀疏,有的字段或属性间相关性强,有的属性是离散的而有的是连续值或混合式的。目前普遍认为不存在某种方法能适合于各种特点的数据
聚类(clustering)是指根据“物以类聚”原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。它的目的是使得属于同一个簇的样本之间应该彼此相似,而不同簇的样本应该足够不相似。与分类规则不同,进行聚类前并不知道将要划分成几个组和什么样的组,也不知道根据哪些空间区分规则来定义组。其目的旨在发现空间实体的属性间的函数关系,挖掘的知识用以属性名为变量的数学方程来表示。聚类技术正在蓬勃发展,涉及范围包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及市场营销等领域,聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题。常见的聚类算法包括:K-均值聚类算法、K-中心点聚类算法、CLARANS、BIRCH、CLIQUE、DBSCAN等。
KNN算法原理

在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:
对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
viterbi (维特比)算法
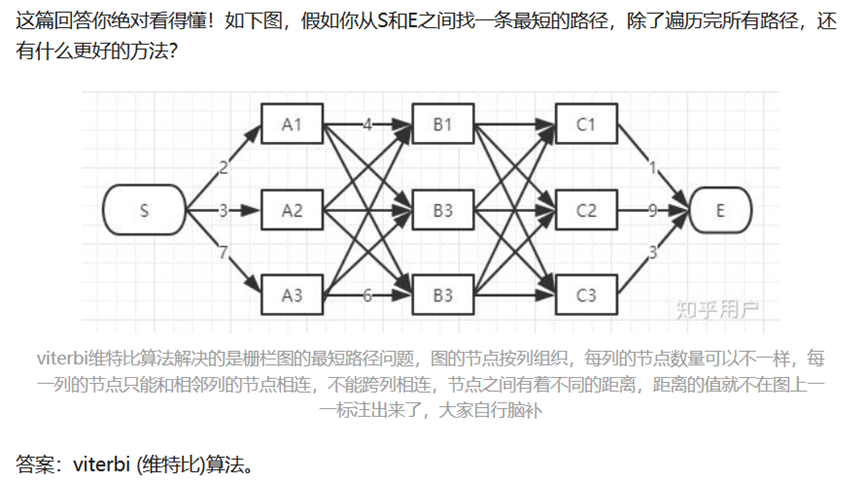
word2vec NLP 文本向量化 [词向量, 句向量]
1.doc2vec训练数据过程
https://blog.csdn.net/weixin_43718084/article/details/90751595
https://blog.csdn.net/mpk_no1/article/details/72510655
https://blog.csdn.net/yangfengling1023/article/details/85169735
2.文本向量化
https://www.jianshu.com/p/1dda2e8b61a5
gensim
1.gensim安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim
from gensim.models.word2vec import Word2Vec
gensim基本使用 Gensim是一个用于从文档中自动提取语义主题的Python库
gensim 是一个通过衡量词组(或更高级结构,如整句或文档)模式来挖掘文档语义结构的工具 三大核心概念:文集(语料)–>向量–>模型
2.gensim中TaggedDocument 怎么使用
https://www.cnblogs.com/blogpro/p/11343819.html
训练结果: 转换成句向量后taggeddocument会给每句话的每个单位加入列表,打上一个数字标签。

n-gram原理
N-Gram是基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关(这也是隐马尔可夫当中的假设)。整个句子出现的概率就等于各个词出现的概率乘积。各个词的概率可以通过语料中统计计算得到。通常N-Gram取自文本或语料库。
N=1时称为unigram,N=2称为bigram,N=3称为trigram,假设下一个词的出现依赖它前面的一个词,即 bigram,假设下一个词的出现依赖它前面的两个词,即 trigram,以此类推。
举例中文:“你今天休假了吗”,它的bigram依次为:
你今,今天,天休,休假,假了,了吗
理论上,n 越大越好,经验上,trigram 用的最多,尽管如此,原则上,能用 bigram 解决,绝不使用 trigram。
假设句子T是有词序列w1,w2,w3…wn组成,用公式表示N-Gram语言模型如下: 1
| P(T)=P(w1)p(w2)p(w3)**p(wn)=p(w1)p(w2 | w1)*p(w3 | w1w2)** *p(wn | w1w2w3…) p(T) 就是语言模型,即用来计算一个句子 T 概率的模型。 |
以上公式难以实际应用。此时出现马尔可夫模型,该模型认为,一个词的出现仅仅依赖于它前面出现的几个词。这就大大简化了上述公式。 1
| P(w1)P(w2 | w1)P(w3 | w1w2)…P(wn | w1w2…wn-1)≈P(w1)P(w2 | w1)P(w3 | w2)…P(wn | wn-1) |
一般常用的N-Gram模型是Bi-Gram和Tri-Gram。分别用公式表示如下: 1 2
| Bi-Gram: P(T)=p(w1 | begin)*p(w2 | w1)*p(w3 | w2)***p(wn | wn-1) |
| Tri-Gram: P(T)=p(w1 | begin1,begin2)*p(w2 | w1,begin1)*p(w3 | w2w1)***p(wn | wn-1,wn-2) |
| 注意上面概率的计算方法:P(w1 | begin)=以w1为开头的所有句子/句 子总数;p(w2 | w1)=w1,w2同时出现的次数/w1出现的次数。以此类推 |
BM25算法
对TF-IDF的改进算法 改进了文本长度对词的影响
作用:优化索引速度
分块统计算法,分块算法
https://www.cnblogs.com/Mychael/p/8330427.html
曲率滤波算法
https://www.cnblogs.com/Imageshop/p/9617419.html
https://github.com/YuanhaoGong/CurvatureFilter
https://blog.csdn.net/jorg_zhao/article/details/51328966
基于知识图谱的语义搜索
软匹配-词向量的匹配
知识图片 把 一个人的相关词语进行 实体化
技术:
Word2vec
Doc2vec 句到向量
Graph2vec 图到向量
过程1:分词
过程2:提取实体
QA Question Answer 问答系统
需要考虑多轮问答 需要考虑上下文 难度比语义搜索更大
图谱是概念和实体的结合
图谱:纯净 且 常更新
p.s 搜索时是【搜索一种模式】,而不是仅仅搜索一种实例
Expert_System 专家系统

卡方检测 chi-square test
训练数据 https://blog.csdn.net/weixin_42608414/article/details/88046380
卡方检验的方法来找出每个分类中关联度最大的两个词语和两个词语对。卡方检验是一种统计学的工具,用来检验数据的拟合度和关联度。在这里我们使用sklearn中的chi2方法。
我的数据挖掘代码问题
1.我的数据挖掘代码问题:
1.1过拟合
过拟合是指为了得到一致假设而使假设变得过度严格。避免过拟合是分类器设计中的一个核心任务。通常采用增大数据量和测试样本集的方法对分类器性能进行评价。
1.2应该加入混乱矩阵
1.3训练数据不够,总共标个300条
1.4加入强匹配提高准确率:1.该句子出现在全文的大概什么位置 2.该句子的长度 3.有没有明显的词语或者英文大小写
拟合率
混乱矩阵 混淆矩阵 confusion matrix
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)
Sklearn
1.Sklearn 保存模型
2.sklearn的详细使用
http://www.17bigdata.com/sklearn入门教程:分类、聚类、回归和降维/
3.两种降维度方法
方法1:
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
iris = load_iris()
X = iris.data
# print(X)
pca = PCA(n_components=2)
reduced_X = pca.fit_transform(X)
print(X.shape) # (150, 4)
print(reduced_X.shape) # (150, 2)
方法2:
待补充
4.将句子转换成特性向量(sklearn)
plt.scatter 各参数详解
https://www.imooc.com/article/29522?block_id=tuijian_wz
测试1:
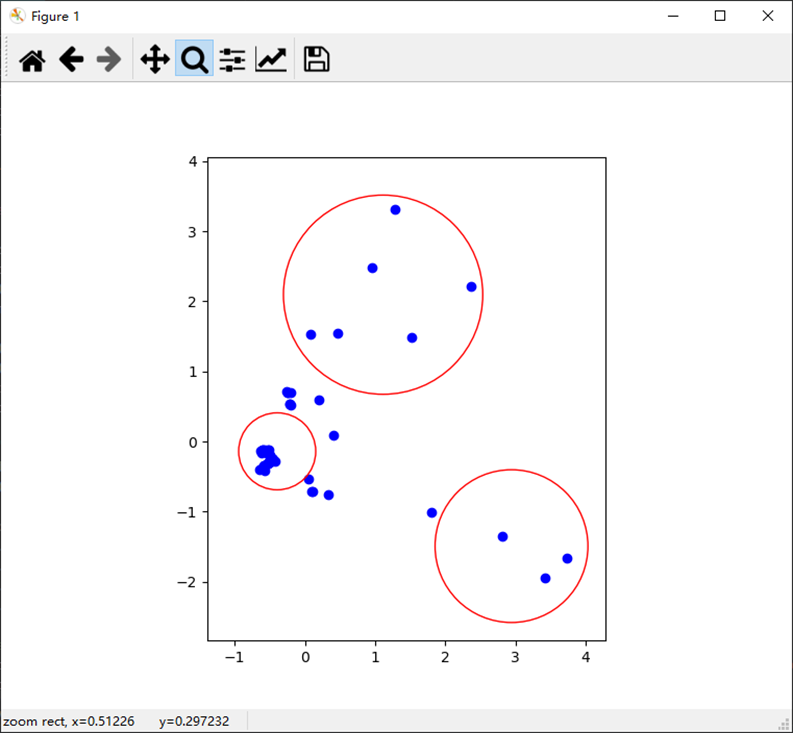
测试2:
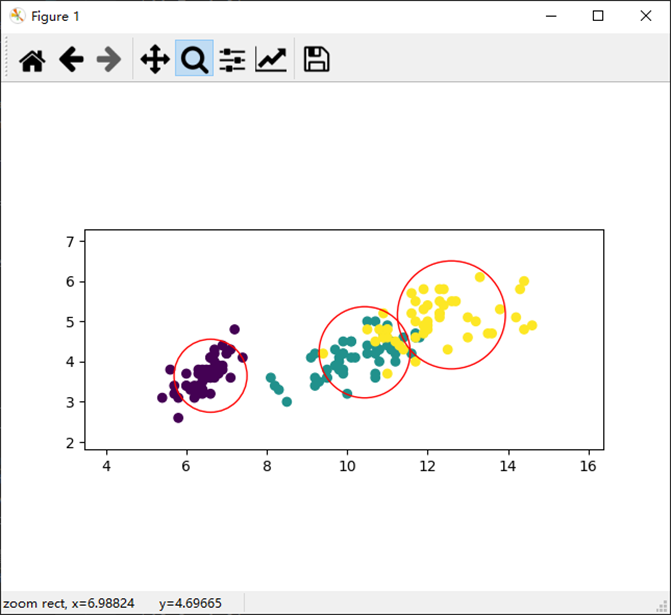
Pandas
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
Weka
https://blog.csdn.net/sinat_23225111/article/details/77983583
1.ARFF 文件格式说明
关系声明
关系名称在ARFF文件的第一个有效行来定义,格式为
@relation <relation-name>
<relation-name>是一个字符串。如果这个字符串包含空格,它必须加上引号(指英文标点的单引号或双引号)。
属性声明
属性声明用一列以“@attribute”开头的语句表示。数据集中的每一个属性都有它对应的“@attribute”语句,来定义它的属性名称和数据类型。
这些声明语句的顺序很重要。首先它表明了该项属性在数据部分的位置。例如,“humidity”是第三个被声明的属性,这说明数据部分那些被逗号分开的列中,第三列数据 85 90 86 96 ... 是相应的“humidity”值。其次, 最后一个声明的属性被称作 class 属性,在分类或回归任务中,它是默认的目标变量。
属性声明的格式为
@attribute <attribute-name> <datatype>
其中<attribute-name>是必须以字母开头的字符串。和关系名称一样,如果这个字符串包含空格,它必须加上引号。
WEKA支持的<datatype>有四种,分别是
numeric-------------------------数值型
<nominal-specification>-----分类(nominal)型
string----------------------------字符串型
date [<date-format>]--------日期和时间型
其中<nominal-specification> 和<date-format> 将在下面说明。还可以使用两个类型“integer”和“real”,但是WEKA把它们都当作“numeric”看待。注意“integer”,“real”,“numeric”,“date”,“string”这些关键字是区分大小写的,而“relation”“attribute ”和“date”则不区分。
数值属性
数值型属性可以是整数或者实数,但WEKA把它们都当作实数看待。
分类属性
分类属性由<nominal-specification>列出一系列可能的类别名称并放在花括号中:{<nominal-name1>, <nominal-name2>, <nominal-name3>, ...} 。数据集中该属性的值只能是其中一种类别。
例如如下的属性声明说明“outlook”属性有三种类别:“sunny”,“ overcast”和“rainy”。而数据集中每个实例对应的“outlook”值必是这三者之一。
@attribute outlook {sunny, overcast, rainy}
如果类别名称带有空格,仍需要将之放入引号中。
字符串属性
字符串属性中可以包含任意的文本。这种类型的属性在文本挖掘中非常有用。
示例:
@ATTRIBUTE LCC string
日期和时间属性
日期和时间属性统一用“date”类型表示,它的格式是
@attribute <name> date [<date-format>]
其中<name>是这个属性的名称,<date-format>是一个字符串,来规定该怎样解析和显示日期或时间的格式,默认的字符串是ISO-8601所给的日期时间组合格式“ yyyy-MM-dd T HH:mm:ss ”。
数据信息部分表达日期的字符串必须符合声明中规定的格式要求(下文有例子)。
数据信息
数据信息中“@data”标记独占一行,剩下的是各个实例的数据。
每个实例占一行。实例的各属性值用逗号“,”隔开。 如果某个属性的值是缺失值( missing value ),用问号 “?” 表示,且这个问号不能省略。例如:
@data
sunny,85,85,FALSE,no
?,78,90,?,yes
字符串属性和分类属性的值是区分大小写的。若值中含有空格,必须被引号括起来。例如:
@relation LCCvsLCSH
@attribute LCC string
@attribute LCSH string
@data
AG5, 'Encyclopedias and dictionaries.;Twentieth century.'
AS262, 'Science -- Soviet Union -- History.'
kenlm 统计语言模型工具
https://github.com/kpu/kenlm
1.kenlm测试
2.训练结果 train result
1g模型和13g模型训练结果
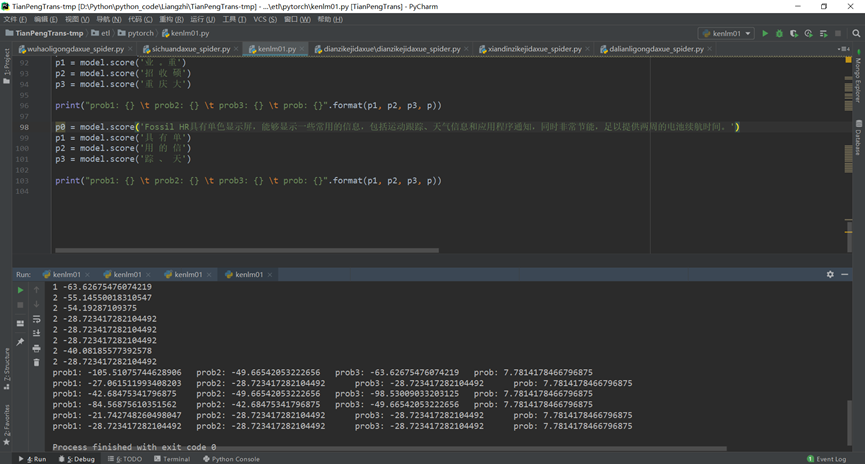
13g模型结果
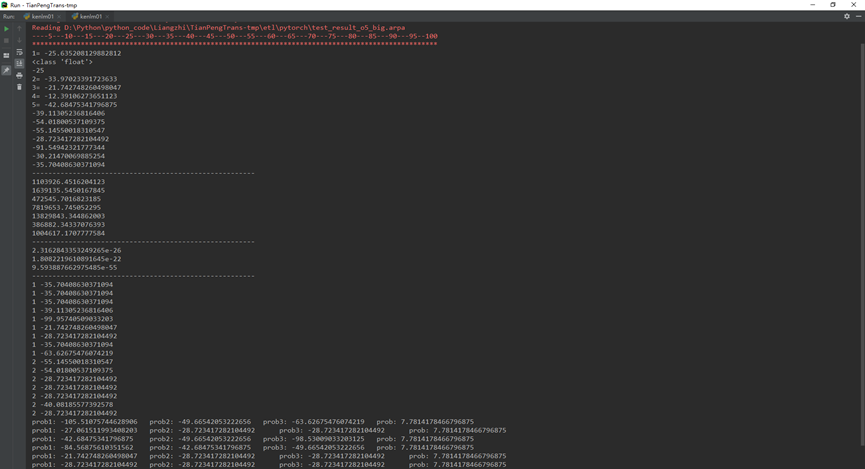
p.s
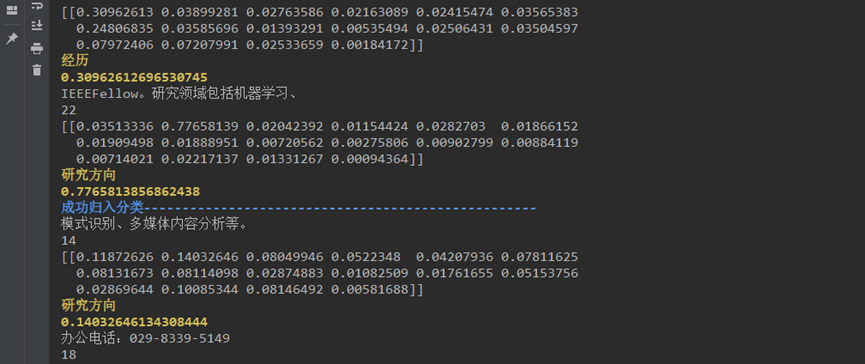
Hanlp [Java]
1.Cosin

2.Java版本的语义距离代码
语义距离
/**
* 演示词向量的训练与应用
*
* @author hankcs
*/
public class DemoWord2Vec
{
public static void main(String[] args) throws IOException
{
WordVectorModel wordVectorModel = trainOrLoadModel();
printNearest("中国", wordVectorModel);
printNearest("美丽", wordVectorModel);
printNearest("购买", wordVectorModel);
// 文档向量
DocVectorModel docVectorModel = new DocVectorModel(wordVectorModel);
String[] documents = new String[]{
"山东苹果丰收",
"农民在江苏种水稻",
"奥运会女排夺冠",
"世界锦标赛胜出",
"中国足球失败",
};
System.out.println(docVectorModel.similarity(documents[0], documents[1]));
System.out.println(docVectorModel.similarity(documents[0], documents[4]));
for (int i = 0; i < documents.length; i++)
{
docVectorModel.addDocument(i, documents[i]);
}
printNearestDocument("体育", documents, docVectorModel);
printNearestDocument("农业", documents, docVectorModel);
printNearestDocument("我要看比赛", documents, docVectorModel);
printNearestDocument("要不做饭吧", documents, docVectorModel);
}
}
3.共性分析
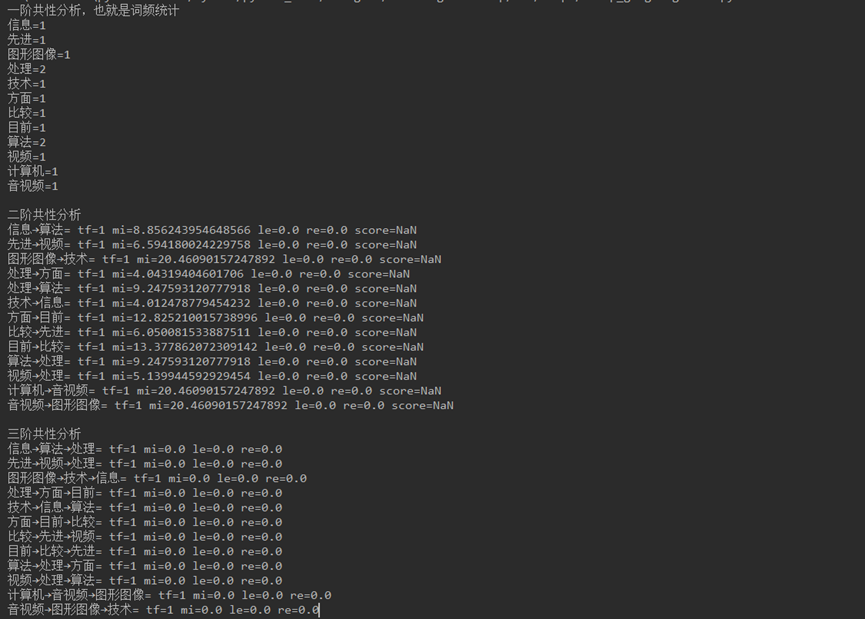
4.短语提取

Allennlp
https://zhuanlan.zhihu.com/p/48070968
自动拼接网址 urllib.parse 中 urllib.parse.urljoin()用法
1.使用
https://blog.csdn.net/mycms5/article/details/76902041?tdsourcetag=s_pcqq_aiomsg
>>>from urllib.parse import urljoin
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "anotherpage.html")
'http://www.chachabei.com/folder/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/anotherpage.html")
'http://www.chachabei.com/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "folder2/anotherpage.html")
'http://www.chachabei.com/folder/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "/folder2/anotherpage.html")
'http://www.chachabei.com/folder2/anotherpage.html'
>>> urljoin("http://www.chachabei.com/abc/folder/currentpage.html", "../anotherpage.html")
'http://www.chachabei.com/abc/anotherpage.html'
2.完整代码:
from urllib.parse import urljoin
from urllib import parse
from urllib.parse import urlunparse
from posixpath import normpath
# TODO 拼接新闻详情页的链接
def url_pinjie(url, the_shortest_url):
url1 = urljoin(url, the_shortest_url)
arr = parse.urlparse(url1)
path = normpath(arr[2])
return urlunparse((arr.scheme, arr.netloc, path, arr.params, arr.query, arr.fragment))
url = ''
the_shortest_url = ''
print(url_pinjie(url, the_shortest_url))
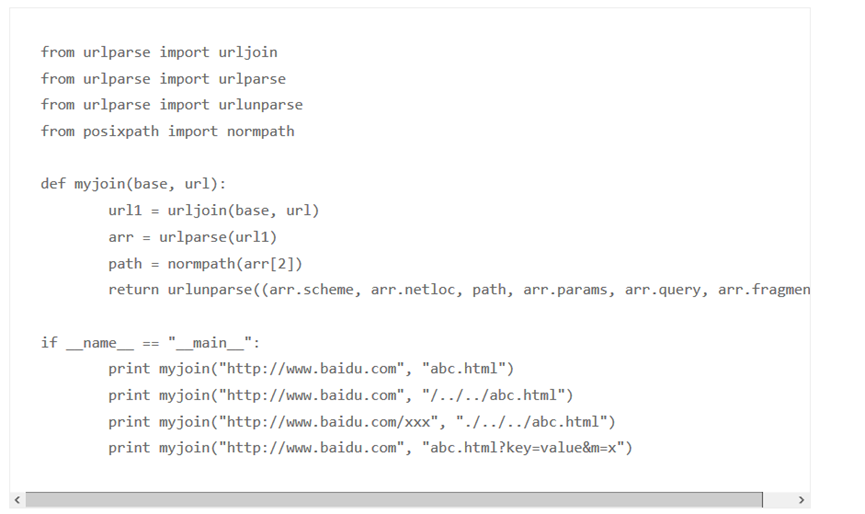
3.urllib拼接原理
https://www.cnblogs.com/-wenli/p/10894562.html

源代码:
def urljoin(base, url, allow_fragments=True):
"""Join a base URL and a possibly relative URL to form an absolute
interpretation of the latter."""
if not base:
return url
if not url:
return base
base, url, _coerce_result = _coerce_args(base, url)
bscheme, bnetloc, bpath, bparams, bquery, bfragment = \
urlparse(base, '', allow_fragments)
scheme, netloc, path, params, query, fragment = \
urlparse(url, bscheme, allow_fragments)
if scheme != bscheme or scheme not in uses_relative:
return _coerce_result(url)
if scheme in uses_netloc:
if netloc:
return _coerce_result(urlunparse((scheme, netloc, path,
params, query, fragment)))
netloc = bnetloc
if not path and not params:
path = bpath
params = bparams
if not query:
query = bquery
return _coerce_result(urlunparse((scheme, netloc, path, params, query, fragment)))
base_parts = bpath.split('/')
if base_parts[-1] != '':
# the last item is not a directory, so will not be taken into account
# in resolving the relative path
del base_parts[-1]
# for rfc3986, ignore all base path should the first character be root.
if path[:1] == '/':
segments = path.split('/')
else:
segments = base_parts + path.split('/')
# filter out elements that would cause redundant slashes on re-joining
# the resolved_path
segments[1:-1] = filter(None, segments[1:-1])
resolved_path = []
for seg in segments:
if seg == '..':
try:
resolved_path.pop()
except IndexError:
# ignore any .. segments that would otherwise cause an IndexError
# when popped from resolved_path if resolving for rfc3986
pass
elif seg == '.':
continue
else:
resolved_path.append(seg)
if segments[-1] in ('.', '..'):
# do some post-processing here. if the last segment was a relative dir,
# then we need to append the trailing '/'
resolved_path.append('')
return _coerce_result(urlunparse((scheme, netloc, '/'.join(
resolved_path) or '/', params, query, fragment)))
磁力链接原理
https://blog.csdn.net/verygoodo/article/details/101025542
需要用的的库
磁力链接由一组参数组成,参数间的顺序没有讲究,其格式与在HTTP链接末尾的查询字符串相同。通常是一个特定文件的内容散列函数值形成的URN,例如:
magnet:?xt=urn:btih:4D9FA761D69964B00DF0B3B0C9C1F968EA6C47D0&xt=urn:ed2k:7655dbacff9395e579c4c9cb49cbec0e&dn=bbb_sunflower_2160p_30fps_stereo_abl.mp4&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2ftracker.publicbt.com%3a80%2fannounce&ws=http%3a%2f%2fdistribution.bbb3d.renderfarming.net%2fvideo%2fmp4%2fbbb_sunflower_2160p_30fps_stereo_abl.mp4
虽然这个链接指向一个特定文件,但是客户端应用程序仍然必须进行搜索来确定哪里。
在标准的草稿中其他参数的定义如下:
magnet:协议名。
xt:exact topic的缩写,包含文件哈希值的统一资源名称。BTIH(BitTorrent Info Hash)表示哈希方法名,这里还可以使用ED2K,AICH,SHA1和MD5等。这个值是文件的标识符,是不可缺少的。
dn:display name的缩写,表示向用户显示的文件名。这一项是选填的。
tr:tracker的缩写,表示tracker服务器的地址。这一项也是选填的。
ws:webseed的缩写,表示网络种子。
urn:(Uniform Resource Name, URN 表示资源名
btih:BitTorrent info hash,种子散列函数
应用程序定义的实验参数,必须以"x."开头。
标准还建议同类的多个参数可以在参数名称后面加上".1", ".2"等来使用,例如:
magnet:?xt.1=urn:sha1:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C&xt.2=urn:sha1:TXGCZQTH26NL6OUQAJJPFALHG2LTGBC7
搜索引擎工作原理 Search Engines
搜索引擎,通常指的是收集了万维网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,建立索引数据库的全文搜索引擎。当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。再经过复杂的算法进行排序(或者包含商业化的竞价排名、商业推广或者广告)后,这些结果将按照与搜索关键词的相关度高低(或与相关度毫无关系),依次排列。
中文名 搜索引擎原理
外文名 Principle of Search Engine
工作原理 爬行和抓取、建立索引等
数据结构 倒排索引
OCR 图像识别————————————————————-
OCR图像文字识别
1.新闻图片文字提取 python opencv3 区域改进
https://blog.csdn.net/yangzm/article/details/81120308
# coding:utf8
import sys
import cv2
import numpy as np
import matplotlib.pyplot as plt
def preprocess(gray):
# 1. Sobel算子,x方向求梯度
sobel = cv2.Sobel(gray, cv2.CV_8U, 1, 0, ksize = 3)
# 2. 二值化
ret, binary = cv2.threshold(sobel, 0, 255, cv2.THRESH_OTSU+cv2.THRESH_BINARY)
# 3. 膨胀和腐蚀操作的核函数
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 9))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (24, 6))
# 4. 膨胀一次,让轮廓突出
dilation = cv2.dilate(binary, element2, iterations = 1)
# 5. 腐蚀一次,去掉细节,如表格线等。注意这里去掉的是竖直的线
erosion = cv2.erode(dilation, element1, iterations = 1)
# 6. 再次膨胀,让轮廓明显一些
dilation2 = cv2.dilate(erosion, element2, iterations = 2)
# 7. 存储中间图片
#cv2.imwrite("binary.png", binary)
#cv2.imwrite("dilation.png", dilation)
#cv2.imwrite("erosion.png", erosion)
#cv2.imwrite("dilation2.png", dilation2)
return dilation2
def findTextRegion( org, img ):
region = []
# 1. 查找轮廓
_,contours,hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
maxArea = 0
maxContour = 0
for i in range(len(contours)):
cnt = contours[i]
# 计算该轮廓的面积
area = cv2.contourArea(cnt)
if area > maxArea:
maxArea = area
maxContour = cnt
maxRect = cv2.boundingRect(maxContour);
x, y, w, h = cv2.boundingRect(maxContour)
cv2.rectangle(org, (x, y), (x + w, y + h), (255, 255, 0), 2)
#cv2.imshow("img", org)
#cv2.waitKey(0)
return x,y,w,h
def detect(img):
# 1. 转化成灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2. 形态学变换的预处理,得到可以查找矩形的图片
dilation = preprocess(gray)
# 3. 查找和筛选文字区域
x,y,w,h = findTextRegion(gray,dilation)
cropImg = gray[y:y + h, x:x + w]
cv2.imshow("img", cropImg)
cv2.waitKey(0)
if __name__ == '__main__':
# 读取文件
imagePath = "/tmp/mypic/59.png" #sys.argv[1]
img = cv2.imread(imagePath)
detect(img)
图像超分辨率算法 FALSR
https://blog.csdn.net/imwaters/article/details/93997296
Canny边缘提取算法手动实现 Python
https://blog.csdn.net/Ibelievesunshine/article/details/104996058

百度ocr api接口
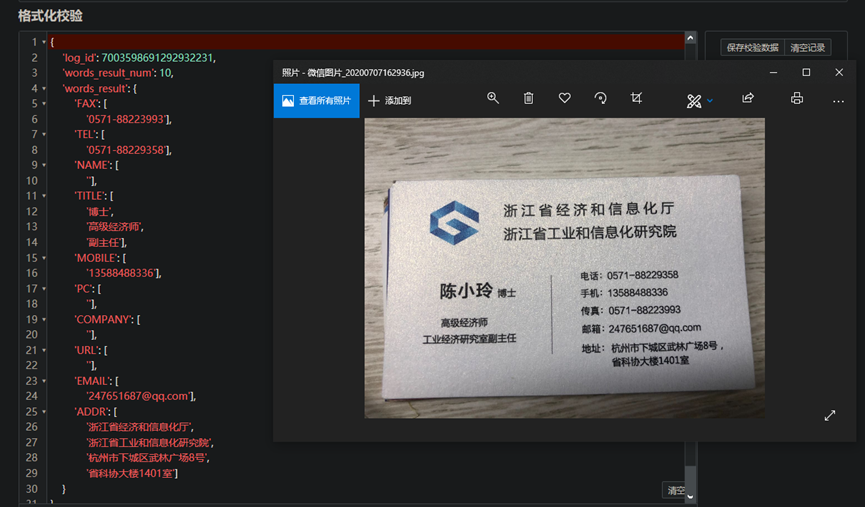
阿里云OCR 图像识别接口
1.oss_url 就是 oss临时授权的url
生成临时授权的URL,第三方可以用这个URL进行上传操作
2.依赖包 导入包
pip install oss2
pip install aliyun-python-sdk-viapiutils
pip install aliyun-python-sdk-core
pip install viapi-utils
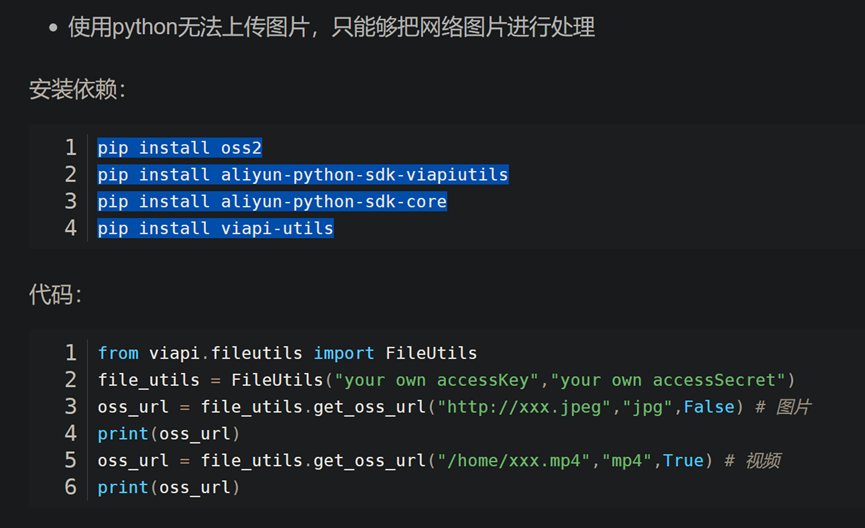
camelot 使用记录
pip camelot-py
Ghostscript 的安装
Ghostscript Downloads
https://www.ghostscript.com/download/gsdnld.html
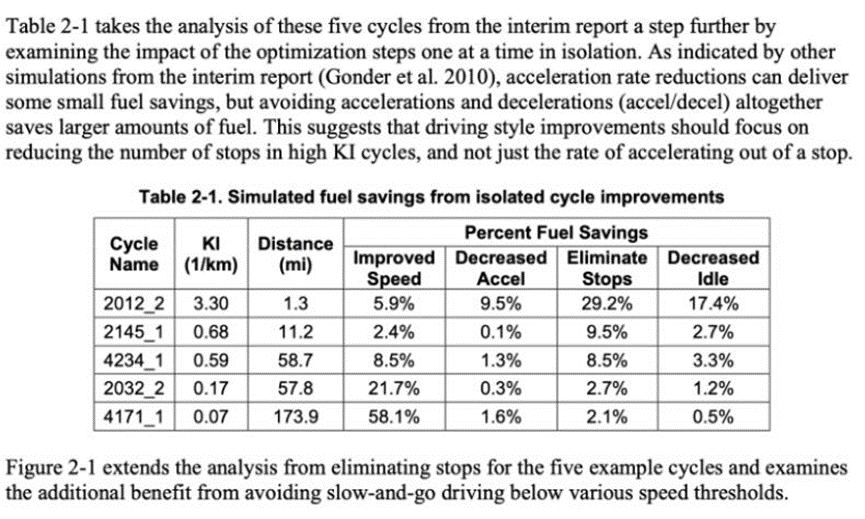
处理后:
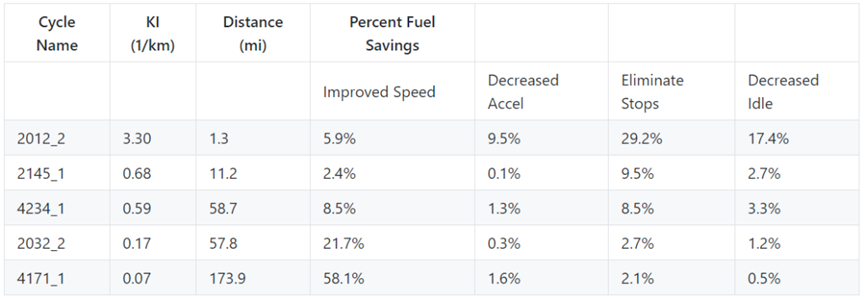
Python生成二维码 加上logo图片
https://www.cnblogs.com/babycool/p/4734819.html
'''
date: 2020-11-09
description: 1.Python生成二维码 v1.0
2.主要将文本生成二维码图片
3.测试一:将文本生成白底黑字的二维码图片
4.测试二:将文本生成带logo的二维码图片
'''
import qrcode
from PIL import Image
import os
# 生成二维码图片
def make_qr(str, save):
qr = qrcode.QRCode(
version=4, # 生成二维码尺寸的大小 1-40 1:21*21(21+(n-1)*4)
error_correction=qrcode.constants.ERROR_CORRECT_M, # L:7% M:15% Q:25% H:30%
box_size=10, # 每个格子的像素大小
border=2, # 边框的格子宽度大小
)
qr.add_data(str)
qr.make(fit=True)
img = qr.make_image()
img.save(save)
# 生成带logo的二维码图片
def make_logo_qr(str, logo, save):
# 参数配置
qr = qrcode.QRCode(
version=4,
error_correction=qrcode.constants.ERROR_CORRECT_Q,
box_size=8,
border=2
)
# 添加转换内容
qr.add_data(str)
#
qr.make(fit=True)
# 生成二维码
img = qr.make_image()
#
img = img.convert("RGBA")
# 添加logo
if logo and os.path.exists(logo):
icon = Image.open(logo)
# 获取二维码图片的大小
img_w, img_h = img.size
factor = 4
size_w = int(img_w / factor)
size_h = int(img_h / factor)
# logo图片的大小不能超过二维码图片的1/4
icon_w, icon_h = icon.size
if icon_w > size_w:
icon_w = size_w
if icon_h > size_h:
icon_h = size_h
icon = icon.resize((icon_w, icon_h), Image.ANTIALIAS)
# 详见:http://pillow.readthedocs.org/handbook/tutorial.html
# 计算logo在二维码图中的位置
w = int((img_w - icon_w) / 2)
h = int((img_h - icon_h) / 2)
icon = icon.convert("RGBA")
img.paste(icon, (w, h), icon)
# 详见:http://pillow.readthedocs.org/reference/Image.html#PIL.Image.Image.paste
# 保存处理后图片
img.save(save)
if __name__ == '__main__':
save_path = 'theqrcode.png' # 生成后的保存文件
logo = 'logo_test.jpg' # logo图片
str = input('请输入要生成二维码的文本内容:')
# make_qr(str)
make_logo_qr(str, logo, save_path)
YOLOv3
1.darknet 文件夹 编译
https://blog.csdn.net/demm868/article/details/104058078?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
https://github.com/chineseocr/table-ocr
https://github.com/tommyMessi/tableImageParser_tx
https://blog.csdn.net/ghw15221836342/article/details/86551316
编译出现 make (e=2): 系统找不到指定的文件 之前一段时间还使用的没问题,突然就出异常了,研究发现是安装了 git仓库之后出的问题,卸载git 仓库,问题解决,编译通过
2.Cygwin和MinGW 有什么区别

模式识别
简单点说,模式识别是根据输入的原始数据对齐进行各种分析判断,从而得到其类别属性,特征判断的过程。为了具备这种能力,人类在过去的几千万年里,通过对大量事物的认知和理解,逐步进化出了高度复杂的神经和认知系统。举例来说,我们能够轻易的判别出哪个是钥匙、哪个是锁,哪个是自行车、哪个是摩托车;而这些看似简单的过程,其背后实际上隐藏着非常复杂的处理机制。而弄清楚这些机制的作用机理正是模式识别的基本任务。
那么,到底什么是模式呢?广义地说,模式是存在于时间和空间中的可观察的事物,如果我们可以区别它们是否相同或者是否相似,那我们从这种事物所获取的信息就可以称之为模式。人们为了掌握客观的事物,往往会按照事物的相似程度组成类别,而模式识别的作用和目的就在于把某一个具体的事物正确的归入某一个类别。

视觉显著性检测 Visual Saliency Detection
https://baike.baidu.com/item/%E8%A7%86%E8%A7%89%E6%98%BE%E8%91%97%E6%80%A7%E6%A3%80%E6%B5%8B/22761214?fr=aladdin
1.概念
视觉显著性检测(Visual Saliency Detection)指通过智能算法模拟人的视觉特点,提取图像中的显著区域(即人类感兴趣的区域)。
2.Itti模型
Itti于1998年提出基于显著性的视觉注意模型,并在2001年度Nature上对该模型理论作了进一步的完善。Itti的显著性模型最具代表性,该模型已经成为了自下而上视觉注意模型的标准。
Itti模型:
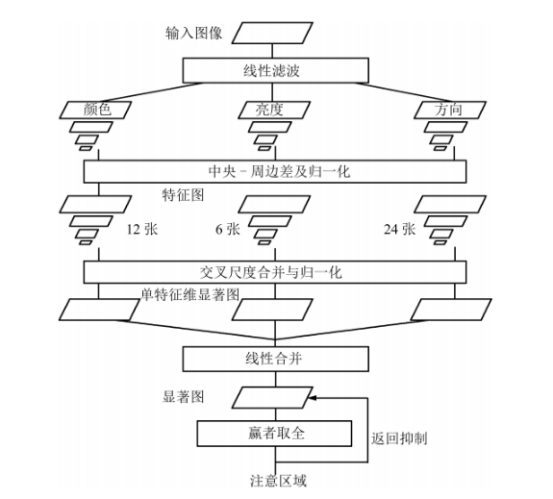
对于一幅输入的图像,该模型提取初级视觉特征:颜色(RGBY)、亮度和方位、在多种尺度下使用中央周边(Center-surround)操作产生体现显著性度量的特征图,将这些特征图合并得到最终的显著图(Saliency map)后,利用生物学中赢者取全(Winner-take-all)的竞争机制得到图像中最显著的空间位置, 用来向导注意位置的选取,最后采用返回抑制 (Inhibition of return) 的方法来完成注意焦点的转移。视觉显著性计算模型大致上可分为两个阶段:特征提取与特征融合。在特征融合阶段,可能存在自底向上的底层特征驱动的融合方式,和自顶向下的基于先验信息与任务的融合方式。因此,视觉显著性检测模型框架大致表述为如图 5 所示。
3.视觉显著性检测算法
深度合成
1.概念
图像带有深度空间的信息,解决了空间穿插的问题
2.应用领域
深度合成云彩
Window 相关操作
1.windows重要快捷键
win + v 快速打开剪切板
2.windows文件命名规则 文件路径名字最大值
在Windows系统中,文件名命名规则如下:
1)文件名最长可以使用255个字符;
2)可以使用扩展名,扩展名用来表示文件类型,也可以使用多间隔符的扩展名(如win.ini.txt是一个合法的文件名,但其文件类型由最后一个扩展名决定);
3)文件名中允许使用空格,但不允许使用下列字符(英文输入法状态):< > / \ | : " * ?;
4)windows系统对文件名中字母的大小写在显示时有不同,但在使用时不区分大小写。
文件名长度最大为255个英文百字符,其中包括文件扩展名在内。一个汉字相当于两个英文字符。
文件的全路径名长度最大为260个英文字符,包含扩展名在内。如路径为C:\Program Files\filename.txt,那么这28个字符都包含在此字符数值中。一个汉字相当于两个权英文字符。
3.由于系统缓冲区空间不足或队列已满,不能执行套接字上的操作
https://blog.csdn.net/susubuhui/article/details/52945568
解决方法:
修改两个注册表:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters\MaxUserPort 如果没有,则手动创建 DWord(32位) ”数值数据“改为十进制65534 或者认为适当的值。
此值表示 用户最大使用的端口数量,默认为5000。
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters\TCPTimedWaitDelay 如果没有,则手动创建 DWord(32位) ”数值数据“改为十进制30 或者你认为适当的值。
此值表示一个关闭后的端口等待多久之后可以重新使用,默认为120秒,也就是2分钟才可以重新使用。
4.windows 出现无法刷新,卡住时候 可以刷新资源管理器 在任务管理器中
5.你的设备中缺少重要更新 图标关闭
图标是这个应用程序
C:\Windows\System32\MusNotifyIcon.exe
1复制 - 副本.exe
2使用360粉碎机 强制删除 勾选防止恢复
3终止该进程 exe

6.win10系统你要来自Trustedinstaller的权限才能对此文件进行更改 问题
文件或文件夹权限修改

教师数据的抓取和分类项目 总结
1.过程以及分析反思
由于教师数据的抓取网页标签是不同的,教师个人书写格式也各有不同,所以用了很多种方法尝试,有试过聚类(1.聚类一:kmeans聚类2.聚类二:dbscan聚类),tdidf词频分类,句向量文本模型训练(降维),断句和零碎句子拼接kenlm模型,硬匹配等。都有一些缺陷,有空进一步研究下。各种方法尝试后的我的感觉如下:
1. kmeans聚类需要事先设定有集中分类,当教师每个人写的种类和数量不确定,不适用。
2. dbscan聚类可以自动进行聚类,不需要事先设定好聚类的数量。但是没有大量规整的教师字段数据,所以训练了80万的人工智能新闻的向量模型。但是跑起来的聚类效果不好。可能有大量可用的成熟数据的话效果会好些。用了降维也可能导致数据准确性的丢失。具体原因不明。
3. tidif词频的的准确率60%左右但召回率低。根据词频进行分类的话对分类的精准性有限制,这里有个分支问题,而且比较重要的问题,就是关键词提取不准确。
4. 句向量相对tidif和词向量来讲准确性有所提升,但是有两个问题:一是每个分类需要大量语料,教师数据的分类没有可用的语料和数据。二是对于短句的判断准确性不是很高。
5. 把断开的句子进行拼接,或者断开的文本进行拼接。这个问题在各种教师,专家网站大量存在。数据格式不统一,抓取下来的数据可能是零碎的。不是完整的句子。用了kenlm模型进行拼接,kenlm的环境配置比较复杂。由于kenlm是通过概率来进行拼接句子,也是用来大量的人工智能新闻数据进行模型训练。但是不管是3个词距还是5个词距,训练出来的模型跑起来的结果都不太好。还有个问题是模型非常大,5个词句模型就将近20g。在观察通过语料训练出来的模型的时候,模型似乎没有遍历每一种情况,既每个词出现的每种情况。这个问题我还不太确定。也有可能用新闻训练出来的模型用于新闻拼接效果会好些。
6. 硬匹配。单纯地用硬匹配效果不太好。情况种类太多。不过在模型分析和代码处理后的数据加上一些硬匹配的规则会有较好的效果。
然后根据网页自身的标签进行分类识别取得比较理想的效果。相对适合用于展示。
不同学校的网站的识别率不同,这里放了一个我抓取的结果的样本。其他学校、专家的抓取和分类结果类似。网站自身或教师个人的数据多,抓取和分类后的数据就多。
2.抓取以及分类结果
会有小部分的教师会损失掉,但是他的主要信息都是有的,例如姓名,学校,邮箱,电话。识别出来的的网页,可以抓取全部信息的95%-100%。这里进行里同类型的信息合并,所以多个板块都在协同一个内容,会自动进行合并。这里就把这个人的写教育经历的3条和工作经历的4条经历都合并成个人经历字段,总共七条。所以有出现重复在写一个板块的内容的时候会自动进行合并。
会按照网站上教师或专家个人书写的种类进行分类。如果教师自己就把分类写错了,那抓取和分类后的数据也会依照教师的分类进行分类,这种情况很少,基本可以忽略。
网站样例如下:

抓取和数据自动分类后的结果如下(这张是缩略图):
展开图如下:
图1
图2
总体来讲已经较理想了。
专利报告 标签提取 标签分类体系


专利关键词抽取【第一二层是由算法抽出来的,第三四层有人工干预】 的属性 用处 基于什么领域 理论 特点 等进行打标签,涉及多少个技术集群,
专利标签分类
专利去重
专利分类 企业分类
通用企业新闻自动采集代码思路
1.主页找到新闻列表页链接
2.判断是否是新闻列表页,判断是否是新闻详情页
Programming Notes End
Markdown
For more details see GitHub Flavored Markdown.
Jekyll Themes
Your Pages site will use the layout and styles from the Jekyll theme you have selected in your repository settings. The name of this theme is saved in the Jekyll _config.yml configuration file.